Python爬取数据并实现可视化代码解析
这次主要是爬了京东上一双鞋的相关评论:将数据保存到excel中并可视化展示相应的信息
主要的python代码如下:
文件1
#将excel中的数据进行读取分析
import openpyxl
import matplotlib.pyplot as pit #数据统计用的
wk=openpyxl.load_workbook('销售数据.xlsx')
sheet=wk.active #获取活动表
#获取最大行数和最大列数
rows=sheet.max_row
cols=sheet.max_column
lst=[] #用于存储鞋子码数
for i in range (2,rows+1):
size=sheet.cell(i,3).value
lst.append(size)
#以上已经将excel中的数据读取完毕
#一下操作就你行统计不同码数的数量
'''python中有一个数据结构叫做字典,使用鞋码做key,使用销售数量做value'''
dic_size={}
for item in lst:
dic_size[item]=0
for item in lst:
for size in dic_size:
#遍历字典
if item==size:
dic_size[size]+=1
break
for item in dic_size:
print(item,dic_size[item])
#弄成百分比的形式
lst_total=[]
for item in dic_size:
lst_total.append([item,dic_size[item],dic_size[item]/160*1.0])
#接下来进行数据的可视化(进行画饼操作)
labels=[item[0] +'码'for item in lst_total] #使用列表生成式,得到饼图的标签
fraces=[item[2] for item in lst_total] #饼图中的数据源
pit.rcParams['font.family']=['SimHei'] #单独的表格乱码的处理方式
pit.pie(x=fraces,labels=labels,autopct='%1.1f%%')
#pit.show()进行结果的图片的展示
pit.savefig('图.jpg')
文件2
#所涉及到的是requests和openpyxl数据的存储和数据的清洗以及统计然后就是matplotlib进行数据的可视化
#静态数据点击element中点击发现在html中,服务器已经渲染好的内容,直接发给浏览器,浏览器解释执行,
#动态数据:如果点击下一页。我们的地址栏(加后缀但是前面的地址栏没变也算)(也可以点击2和3页)没有发生任何变化说明是动态数据,说明我们的数据是后来被渲染到html中的。他的数据根本不在html中的。
#动态查看network然后用的url是network里面的headers
#安装第三方模块输入cmd之后pip install 加名字例如requests
import requests
import re
import time
import json
import openpyxl #用于操作 excel文件的
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息
def get_comments(productId,page):
url = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1".format(productId,page)
resp = requests.get(url, headers=headers)
s=resp.text.replace('fetchJSON_comment98(','')#进行替换操作。获取到所需要的相应的json,也就是去掉前后没用的东西
s=s.replace(');','')
json_data=json.loads(s)#进行数据json转换
return json_data
#获取最大页数
def get_max_page(productId):
dis_data=get_comments(productId,0)#调用刚才写的函数进行向服务器的访问请求,获取字典数据
return dis_data['maxPage']#获取他的最大页数。每一页都有最大页数
#进行数据提取
def get_info(productId):
max_page=get_max_page(productId)
lst=[]#用于存储提取到的商品数据
for page in range(1,max_page+1):
#获取没页的商品评论
comments=get_comments(productId,page)
comm_list=comments['comments']#根据comnents获取到评论的列表(每页有10条评论)
#遍历评论列表,获取其中的相应的数据
for item in comm_list:
#每条评论分别是一字典。在继续通过key来获取值
content=item['content']
color=item['productColor']
size=item['productSize']
lst.append([content,color,size])#将每条评论添加到列表当中
time.sleep(3)#防止被京东封ip进行一个时间延迟。防止访问次数太频繁
save(lst)
def save(lst):
#把爬取到的数据进行存储,保存到excel中
wk=openpyxl.Workbook()#用于创建工作簿对象
sheet=wk.active #获取活动表(一个工作簿有三个表)
#遍历列表将数据添加到excel中。列表中的一条数据在表中是一行
biaotou='评论','颜色','大小'
sheet.append(biaotou)
for item in lst:
sheet.append(item)
#将excel保存到磁盘上
wk.save('销售数据.xlsx')
if __name__=='__main__':
productId='66749071789'
get_info(productId)
print("ok")
实现的效果如下:
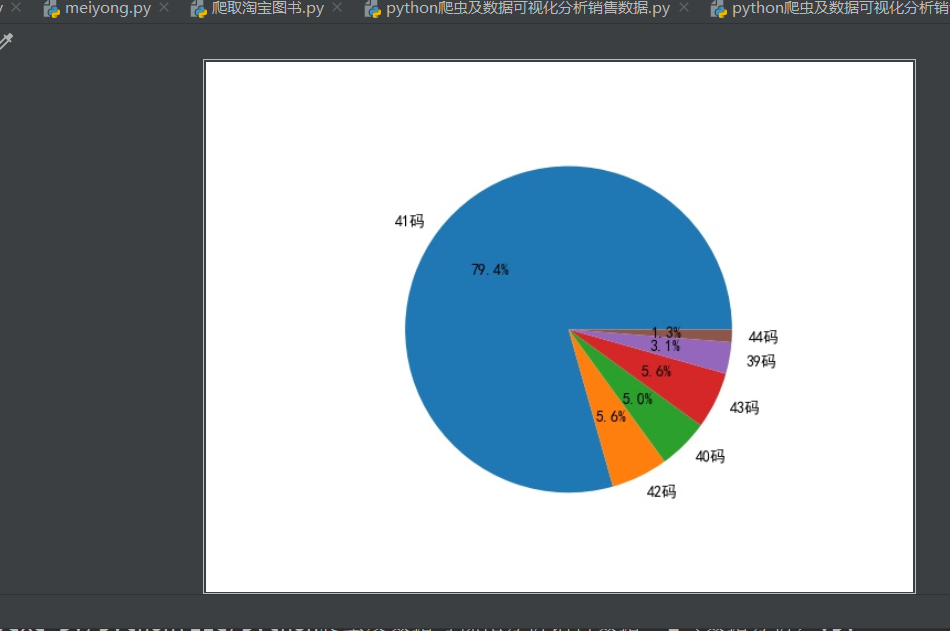

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python数据可视化:饼状图的实例讲解
使用python实现论文里面的饼状图: 原图: python代码实现: # # 饼状图 # plot.figure(figsize=(8,8)) labels = [u'Canteen', u'Supermarket', u'Dorm', u'Others'] sizes = [73, 21, 4, 2] colors = ['red', 'yellow', 'blue', 'green'] explode = (0.05, 0, 0, 0) patches, l_text, p_text =
-

Python数据可视化处理库PyEcharts柱状图,饼图,线性图,词云图常用实例详解
python可以在处理各种数据时,如果可以将这些数据,利用图表将其可视化,这样在分析处理起来,将更加直观.清晰,以下是 利用 PyEcharts 常用图表的可视化Demo, 开发环境 python3 柱状图 基本柱状图 from pyecharts import Bar # 基本柱状图 bar = Bar("基本柱状图", "副标题") bar.use_theme('dark') # 暗黑色主题 bar.add('真实成本', # label ["1月&q
-
Python3.x+pyqtgraph实现数据可视化教程
1.pyqtgraph库数据可视化效果还不错,特别是窗体程序中图像交互性较好:安装也很方便,用 pip 安装. 2.在Python中新建一个 .py 文件,然后写入如下代码并执行可以得到官方提供的很多案例(含代码),出现如下界面图像: import pyqtgraph.examples pyqtgraph.examples.run() 图1 图2 图3 4.程序默认是黑色背景,这个是可以修改的.比如,在程序的开头部分写入如下代码就可以修改背景: pg.setConfigOption('backg
-
python使用pyecharts库画地图数据可视化的实现
python使用pyecharts库画地图数据可视化导库中国地图代码结果世界地图代码结果省级地图代码结果地级市地图代码结果 导库 from pyecharts import options as opts from pyecharts.charts import Map 中国地图 代码 data = [('湖北', 9074),('浙江', 661),('广东', 632),('河南', 493),('湖南', 463), ('安徽', 340),('江西', 333),('重庆', 275),
-
Python数据可视化 pyecharts实现各种统计图表过程详解
1.pyecharts介绍 Echarts是一款由百度公司开发的开源数据可视化JS库,pyecharts是一款使用python调用echarts生成数据可视化的类库,可实现柱状图,折线图,饼状图,地图等统计图表. 2.柱状图 适用场合是二维数据集(每个数据点包括两个值x和y),但只有一个维度需要比较,用于显示一段时间内的数据变化或显示各项之间的比较情况. 优点: 利用柱子的高度,反映数据的差异,肉眼对高度差异很敏感. 缺点: 只适用中小规模的数据集. 柱状图最基本用法 from pyechart
-
python代码实现TSNE降维数据可视化教程
TSNE降维 降维就是用2维或3维表示多维数据(彼此具有相关性的多个特征数据)的技术,利用降维算法,可以显式地表现数据.(t-SNE)t分布随机邻域嵌入 是一种用于探索高维数据的非线性降维算法.它将多维数据映射到适合于人类观察的两个或多个维度. python代码 km.py #k_mean算法 import pandas as pd import csv import pandas as pd import numpy as np #参数初始化 inputfile = 'x.xlsx' #销量及
-
解决Python数据可视化中文部分显示方块问题
一.问题 代码如下,发现标题的中文显示的是方块 import matplotlib import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(111) ax.set(xlim=[1.5, 6.5], ylim=[-4, 5], title='画图小例子',ylabel='yvalue', xlabel='xvalue') plt.show() 如下图 二.解决方法 一般数据可视化使用matplotlib库,设置
-
Python数据可视化图实现过程详解
python画分布图代码示例: # encoding=utf-8 import matplotlib.pyplot as plt from pylab import * # 支持中文 mpl.rcParams['font.sans-serif'] = ['SimHei'] # 'mentioned0cluster', names = ['mentioned1cluster','mentioned2cluster', 'mentioned3cluster', 'mentioned4cluster'
-
Python爬取数据并实现可视化代码解析
这次主要是爬了京东上一双鞋的相关评论:将数据保存到excel中并可视化展示相应的信息 主要的python代码如下: 文件1 #将excel中的数据进行读取分析 import openpyxl import matplotlib.pyplot as pit #数据统计用的 wk=openpyxl.load_workbook('销售数据.xlsx') sheet=wk.active #获取活动表 #获取最大行数和最大列数 rows=sheet.max_row cols=sheet.max_colum
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
Python爬取数据保存为Json格式的代码示例
python爬取数据保存为Json格式 代码如下: #encoding:'utf-8' import urllib.request from bs4 import BeautifulSoup import os import time import codecs import json #找到网址 def getDatas(): # 伪装 header={'User-Agent':"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.1
-
python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
-
Python爬取数据并写入MySQL数据库的实例
首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据. 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几个并列的 td 标签,下面是爬取的代码: #!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup import MySQLdb print('连接到m
-
python爬取音频下载的示例代码
抓取"xmly"鬼故事音频 import json # 在这个url,音频链接为JSON动态生成,所以用到了json模块 import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36" } # 请求网页
-
python爬取youtube视频的示例代码
这几天正在追剧,原名<大秦帝国之天下>的<大秦赋>,看着看着又想把前几部刷一遍了,但第一部<裂变>自己没有高清资源,搜了一波发现youtube上有个48集版的高清资源,有删减就有删减吧,就想着写个脚本批量下载一下,记录一下过程,主要是youtube1080p及以上的分辨率做了音视频分离,下载后需要用ffmpeg做一次音视频融合.参考了pytube模块. 1.下载音视频数据 pytube可以通过pip安装 $pip install pytube from pytube
-
用python爬取租房网站信息的代码
自己在刚学习python时写的,中途遇到很多问题,查了很多资料,下面就是我爬取租房信息的代码: 链家的房租网站 两个导入的包 1.requests 用来过去网页内容 2.BeautifulSoup import time import pymssql import requests from bs4 import BeautifulSoup # https://wh.lianjia.com/zufang/ #获取url中下面的内容 def get_page(url): responce = re
-
Python爬取365好书中小说代码实例
需要转载的小伙伴转载后请注明转载的地址 需要用到的库 from bs4 import BeautifulSoup import requests import time 365好书链接:http://www.365haoshu.com/ 爬取<我以月夜寄相思>小说 首页进入到目录:http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=3026 获取小说的每个章节的名称和章节链接 打开浏览器的开发者工具,查找一个章节:如下图,找到第一章的
-
基于Python爬取搜狐证券股票过程解析
数据的爬取 我们以上证50的股票为例,首先需要找到一个网站包含这五十只股票的股票代码,例如这里我们使用搜狐证券提供的列表. https://q.stock.sohu.com/cn/bk_4272.shtml 可以看到,在这个网站中有上证50的所有股票代码,我们希望爬取的就是这个包含股票代码的表,并获取这个表的第一列. 爬取网站的数据我们使用Beautiful Soup这个工具包,需要注意的是,一般只能爬取到静态网页中的信息. 简单来说,Beautiful Soup是Python的一个库,最主要的