基于python实现cdn日志文件导入mysql进行分析
目录
- 一、本文需求背景
- 二、需求落地如下
- 三、自定义查询
一、本文需求背景
周六日出现CDN大量请求,现需要分析其请求频次与来源,查询是否存在被攻击问题。
本文以阿里云CDN日志作为辅助查询数据,其它云平台大同小异。
系统提供的离线日志如下所示:

二、需求落地如下
日志实例如下所示:
[9/Jun/2015:01:58:09 +0800] 10.10.10.10 - 1542 "-" "GET http://www.aliyun.com/index.html" 200 191 2830 MISS "Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://example.com/robot/)" "text/html"
其中相关字段的解释如下:
[9/Jun/2015:01:58:09 +0800]:日志开始时间。10.10.10.10:访问IP。-:代理IP。1542:请求响应时间,单位为毫秒。"-": HTTP请求头中的Referer。GET:请求方法。http://www.aliyun.com/index.html:用户请求的URL链接。200:HTTP状态码。191:请求大小,单位为字节。2830:请求返回大小,单位为字节。MISS:命中信息。HIT:用户请求命中了CDN边缘节点上的资源(不需要回源)。MISS:用户请求的内容没有在CDN边缘节点上缓存,需要向上游获取资源(上游可能是CDN L2节点,也可能是源站)。
Mozilla/5.0(compatible; AhrefsBot/5.0; +http://example.com/robot/):User-Agent请求头信息。text/html:文件类型。
按照上述字段说明创建一个 MySQL 表,用于后续通过 Python 导入 MySQL 数据,字段可以任意定义
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for ll -- ---------------------------- DROP TABLE IF EXISTS `ll`; CREATE TABLE `ll` ( `id` int(11) NOT NULL, `s_time` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `ip` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `pro_ip` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `dura_time` int(11) NULL DEFAULT NULL, `referer` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `method` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `url` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `code` int(255) NULL DEFAULT NULL, `size` double NULL DEFAULT NULL, `res_size` double NULL DEFAULT NULL, `miss` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `ua` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `html_type` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;
下载全部日志之后,使用 Python 批量导入数据库中,解析代码如下,在提前开始前需要先看一下待提取的每行数据内容。
[11/Mar/2022:00:34:17 +0800] 118.181.139.215 - 1961 "http://xx.baidu.cn/" "GET https://cdn.baidu.com/video/1111111111.mp4" 206 66 3739981 HIT "Mozilla/5.0 (iPad; CPU OS 15_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 SP-engine/2.43.0 main%2F1.0 baiduboxapp/13.5.0.10 (Baidu; P2 15.1) NABar/1.0" "video/mp4"
初看之下,我们会使用空格进行切片,例如下述代码:
import os
# 获取文件名
my_path = r"C:日志目录"
file_names = os.listdir(my_path)
file_list = [os.path.join(my_path, file) for file in file_names]
for file in file_list:
with open(file, 'r', encoding='utf-8') as f:
lines = f.readlines()
for i in lines:
item_list = i.split(' ')
s_time = item_list[0]+' '+item_list[1]
ip = item_list[2],
pro_ip =item_list[3],
dura_time =item_list[4],
referer =item_list[5],
method =item_list[6],
url = item_list[7],
code =item_list[8],
size =item_list[9],
res_size =item_list[10],
miss =item_list[11],
html_type =item_list[12]
print(s_time,ip,pro_ip,dura_time,referer,method,url,code,size,res_size,miss,html_type)
运行之后,会发现里面的开始时间位置,UA位置都存在空格,所以该方案舍弃,接下来使用正则表达式提取。
参考待提取的模板编写正则表达式如下所示:
\[(?<time>.*?)\] (?<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (?<pro_ip>.*?) (?<dura_time>\d+) \"(?<referer>.*?)\" \"(?<method>.*?) (?<url>.*?)\" (?<code>\d+) (?<size>\d+) (?<res_size>\d+) (?<miss>.*?) \"(?<ua>.*?)\" \"(?<html_type>.*?)\"
接下来进行循环读取数据,然后进行提取:
import os
import re
import pymysql
# 获取文件名
my_path = r"C:日志文件夹"
file_names = os.listdir(my_path)
file_list = [os.path.join(my_path, file) for file in file_names]
wait_list = []
for file in file_list:
with open(file, 'r', encoding='utf-8') as f:
lines = f.readlines()
for i in lines:
pattern = re.compile(
'\[(?P<time>.*?)\] (?P<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (?P<pro_ip>.*?) (?P<dura_time>\d+) \"(?P<referer>.*?)\" \"(?P<method>.*?) (?P<url>.*?)\" (?P<code>\d+) (?P<size>\d+) (?P<res_size>\d+) (?P<miss>.*?) \"(?P<ua>.*?)\" \"(?P<html_type>.*?)\"')
gs = pattern.findall(i)
item_list = gs[0]
s_time = item_list[0]
ip = item_list[1]
pro_ip = item_list[2]
dura_time = item_list[3]
referer = item_list[4]
method = item_list[5]
url = item_list[6]
code = item_list[7]
size = item_list[8]
res_size = item_list[9]
miss = item_list[10]
ua = item_list[11]
html_type = item_list[12]
values_str = f"('{s_time}', '{ip}', '{pro_ip}', {int(dura_time)}, '{referer}', '{method}', '{url}', {int(code)}, {int(size)}, {int(res_size)}, '{miss}', '{ua}','{html_type}')"
wait_list.append(values_str)
读取到数据存储到 wait_list 列表中,然后操作列表,写入MySQL,该操作为了防止SQL语句过长,所以每次间隔1000元素进行插入。
def insert_data():
for i in range(0,int(len(wait_list)/1000+1)):
items = wait_list[i * 1000:i * 1000 + 1000]
item_str = ",".join(items)
inser_sql = f"INSERT INTO ll(s_time, ip, pro_ip, dura_time, referer, method, url,code, size, res_size, miss, ua,html_type) VALUES {item_str}"
db = pymysql.connect(host='localhost',
user='root',
password='root',
database='logs')
cursor = db.cursor()
try:
cursor.execute(inser_sql)
db.commit()
except Exception as e:
# print(content)
print(e)
db.rollback()
最终的结果如下所示:
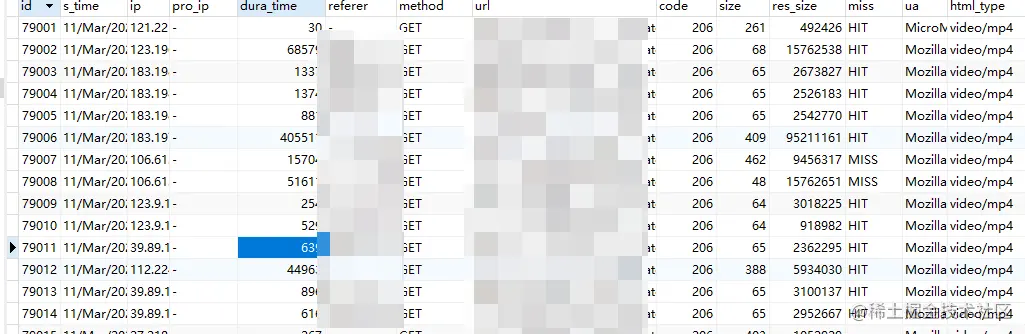
导入MySQL之后,就可以按照自己的需求进行排序与查询了。
三、自定义查询
可以通过 refer 计算请求次数:
select count(id) num,referer from ll GROUP BY referer ORDER BY num desc

到此这篇关于基于python实现cdn日志文件导入mysql进行分析的文章就介绍到这了,更多相关cdn日志导入mysql内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-

基于 Python实现云服务器的CDN域名远程鉴权配置
目录 实战场景 开启远程鉴权 Python 端权限验证 验证逻辑 实战场景 在项目实战中,会碰到一种特定的运维场景,对CDN访问进行限制,一般手段是开启 referer 防盗链,开启 IP黑白名单,开启UA黑白名单,本篇博客为大家展示的是通过我们自己的服务器,然后实现远程鉴权,进行更加细致的权限判定. 实现目标: 请求CDN资源调用我们的鉴权服务器 鉴权服务器获取请求信息,并保存到日志中 分别返回鉴权成功,鉴权失败 开启远程鉴权 在远程鉴权页面打开[开关]之后,出现如下配置界面,这里相关细节描述
-
EarthLiveSharp中cloudinary的CDN图片缓存自动清理python脚本
恰巧发现有个叫"EarthLiveSharp",可用将日本向日葵8号卫星的地球实时图片设为屏保.向日葵8号卫星的地球实时图片官网为:http://himawari8.nict.go.jp/,EarthLiveSharp的项目地址是:https://github.com/bitdust/EarthLiveSharp. 为了减轻向日葵8号的服务器负担,同时也是提高地球实时图片的获取成功率,需要使用cloudinary来做CDN.注册配置都在软件里有说明. 目前EarthLiveSharp暂
-
Python连接Mysql实现图书借阅系统
相信大家在学习python编程时绝对离不开数据库的连接,那么我们就用python来连接数据库实现一个简单的图书借阅系统.其实也很简单,就是在我们的程序中加入sql语句即可 数据库的表结构 我们在这里需要三张表,一张用户表,一张图书表和一张借阅表.注意我们的数据库命名为bbs(book borrow system) 1.用户表 2.图书表 bookname:书名author:作者booknum:图书编号bookpress:出版社bookamoun:图书数量 3.借阅表 id:借阅号borrowna
-
python+tkinter+mysql做简单数据库查询界面
目录 一.准备工作: 二.代码: 三.界面 四.总结 一.准备工作: 1.安装mysql3.7,创建一个test数据库,创建student表,创建列:(列名看代码),创建几条数据 (以上工作直接用navicat for mysql工具完成) 二.代码: import sys import tkinter as tk import mysql.connector as sql #--------------------查询函数--------------------------- def sql_
-
python把数据框写入MySQL的方法
背景: 下文利用上海市2016年9月1日公共交通卡刷卡数据 如图: 想做一下上海市通勤数据挖掘,由于源文件有800多兆,用python读取起来很慢很卡,于是想导入数据库MySQL里面处理,以前一般是打开workbench可视化操作导入数据库,这次想换成代码实现,于是琢磨着如何把这个csv文件用python导进去.一般的,python把数据框写入数据库有两种方法 利用insert into 命令一条一条插入: 采用这种方法,可以爬一条立马向数据库里面插入一条数据,整体衔接好,不怕大量数据一次性塞进
-
基于python实现cdn日志文件导入mysql进行分析
目录 一.本文需求背景 二.需求落地如下 三.自定义查询 一.本文需求背景 周六日出现CDN大量请求,现需要分析其请求频次与来源,查询是否存在被攻击问题. 本文以阿里云CDN日志作为辅助查询数据,其它云平台大同小异. 系统提供的离线日志如下所示: 二.需求落地如下 日志实例如下所示: [9/Jun/2015:01:58:09 +0800] 10.10.10.10 - 1542 "-" "GET http://www.aliyun.com/index.html" 20
-
python解析基于xml格式的日志文件
大家中午好,由于过年一直还没回到状态,好久没分享一波小知识了,今天,继续给大家分享一波Python解析日志的小脚本. 首先,同样的先看看日志是个啥样. 都是xml格式的,是不是看着就头晕了??没事,我们先来分析一波. 1.每一段开头都是catalina-exec,那么我们就按catalina-exec来分,分了之后,他们就都是一段一段的了. 2.然后,我们再在已经分好的一段段里面分,找出你要分割的关键字,因为是xml的,所以,接下来的工作就简单了,都是一个头一个尾的. 3.但是还有一个问题,有可
-
php基于Fleaphp框架实现cvs数据导入MySQL的方法
本文实例讲述了php基于Fleaphp框架实现cvs数据导入MySQL的方法.分享给大家供大家参考,具体如下: <?php /* * To change this template, choose Tools | Templates * and open the template in the editor. */ class Controller_KaoqinUpload extends FLEA_Controller_Action { var $uploaddir = "./uploa
-
PHP编程实现csv文件导入mysql数据库的方法
本文实例讲述了PHP编程实现csv文件导入mysql数据库的方法.分享给大家供大家参考,具体如下: config.db.php内容如下: <?php $username="root"; $userpass="123"; $dbhost="localhost"; $dbdatabase="credits2stakes"; //生成一个连接 $db_connect=mysql_connect($dbhost,$usernam
-
基于python批量处理dat文件及科学计算方法详解
摘要:主要介绍一些python的文件读取功能,文件内容修改,文件名后缀更改等操作. 批处理文件功能 import os path1 = 'C:\\Users\\awake_ljw\\Documents\\python for data analysis\\test1' path2 = 'C:\\Users\\awake_ljw\\Documents\\python for data analysis\\test2' filelist = os.listdir(path1) for files i
-
使用navicat将csv文件导入mysql
本文为大家分享了使用navicat将csv文件导入mysql的具体代码,供大家参考,具体内容如下 1.打开navicat,连接到数据库并找到自己想要导入数据的表.数据库表在指定数据库下的表下. 2.右键点击数据表.点击import wizard. 3.选择要导入数据的文件类型,本文以csv文件为例,选中csv文件. 4.接下来选择文件所在位置.可以点击第一个空输入框后的省略号,可以通过浏览文件系统定位自己的文件.下边的编码选择与你的文件一样的编码. 5.第一个选项为记录分割,可以使用默认的,第二
-
如何将Excel文件导入MySQL数据库
本文实例为大家分享了Excel文件导入MySQL数据库的方法,供大家参考,具体内容如下 1.简介 本博客给大家分享一个实用的小技能,我们在使用数据库时常常需要将所需的Excel数据添加进去,如果按照传统的方法将会费时费力,所以给大家分享导入Excel数据的技能. 2.实际操作 1)首先需要下载一个数据库管理工具名为Navicat for MySQL,可以通过以下网址下载Navicat for MySQL,下载安装完成后即可进行操作: 2)我以一个CET-6的词汇表为例进行讲解,该词汇表内容部分截
-
python处理大日志文件
本文实例为大家分享了python处理大日志文件的具体代码,供大家参考,具体内容如下 # coding=utf-8 import sys import time class Tail(): def __init__(self,file_name,callback=sys.stdout.write): self.file_name = file_name self.callback = callback def follow(self,n=10): try: # 打开文件 with open(sel
-
基于python判断目录或者文件代码实例
这篇文章主要介绍了基于python判断目录或者文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1. 判断目录是否存在 'isdir',删除目录时只有该目录为空才可以 'rmdir' import os if(os.path.isdir('D:/Python_workspace/spyder_space/test_各种功能/哈哈哈哈')): #判断目录是否存在 print('yes') os.rmdir('D:/Python_work
-
基于Python获取docx/doc文件内容代码解析
这篇文章主要介绍了基于Python获取docx/doc文件内容代码解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 整体思路: 下载文件并修改后缀为zip文件,解压zip文件,所要获取的内容在固定的文件夹下:work/temp/word/document.xml 所用包,全部是python自带,不需要额外下载安装. # encoding:utf-8 import os import re import requests import zipf