ORA-00349|激活 ADG 备库时遇到的问题及处理方法
近日有一套实时同步的 ASM 管理的单机 11204 ADG 备库,由于业务需要,想要脱离主库的约束,想激活拉成读写库直接升级成 ASM 管理的 19C,闪回快照模式无法满足要求,只能 ALTER DATABASE ACTIVATE STANDBY DATABASE 强制切成可读写的主库。说干就干,先将其切成主库,升级过程等下次在一起讨论。
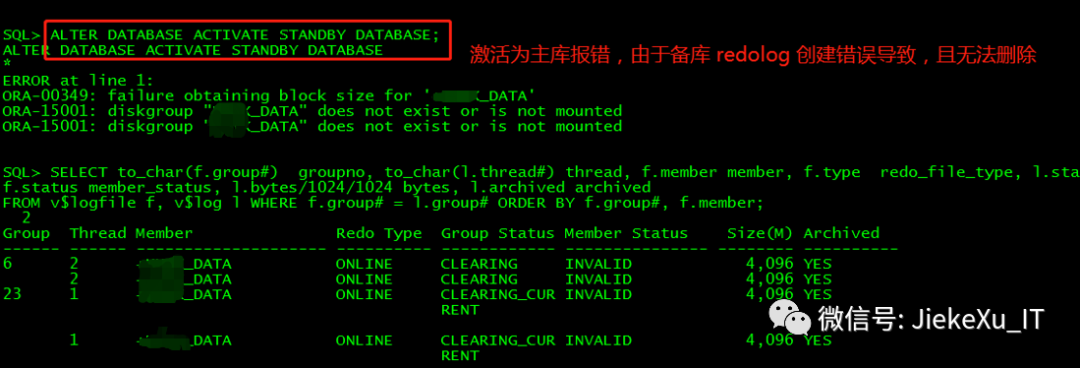
--主库 --主库设置为 defer, 取消备库日志应用,关库启动到 mount 状态进行。 show parameter log_archive_dest_state_2 alter system set log_archive_dest_state_2=defer scope=both sid='*'; --备库 alter database recover managed standby database cancel; shu immediate startup mount --强制拉成主库,很遗憾报错 ORA-00349 SQL> ALTER DATABASE ACTIVATE STANDBY DATABASE; ALTER DATABASE ACTIVATE STANDBY DATABASE * ERROR at line 1: ORA-00349: failure obtaining block size for '+JIEKE_DATA' ORA-15001: diskgroup "JIEKE_DATA" does not exist or is not mounted ORA-15001: diskgroup "JIEKE_DATA" does not exist or is not mounted
使用 ACTIVATE 命令想强制拉成主库,很遗憾如下图报错 ORA-00349。alert 日志中发现有很多清理 redo log 的报错,“ORA-00313: open failed…”无法打开日志组 5、6、23,于是查看日志组成员确实发现 redolog 创建的有问题,member 成员显示的为不存在的磁盘组 “+JIEKE_DATA” 而不是具体路径,真是存在的磁盘组“+JIEKER_DATA”。这就是问题所在,redolog 创建错误,切成主库时 redolog 又是必须的,故报错了,那么现在就是将这个错误的 redolog 重建,问题就会得到解决。但实际上不是这样的,折腾了好久也没解决,继续往下看。
GROUP# Member
---------- ---------------------------------------------------------------------------------------------------
5 +JIEKE_DATA
5 +JIEKE_DATA
6 +JIEKE_DATA
6 +JIEKE_DATA
23 +JIEKE_DATA
23 +JIEKE_DATA
11 +JIEKER_DATA/jiekexu/onlinelog/group_11.1621.1065127343
11 +JIEKER_ARCH/jiekexu/onlinelog/group_11.389.1065127355
12 +JIEKER_DATA/jiekexu/onlinelog/group_12.1620.1065127363
12 +JIEKER_ARCH/jiekexu/onlinelog/group_12.395.1065127371
13 +JIEKER_DATA/jiekexu/onlinelog/group_13.1619.1065127381
SELECT to_char(f.group#) groupno, to_char(l.thread#) thread, f.member member, f.type redo_file_type, l.status group_status, f.status member_status, l.bytes/1024/1024 bytes, l.archived archived
FROM v$logfile f, v$log l WHERE f.group# = l.grSQL> oup# ORDER BY f.group#, f.member;
SQL> SQL> SQL> SQL> SQL> SQL> SQL> SQL> SQL> 2
Group Thread Member Redo Type Group Status Member Status Size(M) Archived
------ ------ -------------------- ---------- ------------ --------------- -------- ----------
5 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
6 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
23 1 +JIEKE_DATA ONLINE CLEARING_CUR INVALID 4,096 YES
RENT
1 +JIEKE_DATA ONLINE CLEARING_CUR INVALID 4,096 YES
RENT
27 2 +JIEKER_DATA/jiekexu/ ONLINE UNUSED 4,096 YES
onlinelog/group_27.1
741.1065129955
28 2 +JIEKER_DATA/jiekexu/ ONLINE UNUSED 4,096 YES
onlinelog/group_28.1
742.1065129973
alert 日志如下:
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 5 of thread 1
Clearing online redo logfile 5 +JIEKE_DATA
Clearing online log 5 of thread 1 sequence number 4751
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 5 of thread 1
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 5 of thread 1
Clearing online redo logfile 5 complete
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 6 of thread 2
Clearing online redo logfile 6 +JIEKE_DATA
Clearing online log 6 of thread 2 sequence number 2592
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 6 of thread 2
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 6 of thread 2
Clearing online redo logfile 6 complete
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 23 of thread 1
Clearing online redo logfile 23 +JIEKE_DATA
Clearing online log 23 of thread 1 sequence number 4752
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 23 of thread 1
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 23 of thread 1
Clearing online redo logfile 23 complete
Resetting resetlogs activation ID 2008461997 (0x77b6b2ad)
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 5 of thread 1
Errors in file /app/oracle/diag/rdbms/jiekexu/jiekexu/trace/jiekexu_ora_30872.trc:
ORA-00313: open failed for members of log group 5 of thread 1
ORA-349 signalled during: ALTER DATABASE ACTIVATE PHYSICAL STANDBY DATABASE...
Tue Mar 02 22:42:30 2021
alter database drop logfile group 23
ORA-1623 signalled during: alter database drop logfile group 23...
Tue Mar 02 22:45:07 2021
RFS[7]: Assigned to RFS process 10180
RFS[7]: Opened log for thread 2 sequence 2592 dbid 1797812601 branch 1063804222
Archived Log entry 1100 added for thread 2 sequence 2592 rlc 1063804222 ID 0x77b6b2ad dest 2:
Tue Mar 02 22:45:08 2021
RFS[8]: Assigned to RFS process 10277
RFS[8]: Selected log 17 for thread 2 sequence 2593 dbid 1797812601 branch 1063804222
Tue Mar 02 22:45:08 2021
Primary database is in MAXIMUM PERFORMANCE mode
重建备库 redolog
那么,这里将上演的是重建备库 redolog 的相关操作步骤。
SQL> alter database drop logfile group 27; alter database drop logfile group 27 * ERROR at line 1: ORA-01156: recovery or flashback in progress may need access to files --由于开启了日志应用进程,直接删除会报错,故需要停止日志应用,修改参数 standby_file_management 为手动。 SQL> alter database recover managed standby database cancel; Database altered. SQL> alter system set standby_file_management='manual' scope=both sid='*'; Database altered. SQL> show parameter standby_file_management NAME TYPE VALUE ------------------------------------ ---------------------- ------------------------------ standby_file_management string manual SQL> alter database drop logfile group 27; Database altered. --由于日志组不能少于 2 个,故 日志组 28 不不能够删除。 SQL> alter database drop logfile group 28; alter database drop logfile group 28 * ERROR at line 1: ORA-01567: dropping log 28 would leave less than 2 log files for instance JIEKEXU2 (thread 2) ORA-00312: online log 28 thread 2: '+JIEKER_DATA/jiekexu/onlinelog/group_28.1742.1065129973'
下面则通过继续应用日志、重启、主库切日志、重命名等各种手段继续尝试删除这三个有问题的日志组。
--重启备库删除日志组 6、23,由于是当前日志组无法删除,庆幸日志组 5 成功删除了。 SQL> alter database drop logfile group 6; alter database drop logfile group 6 * ERROR at line 1: ORA-01623: log 6 is current log for instance JIEKEXU2 (thread 2) - cannot drop ORA-00312: online log 6 thread 2: '+JIEKE_DATA' ORA-00312: online log 6 thread 2: '+JIEKE_DATA' SQL> alter database drop logfile group 5; Database altered. SQL> alter database drop logfile group 23; alter database drop logfile group 23 * ERROR at line 1: ORA-01623: log 23 is current log for instance jiekexu (thread 1) - cannot drop ORA-00312: online log 23 thread 1: '+JIEKE_DATA' ORA-00312: online log 23 thread 1: '+JIEKE_DATA' --只剩两组日志组也是当前日志组,则当前日志组无法删除,尝试进行 rename 操作,但也是无效或者缺失命令。 SQL> alter database rename '+JIEKE_DATA' to '+JIEKER_DATA'; alter database rename '+JIEKE_DATA' to '+JIEKER_DATA' * ERROR at line 1: ORA-02231: missing or invalid option to ALTER DATABASE SQL> alter database rename '+JIEKE_DATA' to '+JIEKER_DATA/jiekexu/onlinelog/group_6.dbf'; alter database rename '+JIEKE_DATA' to '+JIEKER_DATA/jiekexu/onlinelog/group_6.dbf' * ERROR at line 1: ORA-02231: missing or invalid option to ALTER DATABASE --当然继续激活为主库肯定也是报错。那就继续开启日志同步模式,先保持备库同步吧。 SQL> ALTER DATABASE ACTIVATE STANDBY DATABASE; ALTER DATABASE ACTIVATE STANDBY DATABASE * ERROR at line 1: ORA-00349: failure obtaining block size for '+JIEKE_DATA' ORA-15001: diskgroup "JIEKE_DATA" does not exist or is not mounted ORA-15001: diskgroup "JIEKE_DATA" does not exist or is not mounted SQL> alter database recover managed standby database using current logfile disconnect from session; Database altered.
重建备库控制文件解决
第二日早晨,睡醒之后头脑清晰想到备库既然无法删除,那主库肯定是可以删除的。通过主库删除日志组 6、23 之后,再重建一个备库的控制文件就可以解决。这样也很简单,主库删除备库有问题的两组日志组后使用 rman 备份一个备库的 控制文件,然后 scp 到备库,备库重启到 nomount 恢复控制文件,启动到 mount 就好了。
--主库: SQL> alter database drop logfile group 6; Database altered. SQL> alter database drop logfile group 23; Database altered. rman target / RMAN> backup current controlfile for standby format '/home/oracle/backup20210303%d_%I_%s_%p.ctl'; scp /home/oracle/backup20210303%d_%I_%s_%p.ctl jiekeadg:/home/oracle/ --备库 SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL; Database altered. SQL> shu immediate ORA-01109: database not open Database dismounted. ORACLE instance shut down. SQL> startup nomount ORACLE instance started. Total System Global Area 1.0689E+11 bytes Fixed Size 2265864 bytes Variable Size 4.2144E+10 bytes Database Buffers 6.4425E+10 bytes Redo Buffers 323678208 bytes SQL> exit jiekeadg:/home/oracle(jiekexu)>rman target / Recovery Manager: Release 11.2.0.4.0 - Production on Wed Mar 3 10:07:34 2021 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: JIEKEXU (not mounted) RMAN> restore standby controlfile from '/home/oracle/backup20210303JIEKEXU_1797812601_106_1.ctl'; Starting restore at 2021-03-03 10:08:03 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=3009 device type=DISK channel ORA_DISK_1: restoring control file channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 output file name=+JIEKER_DATA/jiekexu/controlfile/current.1739.1065125909 output file name=+JIEKER_ARCH/jiekexu/controlfile/current.323.1065125911 Finished restore at 2021-03-03 10:08:04 RMAN> sql'alter database mount'; sql statement: alter database mount released channel: ORA_DISK_1 RMAN> exit -- SQLPLUS 里应用 MRP0 进程同步数据。 jiekeadg:/home/oracle(jiekexu)>sqlplus / as sysdba SQL> alter database recover managed standby database using current logfile disconnect from session; Database altered. SQL> / NAME VALUE UNIT TIME_COMPUTED ------------- -------------------- ------------------------------ ------------------------------ transport lag +00 00:00:00 day(2) to second(0) interval 03/03/2021 10:19:08 apply lag +00 00:00:00 day(2) to second(0) interval 03/03/2021 10:19:08
重建控制文件后恢复的备库中就没有了错误的磁盘组,但这样时间长一些则备库日志应用会延迟,因为 standby_log 日志状态全部为 UNASSIGNED 的。需要重建备库 standby redolog 日志组后它的状态才会变成 ACTIVE。
取消日志应用,修改参数为 manual 删除原有日志组,重建日志组改回参数应用日志同步进程即可。
SELECT to_char(f.group#) groupno, to_char(l.thread#) thread, f.member member, f.type redo_file_type, l.status group_status, f.status member_status, l.bytes/1024/1024 bytes, l.archived archived
FROM v$logfile f, v$log l WHERE f.group# = l.group# ORDER BY f.group#, f.member;SQL>
SQL> SQL> SQL> SQL> SQL> SQL> SQL> SQL> SQL> 2
Group Thread Member Redo Type Group Status Member Status Size(M) Archived
------ ------ -------------------- ---------- ------------ --------------- -------- ----------
1 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
2 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
3 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
4 1 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES
1 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES
5 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
7 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
8 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
9 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
10 2 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES
2 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES
24 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
Database altered.
SQL> show parameter standby_file_management
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------standby_file_management string manual
SQL>
SQL> select inst_id,GROUP#,THREAD#,SEQUENCE#,USED,ARCHIVED,STATUS from gv$standby_log;
INST_ID GROUP# THREAD# SEQUENCE# USED Archived STATUS
---------- ---------- ---------- ---------- ---------- ---------- --------------------
1 11 1 0 0 YES UNASSIGNED
1 12 1 0 0 YES UNASSIGNED
1 13 1 0 0 YES UNASSIGNED
1 14 1 0 0 YES UNASSIGNED
1 15 1 0 0 YES UNASSIGNED
alter database drop logfile group 11;
alter database drop logfile group 12;
alter database drop logfile group 13;
alter database drop logfile group 14;
alter database drop logfile group 15;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+JIEKER_DATA','+JIEKER_ARCH') SIZE 4G;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+JIEKER_DATA','+JIEKER_ARCH') SIZE 4G;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+JIEKER_DATA','+JIEKER_ARCH') SIZE 4G;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+JIEKER_DATA','+JIEKER_ARCH') SIZE 4G;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+JIEKER_DATA','+JIEKER_ARCH') SIZE 4G;
SQL> select inst_id,GROUP#,THREAD#,SEQUENCE#,USED,ARCHIVED,STATUS from gv$standby_log;
INST_ID GROUP# THREAD# SEQUENCE# USED Archived STATUS
---------- ---------- ---------- ---------- ---------- ---------- --------------------
1 6 1 4797 3026358272 YES ACTIVE
1 11 1 0 0 YES UNASSIGNED
1 12 1 0 0 YES UNASSIGNED
1 13 1 0 0 YES UNASSIGNED
1 14 1 0 0 YES UNASSIGNED
SQL> alter system set standby_file_management='AUTO' scope=both sid='*';
SQL> alter database open;
alter database recover managed standby database using current logfile disconnect from session;
Database altered.
找到最终问题所在
完成重建后,本以为已经万事大吉了,但一开库应用日志却发现后台日志中所有 redolog 日志组都被清理了。这才意识到问题的根源所在,立马查看了路径相关的参数发现 db_create_online_log_dest 参数设置错误,导致创建出了错误的磁盘组。
jiekeadg:/home/oracle(jiekexu)>sqlplus / as sysdba SQL*Plus: Release 11.2.0.4.0 Production on Wed Mar 3 10:52:04 2021 Copyright (c) 1982, 2013, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options SQL> show parameter db_create_online_log_dest_ NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_create_online_log_dest_1 string +JIEKE_DATA db_create_online_log_dest_2 string +JIEKE_DATA db_create_online_log_dest_3 string db_create_online_log_dest_4 string db_create_online_log_dest_5 string SQL> alter system set db_create_online_log_dest_1='+JIEKER_DATA' scope=spfile; System altered. SQL> alter system set db_create_online_log_dest_2='+JIEKER_DATA' scope=spfile; System altered.
但是现在修改完参数所有的日志组成员也都出现在错误的磁盘组了,因为有了当前日志组 4、10 占用了,重建日志组也行不通,故只能再次重建备库控制文件了。以上主库备份控制文件传到备库恢复的过程再来一遍即可。
SELECT to_char(f.group#) groupno, to_char(l.thread#) thread, f.member member, f.type redo_file_type, l.status group_status, f.status member_status, l.bytes/1024/1024 bytes, l.archived archived FROM v$logfile f, v$log l WHERE f.group# = l.group# ORDER BY f.group#, f.member;SQL> SQL> SQL> SQL> SQL> SQL> SQL> SQL> SQL> SQL> 2 Group Thread Member Redo Type Group Status Member Status Size(M) Archived ------ ------ -------------------- ---------- ------------ --------------- -------- ---------- 1 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 2 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 3 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 4 1 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES 1 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES 5 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 1 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 7 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 8 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 9 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 10 2 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES 2 +JIEKE_DATA ONLINE CURRENT INVALID 4,096 YES 24 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 2 +JIEKE_DATA ONLINE CLEARING INVALID 4,096 YES 20 rows selected.
最终激活备库
再一次重建后正常恢复同步,然后关闭实例启动到 mount 状态,激活 ADG 备库,重启验证即可。
SQL> shu immediate Database closed. Database dismounted. ORACLE instance shut down. SQL> SQL> startup mount ORACLE instance started. Total System Global Area 1.0689E+11 bytes Fixed Size 2265864 bytes Variable Size 4.2144E+10 bytes Database Buffers 6.4425E+10 bytes Redo Buffers 323678208 bytes Database mounted. SQL> SQL> ALTER DATABASE ACTIVATE STANDBY DATABASE; Database altered. SQL> alter database open; Database altered. SQL> select DATABASE_ROLE from v$database; DATABASE_ROLE -------------------------------- PRIMARY SQL> shu immediate Database closed. Database dismounted. ORACLE instance shut down. SQL> startup ORACLE instance started. Total System Global Area 1.0689E+11 bytes Fixed Size 2265864 bytes Variable Size 4.2144E+10 bytes Database Buffers 6.4425E+10 bytes Redo Buffers 323678208 bytes Database mounted. Database opened. SQL> exit
到此这篇关于ORA-00349|激活 ADG 备库时遇到的问题及处理方法的文章就介绍到这了,更多相关ORA-00349内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Oracle备库宕机启动的完美解决方案
简介 ORA-10458: standby database requires recovery ORA-01196: 文件 1 由于介质恢复会话失败而不一致 ORA-01110: 数据文件 1: 'XXXXXXXXXXXXXXXXXX\XXXXX1.DBF' 一个项目做了Oracle主从数据库同步,通过Dataguard实现,从库服务器宕机,再开机的时候,从库无法启动,报"ORA-01196: 文件 1 由于介质恢复会话失败而不一致"这个错误,具体日志信息如下: ORA-10458:
-
Oracle数据库由dataguard备库引起的log file sync等待问题
导读: 最近数据库经常出现会话阻塞的报警,过一会又会自动消失,昨天晚上恰好发生了一次,于是赶紧进行了查看,不看不知道,一看吓一跳,发现是由dataguard引起的log file sync等待.我们知道,通常log file sync等待都是由频繁写日志造成的,这次居然是由DG环境引起的. (一)问题描述 数据库:Oracle 11.2.0.4,单机版,有Dataguard环境 操作系统:centos 7.4 通过zabbix监控到的会话阻塞信息如下图,这里是自定义的监控,解释如下: 用户use
-
win平台oracle rman备份和删除dg备库归档日志脚本
总觉得使用windows跑oracle是不靠谱的事情,可以这个世界上总有很多人喜欢做类似这样的事情,对于数据库比较常见的两件事情:rman和删除dg备库归档日志,在linux/unix平台上使用shell实现很简单,可是跑到win里面,就变的烦了,不是因为其麻烦,而是因为用的人少,不知道怎么下手处理该事情,我编写了简单的实现初级功能的win下面rman备份和删除备库归档日志脚本,供大家参考,也更加欢迎朋友提出来更加好的处理方法(win是真心的不懂)rman备份脚本 复制代码 代码如下: --ba
-
ORA-00349|激活 ADG 备库时遇到的问题及处理方法
近日有一套实时同步的 ASM 管理的单机 11204 ADG 备库,由于业务需要,想要脱离主库的约束,想激活拉成读写库直接升级成 ASM 管理的 19C,闪回快照模式无法满足要求,只能 ALTER DATABASE ACTIVATE STANDBY DATABASE 强制切成可读写的主库.说干就干,先将其切成主库,升级过程等下次在一起讨论. --主库 --主库设置为 defer, 取消备库日志应用,关库启动到 mount 状态进行. show parameter log_archive_dest
-
pip安装Python库时遇到的问题及解决方法
笔者电脑系统是win7,同时安装了Python2.7和Python3.6,但是在通过命令行直接使用"pip install XXX"安装Python库时出现了以下的错误信息: Fatal error in launcher: Unable to create process using '"' 解决方法: 1,找到你的Python版本对应的解释器的名称 首先你需要进入安装Python相应版本所在的文件夹.以我的Python版本为例,这是我的Python2.7版本对应的解释器名
-
Spring Boot中自定义注解结合AOP实现主备库切换问题
摘要:本篇文章的场景是做调度中心和监控中心时的需求,后端使用TDDL实现分表分库,需求:实现关键业务的查询监控,当用Mybatis查询数据时需要从主库切换到备库或者直接连到备库上查询,从而减小主库的压力,在本篇文章中主要记录在Spring Boot中通过自定义注解结合AOP实现直接连接备库查询. 一.通过AOP 自定义注解实现主库到备库的切换 1.1 自定义注解 自定义注解如下代码所示 import java.lang.annotation.ElementType; import java.la
-
mysql主键的缺少导致备库hang住
最近线上频繁的出现slave延时的情况,经排查发现为用户在删除数据的时候,由于表主键的主键的缺少,同时删除条件没有索引,或或者删除的条件过滤性极差,导致slave出现hang住,严重的影响了生产环境的稳定性,也希望通过这篇博客,来加深主键在innodb引擎中的重要性,希望用户在使用RDS,设计自己的表的时候,一定要为表加上主键,主键可以认为是innodb存储引擎的生命,下面我们就来分析一下这个案例(本案例的生产环境的binlog为row模式,对于myisam存储引擎也有同样的问题): (1).现
-
mysql建库时提示Specified key was too long max key length is 1000 bytes的问题的解决方法
索引字段长度太长, 1.修改字段长度 2.修改mysql默认的存储引擎 在/etc/mysql/my.cnf 的[mysqld] 下面加入default-storage-engine=INNODB 但是在建库时已经明确表明了需要使用INNODB引擎 Sql代码 复制代码 代码如下: CREATE TABLE `acs` ( ... ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 检查当前的引擎 复制代码 代码如下: mysql> show engines; 果然没有I
-
解决安装python库时windows error5 报错的问题
python安装库时,有时候会报错windows error 5,可以尝试关闭所有使用python的编辑器.文件等,然后重新pip安装,如果还是不行,可以将报错最下层文件删除即可(如果不放心可以将该文件先备份),记录之~ windows error错误代码: windows error错误代码: 0操作成功完成. 1功能错误. 2系统找不到指定的文件. 3系统找不到指定的路径. 4系统无法打开文件. 5拒绝访问. 6句柄无效. 7存储控制块被损坏. 8存储空间不足,无法处理此命令. 9存储控制块
-
解决pycharm下载库时出现Failed to install package的问题
pycharm下载库时出现Failed to install package怎么解决?奶奶都会解决的那种. 一.当前现状 看看你是否也是这种情况: 正常来说我们下载这个pygad包,只需点击Install package即可.但是当我们点击下载之后,出现了一个意想不到的错误,如下图: 我们点击Details查看细节,如下图: 而且我用 pip install 安装了numpy这个库,并且用 pip list 查看了一下,发现这个库是已经存在的: 但是默认的路径下确实没有numpy库 一.解决方法