R语言中qplot()函数的用法说明
ggplot2()函数
ggplot2是一个强大的作图工具,它可以让你不受现有图形类型的限制,创造出任何有助于解决你所遇到问题的图形。
qplot()
qplot()属于ggplot2(),可以理解成是它的简化版本。
qplot 即“快速作图”(quick plot),顾名思义,能快速对数据进行可视化分析。它的用法和R base包的plot函数很相似。
qplot()
参数
qplot(x, y = NULL, ..., data, facets = NULL, margins = FALSE, geom = "auto", stat = list(NULL), position = list(NULL), xlim = c(NA, NA), ylim = c(NA, NA), log = "", main = NULL, xlab = deparse(substitute(x)), ylab = deparse(substitute(y)), asp = NA)
各项参数详解
1.x, y:变量名
2.data: 为数据框(data.frame)类型;如果有这个参数,那么x,y的名称必需对应数据框中某列变量的名称
3.facets: 图形/数据的分面。这是ggplot2作图比较特殊的一个概念,它把数据按某种规则进行分类,每一类数据做一个图形,所以最终效果就是一页多图
4.margins: 是否显示边界
5.geom: 图形的几何类型(geometry),这又是ggplot2的作图概念。ggplot2用几何类型表示图形类别,比如point表示散点图、line表示曲线图、bar表示柱形图等。
6.stat: 统计类型(statistics),这个更加特殊。直接将数据统计和图形结合,这是ggplot2强大和受欢迎的原因之一。
7.position: 图形或者数据的位置调整,这不算太特殊,但对于图形但外观很重要
8.xlim, ylim, 设置轴的上下限
9.xlab, ylab, 在x,y轴上增加标签
10.asp: 图形纵横比
qplot做散点图
使用向量数据
plot函数一样,如果不指定图形的类型,qplot默认做出散点图。对于给定的x和y向量做散点图,qplot用法也和plot函数差不多
> library(ggplot2) > x <- 1:1000 > y <- rnorm(1000) > plot(x, y, main="Scatter plot by plot()") > qplot(x,y, main="Scatter plot by qplot()")
使用数据框数据
虽然可以直接使用向量数据,但ggplot2更倾向于使用数据框类型的数据作图。使用数据框有几个好处:数据框可以用来存储数值、字符串、因子等不同类型等数据;把数据放在同一个R数据框对象中可以避免使用过程中数据关系的混乱;数据外观的整理和转换方便。ggplot2中使用数据框作图的最直接的一个效果就是:你可以直接用数据的分类特性(数据框中的列变量)来决定图形元素的外观,这个过程在ggplot2中称为映射(mapping),是自动的。
在演示使用数据框作图的好处之前我们先了解以下ggplot2提供的一组有关钻石的示范数据 diamonds:
> str(diamonds) Classes ‘tbl_df', ‘tbl' and 'data.frame': 53940 obs. of 10 variables: $ carat : num 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ... $ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ... $ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ... $ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ... $ depth : num 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ... $ table : num 55 61 65 58 58 57 57 55 61 61 ... $ price : int 326 326 327 334 335 336 336 337 337 338 ... $ x : num 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ... $ y : num 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ... $ z : num 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...
可以看到这是数据框(data.frame)类型,有10个变量(列),每个变量有53940个测量值(行)。
第一列为钻石的克拉数(carat),为数字型数据;第二列为钻石的切工好坏(cut),为因子类型数据,有5个水平;第三列为钻石颜色(color),为7水平的因子;后面还有其他数据。
由于数据太多,我们只取前7列的100个随机观测值。数据基本就是我们平时记录原始数据的样式:
> set.seed(1000) # 设置随机种子,使随机取样具有可重复性 > datax<- diamonds[ seq(1,7)] > head(datax, 4) ## carat cut color clarity depth table price ## 17686 1.23 Ideal H VS2 62.2 55 7130 ## 40932 0.30 Ideal E SI1 61.7 58 499 ## 6146 0.90 Good H VS2 61.9 58 3989 ## 37258 0.31 Ideal G VVS1 62.8 57 977
如果要做钻石克拉和价格关系的曲线图,用plot和qplot函数都差不多:
plot(x=datax$carat, y=datax$price, xlab="Carat", ylab="Price", main="plot function") qplot(x=carat, y=price, data=datax, xlab="Carat", ylab="Price", main="qplot function")
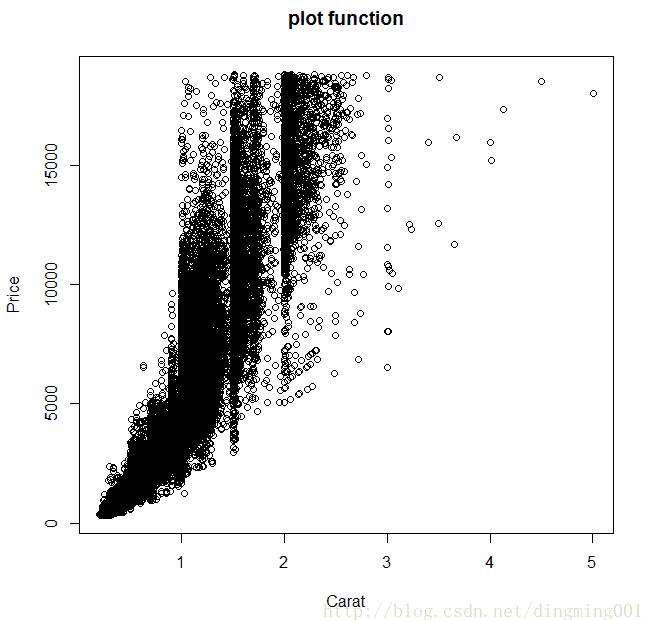
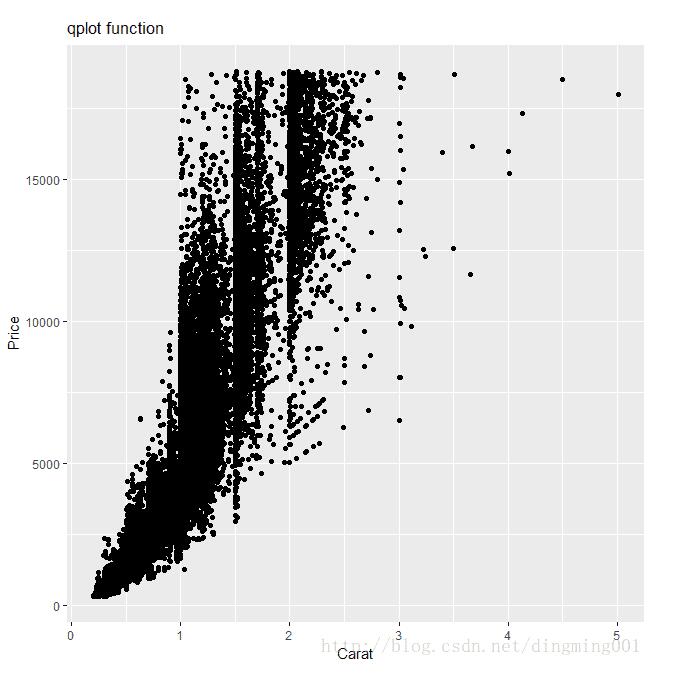
但如果要按切工进行分类作图,plot函数的处理就复杂了,你首先得将数据进行分类提取,然后再一个个作图。虽然可以用循环完成,但作图后图标的添加还得非常小心,你得自己保证数据和图形外观之间的对应关系:
plot(x=datax$carat, y=datax$price, xlab="Carat", ylab="Price", main="plot function", type='n')
cut.levels <- levels(datax$cut)
cut.n <- length(cut.levels)
for(i in seq(1,cut.n)){
subdatax <- datax[datax$cut==cut.levels[i], ]
points(x=subdatax$carat, y=subdatax$price, col=i, pch=i)
}
legend("topleft", legend=cut.levels, col=seq(1,cut.n), pch=seq(1,cut.n), box.col="transparent", cex=0.8)
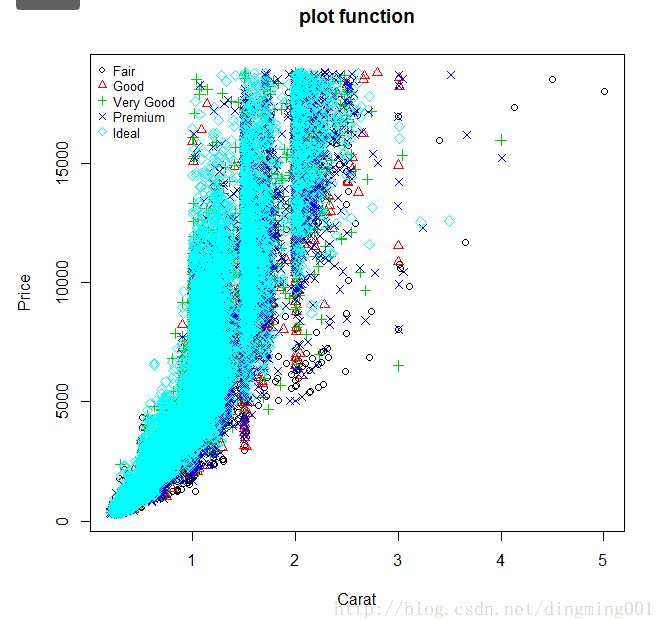
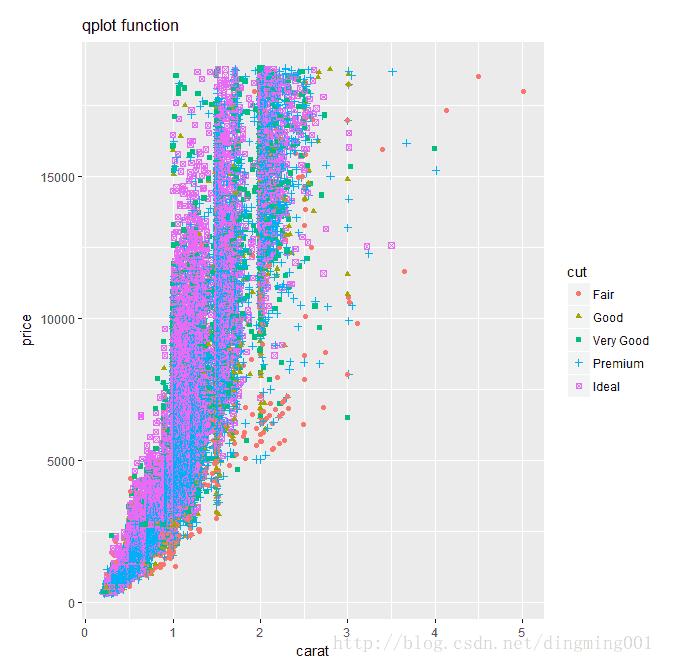
但用ggplot2作图你需要考虑数据分类和图形元素方面的问题就很少,你只要告诉它用做分类的数据就可以了:
qplot(x=carat, y=price, data=datax, color=cut, shape=cut, main="qplot function")
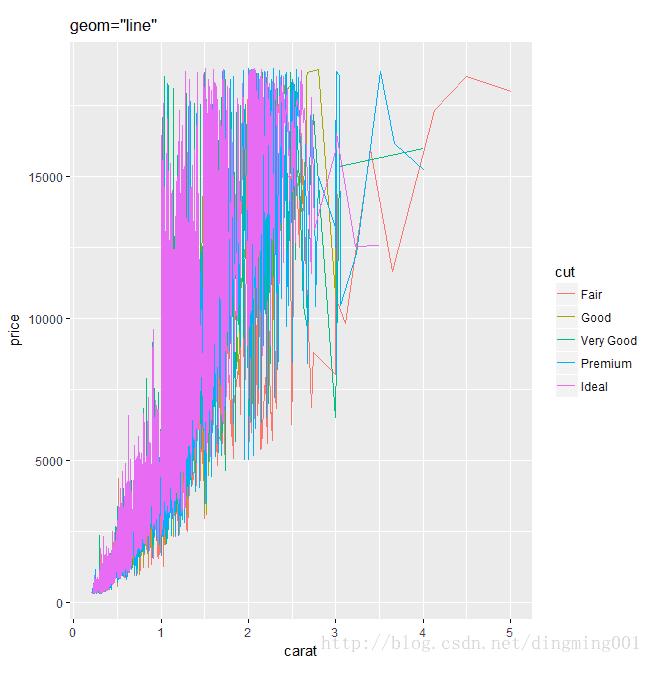
qplot做曲线图
和plot函数一样,qplot也可以通过设置合适的参数产生曲线图,这个参数就是geom(几何类型)。图形的组合非常直接,组合表示几何类型的向量即可:
qplot(x=carat, y=price, data=datax, color=cut, geom="line", main="geom=\"line\"")
qplot(x=carat, y=price, data=datax, color=cut, geom=c("line", "point"), main="geom=c(\"line\", \"point\")")
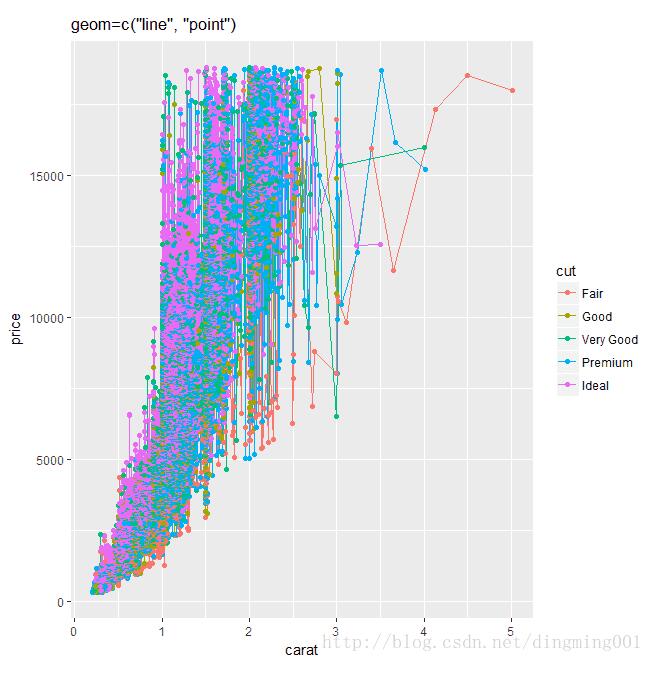
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言 检验多重共线性的操作
函数kappa() df<-data.frame() df_cor=cor(df) kappa(df_cor, exact=T) 当 κ<100κ<100 , 说明共线性程度小: 当 100<κ<1000100<κ<1000 , 有较强的多重共线性: 当 κ>1000κ>1000,存在严重的多重共线性. 函数qr() x<-matrix() qr(x)$rank qr(X)$rank 计算X矩阵的秩,如果不是满秩的,说明其中有xixi可以用其他x
-

R语言 设置ylab每个汉字竖向排列的操作
只看标题可能不知道啥意思,所以先上图了. 从图中可以看到ylab中汉字的排列方式是从上到下的,要实现这样的效果有两个关键步骤: 一是ylab不是常规的"月工作量",而是'月\n工\n作\n量',每个汉字中间要进行换行. 二是要对ylab进行旋转. 下面给出代码: library(ggplot2) #数据 df <- data.frame( gp = factor(rep(letters[1:3], each = 10)), y = rnorm(30) ) #ggplot绘制 p0
-
R语言 title()函数的参数用法说明
如下所示: title(main = NULL, sub = NULL, xlab = NULL, ylab = NULL, line = NA, outer = FALSE, ...) 参数 描述 main 主标题 sub 副标题 xlab x轴标签 ylab y轴标签 line 到轴线的行数距离 outer 一个逻辑值. 如果为TRUE,则标题位于图的外部边缘. 补充:R语言低级绘图函数-title title 函数用来在一张图表上添加标题 基本用法: main 表示主标题,通常位于图像的上
-
R语言 解决无法打开链结的问题
近期,在项目中遇到一个棘手的问题. R脚本在centos服务器上通过"R --no-save filename.R"的方式运行R脚本可以成功,分析结果也可以存入MySQL,该种方式适合算法工程师测试脚本使用. 但是,同样的脚本,在Java后台调用时却失败了. 为了定位问题位置,在脚本内插入很多打印语句,锁定了问题出现在利用RMySQL包将分析结果存入数据库部分,由于Java调用R脚本时R报错信息无法获取,因此又在R脚本中抓取了try函数的执行结果,并存储于自建的R运行日志中. 查看日志
-
R语言 install.packages 无法读取索引的解决方案
问题描述 在公司的Centos服务器上安装R的包,总是安装不成功,然后有如下提醒: Warning: 无法在貯藏處https://mirrors.ustc.edu.cn/CRAN/src/contrib中读写索引 Warning message: package 'DBI' is not available (for R version 3.2.2) 问题修复 [更好的方案请直接看最后边PS] 执行下边这条命令,随便选几个源. setRepositories(addURLs = c(CRANxt
-
R语言 如何保留大于或小于特定数值的行
如下所示: newdata<-subset(x, x$var > 某一数字) x为矩阵 var是其中的一个变量 补充:r语言 循环次数超过了50这个最大值_错过了520还可以一起过儿童节,如何用R语言'撸'一个文字跑马灯去表白... 引言 和大家分享一下如何用R语言来写一个文字跑马灯吧.这个文字跑马灯写起来基本不费时间,在办公室摸一下鱼大概就够了. 正文 这个文字跑马灯我准备按照面向对象编程来写.因为,面向对象就会有对象.而且,这个东西写出来就是拿给你们去表白的. 首先我们定义一个基类,这个基
-
R语言柱状图排序和x轴上的标签倾斜操作
R语言做柱状图大致有两种方法, 一种是基础库里面的 barplot函数, 另一个就是ggplot2包里面的geom_bar 此处用的是字符变量 统计其各频数,然后做出其柱状图.(横轴上的标签显示不全) t <- sort(table(dat1$L), decreasing = TRUE) #将频数表进行排序 r <- barplot(t, col = "blue", main = "柱状图", ylim = c(0,12), names.arg = di
-
R语言中qplot()函数的用法说明
ggplot2()函数 ggplot2是一个强大的作图工具,它可以让你不受现有图形类型的限制,创造出任何有助于解决你所遇到问题的图形. qplot() qplot()属于ggplot2(),可以理解成是它的简化版本. qplot 即"快速作图"(quick plot),顾名思义,能快速对数据进行可视化分析.它的用法和R base包的plot函数很相似. qplot() 参数 qplot(x, y = NULL, ..., data, facets = NULL, margins = F
-
R语言中cut()函数的用法说明
R语言cut()函数使用 cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码. 参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数. breaks采用fivenum():返回五个数据:最小值.下四分位数.中位数.上四分位数.最大值. labels为区间数,打标签 ordered_result 逻辑结果应该是一个有序的因素吗? 先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采用(]的区间,
-
R语言中quantile()函数的用法说明
在R语言中取百分位比用quantile()函数,下面举几个简单的示例: 1.求某个百分位比 > data <- c(1,2,3,4,5,6,7,8,9,10) > quantile(data,0.5) 50% 5.5 > quantile(data,c(0.25,0.75)) 25% 75% 3.25 7.75 2.产生一个序列百分位比值 > quantile(data,seq(0.1,1,0.1)) 10% 20% 30% 40% 50% 60% 70% 80% 90% 1
-
R语言中c()函数与paste()函数的区别说明
c()函数:将括号中的元素连接起来,并不创建向量 paste()函数:连接括号中的元素 例如 c(1, 2:4),结果为1 2 3 4 paste(1, 2:4),结果为"1 2" "1 3" "1 4" c(2, "and"),结果为"2" "and" paste(2, "and"),结果为"2 and" 补充:R语言中paste函数的参数sep
-
C语言中memcpy 函数的用法详解
C语言中memcpy 函数的用法详解 memcpy(内存拷贝函数) c和c++使用的内存拷贝函数,memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中. void* memcpy(void* destination, const void* source, size_t num); void* dest 目标内存 const void* src 源内存 size_t num 字节个数 库中实现的memcpy函数 struct { ch
-
C语言中qsort函数的用法实例详解
C语言中qsort函数的用法实例详解 快速排序是一种用的最多的排序算法,在C语言的标准库中也有快速排序的函数,下面说一下详细用法. qsort函数包含在<stdlib.h>中 qsort函数声明如下: void qsort(void * base,size_t nmemb,size_t size ,int(*compar)(const void *,const void *)); 参数说明: base,要排序的数组 nmemb,数组中元素的数目 size,每个数组元素占用的内存空间,可使用si
-
R语言中merge函数详解
1.创建测试数据: name <- c('A','B','A','A','C','D') school <- c('s1','s2','s1','s1','s1','s3') class <- c(10, 5, 4, 11, 1, 8) English <- c(85, 50, 90 ,90, 12, 96) w <- data.frame(name, school, class, English) w name <- c('A','B','C','F') school
-
聊聊R语言中Legend 函数的参数用法
如下所示: legend(x, y = NULL, legend, fill = NULL, col = par("col"), border = "black", lty, lwd, pch, angle = 45, density = NULL, bty = "o", bg = par("bg"), box.lwd = par("lwd"), box.lty = par("lty")
-
R语言中assign函数和get函数的用法
assign函数在循环时候,给变量赋值,算是比较方便 1.给变量赋值 for (i in 1:(length(rowSeq)-1)){ assign(paste("nginx_server_fields7_", i, sep = ""), nginx_server_fields7[(rowSeq[(i-1)+1]):(rowSeq[i+1]), ]) } 2.通过for循环给变量a1.a2.a3赋值 for (i in 1:3){ assign(paste(&quo
-
R语言中igraph包的用法(邻接矩阵)
先导入igraph包: library(igraph) graph包最简单的用法就是graph方法,两句代码就完成绘制如下所示,1的loop表示为(1,1),1和2之间有3条edge,表示为(1,2,1,2,1,2) g <- graph(c(1,1,1,2,1,2,1,2,1,5,2,3,2,4,2,5,3,3,3,4,3,4,3,4,4,5),directed = FALSE) plot(g) 如果用顶点的邻接矩阵表示,仍以上图为例: 则对1,1有loop,与2有条edge,与5有一条edg