requests.gPython 用requests.get获取网页内容为空 ’ ’问题
目录
- 一、如何设置headers
- 1、QQ浏览器
- 2、Miscrosft edge
- 二、微软自带浏览器
下面先来看一个例子:
import requests
result=requests.get("http://data.10jqka.com.cn/financial/yjyg/")
result
输出结果:
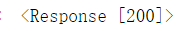
表示成功处理了请求,一般情况下都是返回此状态码; 报200代表没问题

继续运行,发现返回空值,在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
一、如何设置headers
拿两个常用的浏览器举例:
1、QQ浏览器
界面 F12

点击network 键入 CTRL+R

单击第一个 最下边就是我门需要的 把他设置成headers解决问题
2、Miscrosft edge
二、微软自带浏览器
同样 F12 打开开发者工具

点击网络,CTRL+R

前文代码修改:
import requests
ur="http://data.10jqka.com.cn/financial/yjyg/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400 '}
result = requests.get(ur, headers=headers)
result.text
成功解决不能爬取问题
到此这篇关于requests.gPython 用requests.get获取网页内容为空 ’ ’的文章就介绍到这了,更多相关requests.gPython 用requests.get获取网页内容为空 ’ ’内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python requests.get带header
啥也不说了,大家还是直接看图吧! 补充知识:python http request header主要内容 http request 请求头主要包括内容如下: header名 作用 示例 Accept 指定客户端能够接收的内容类型 Accept: text/plain, text/html Accept-Charset 浏览器可以接受的字符编码集. Accept-Charset: iso-8859-5 Accept-Language 浏览器可接受的语言 Accept-Language: en,zh
-

requests.gPython 用requests.get获取网页内容为空 ’ ’问题
目录 一.如何设置headers 1.QQ浏览器 2.Miscrosft edge 二.微软自带浏览器 下面先来看一个例子: import requests result=requests.get("http://data.10jqka.com.cn/financial/yjyg/") result 输出结果: 表示成功处理了请求,一般情况下都是返回此状态码: 报200代表没问题 继续运行,发现返回空值,在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止
-
php使用fsockopen函数发送post,get请求获取网页内容的方法
本文实例讲述了php使用fsockopen函数发送post,get请求获取网页内容的方法.分享给大家供大家参考. 具体实现代码如下: 复制代码 代码如下: $post =1; $url = parse_url($url); $host ='http://www.jb51.net'; $path ='/'; $query ='?action=phpfensi.com'; $port =80; if($post) { $out = "post $path http/1.0 ";
-
php源码 fsockopen获取网页内容实例详解
PHP fsockopen函数说明: Open Internet or Unix domain socket connection(打开套接字链接) Initiates a socket connection to the resource specified by target . fsockopen() returns a file pointer which may be used together with the other file functions (such as fgets(
-
Springboot @Value获取值为空问题解决方案
这篇文章主要介绍了Springboot @Value获取值为空问题解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在spring中,常常使用 @Value("${property}") 从application.properties中取值,需要注意两点 使用 @Value 的类不能使用 new 关键字进行实例化对象,必须采用 依赖注入的方式进行实例化 不能使用显式的构造方法 否则,将取不到值.解决方法如下: 删除显式的构造方法
-
Java getParameter()获取数据为空的问题
目录 JavagetParameter()获取数据为空 说下场景 req.getparameter获取的数据为null 问题分析 Java getParameter()获取数据为空 说下场景 我需要前端传一个数组到后端接口中去处理,但是一直传输不成功. 刚开始getParameter()方法一直获取数据为null,我就在想是哪块有问题,用了各种方法, 然后转化思路,是不是前端传值有问题,debugger下,数据没问题,然后看请求数据,结果发现是前端传进来的一个数组被分为3个键值对 于是在调用接口
-
php curl获取网页内容(IPV6下超时)的解决办法
原因:在程序中我对curl获取内容都作了较为严格的超时限制,所以就会造成无法获取内容的问题. 解决方法:设置默认访问为ipv4.php的curl设置方法如下: 复制代码 代码如下: <?php/*** IPV6下curl超时问题*/$ch = curl_init();curl_setopt ($ch, CURLOPT_URL, $url);curl_setopt ($ch, CURLOPT_RETURNTRANSFER, true);//设置curl默认访问为IPv4if(defined('CU
-
Python使用selenium + headless chrome获取网页内容的方法示例
使用python写爬虫时,优选selenium,由于PhantomJS因内部原因已经停止更新,最新版的selenium已经使用headless chrome替换掉了PhantomJS,所以建议将selenium更新到最新版,使用selenium + headless chrome 准备工作: 安装chrome.chrome driver.selenium 一.安装chrome 配置yum下载源,在目录/etc/yum.repos.d/下新建文件google-chrome.repo > cd /e
-
XMLHttp ASP远程获取网页内容代码
复制代码 代码如下: url="http://www.csdn.net/" wstr=getHTTPPage(url) start=Newstring(wstr,"资源精选<!-- 下载 -->") over=Newstring(wstr,"<div class=""friendlink"">") body=mid(wstr,200,500) response.write body
-
php获取网页内容方法总结
抓取到的内容在通过正则表达式做一下过滤就得到了你想要的内容,至于如何用正则表达式过滤,在这里就不做介绍了,有兴趣的,以下就是几种常用的用php抓取网页中的内容的方法.1.file_get_contents PHP代码 复制代码 代码如下: <?php $url = "http://www.jb51.net"; $contents = file_get_contents($url); //如果出现中文乱码使用下面代码 //$getcontent = iconv("gb23
-
Python抓取数据到可视化全流程的实现过程
目录 1.爬取目标网站:业绩预告_数据中心_同花顺财经 2.获取序号.股票代码.等你所需要的信息 3.组成DataFrame 4.处理数据 1.爬取目标网站:业绩预告_数据中心_同花顺财经 (ps:headers不会设置的可以看这篇:Python 用requests.get获取网页内容为空 ’ ’) import pandas as pd import numpy as np import matplotlib.pyplot as plt import re import requests##把