sql server 交集,差集的用法详解
概述
为什么使用集合运算:
在集合运算中比联接查询和EXISTS/NOT EXISTS更方便。
并集运算(UNION)
并集:两个集合的并集是一个包含集合A和B中所有元素的集合。
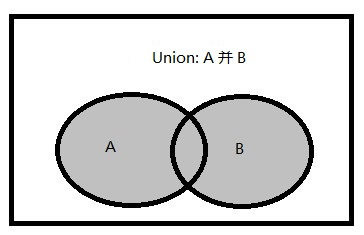
在T-SQL中。UNION集合运算可以将两个输入查询的结果组合成一个结果集。需要注意的是:如果一个行在任何一个输入集合中出现,它也会在UNION运算的结果中出现。T-SQL支持以下两种选项:
(1)UNION ALL:不会删除重复行
-- union allselect country, region, city from hr.Employees union all select country, region, city from sales.Customers;
(2)UNION:会删除重复行
-- union select country, region from hr.Employees union select country, region from sales.Customers;
交集运算(INTERSECT)
交集:两个集合(记为集合A和集合B)的交集是由既属于A,也属于B的所有元素组成的集合。

在T-SQL中,INTERSECT集合运算对两个输入查询的结果取其交集,只返回在两个查询结果集中都出现的行。
INTERSECT集合运算在逻辑上会首先删除两个输入集中的重复行,然后返回只在两个集合中中都出现的行。换句话说:如果一个行在两个输入集中都至少出现一次,那么交集返回的结果中将包含这一行。
例如,下面返回既是雇员地址,又是客户地址的不同地址:
-- intersect select country, region, city from hr.Employees intersect select country, region, city from sales.Customers;
这里需要说的是,集合运算对行进行比较时,认为两个NULL值相等,所以就返回该行记录。
差集运算(EXCEPT)
差集:两个集合(记为集合A和集合B)的由属于集合A,但不属于集合B的所有元素组成的集合。
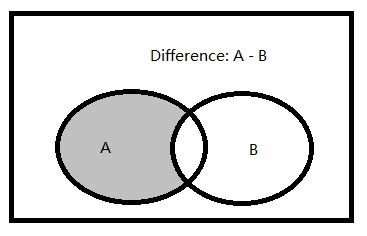
在T-SQL中,集合之差使用EXCEPT集合运算实现的。它对两个输入查询的结果集进行操作,反会出现在第一个结果集中,但不出现在第二个结果集中的所有行。
EXCEPT结合运算在逻辑上首先删除两个输入集中的重复行,然后返回只在第一个集合中出现,在第二个结果集中不出现的所有行。换句话说:一个行能够被返回,仅当这个行在第一个输入的集合中至少出现过一次,而且在第二个集合中一次也没出现过。
此外,相比UNION和INTERSECT,两个输入集合的顺序是会影响到最后返回结果的。
例如,借助EXCEPT运算,我们可以方便地实现属于A但不属于B的场景,下面返回属于员工抵制,但不属于客户地址的地址记录:
-- except select country, region, city from hr.Employees except select country, region, city from sales.Customers;
集合运算优先级

SQL定义了集合运算之间的优先级:INTERSECT最高,UNION和EXCEPT相等。
换句话说:首先会计算INTERSECT,然后按照从左至右的出现顺序依次处理优先级相同的运算。
-- 集合运算的优先级 select country, region, city from Production.Suppliers except select country, region, city from hr.Employees intersect select country, region, city from sales.Customers;
上面这段SQL代码,因为INTERSECT优先级比EXCEPT高,所以首先进行INTERSECT交集运算。因此,这个查询的含义是:返回没有出现在员工地址和客户地址交集中的供应商地址。
集合运算的优先级
1.INTERSECT>UNION=EXCEPT
2.首先计算INTERSECT,然后从左到右的出现顺序依次处理优先级的相同的运算。
3.可以使用圆括号控制集合运算的优先级,它具有最高的优先级。
在排序函数的OVER字句中使用ORDER BY ( SELECT <常量> )可以告诉SQL Server不必在意行的顺序。
使用表表达式避开不支持的逻辑查询处理
集合运算查询本身并不持之除ORDER BY意外的其他逻辑查询处理阶段,但可以通过表表达式来避开这一限制。
解决方案就是:首先根据包含集合运算的查询定义一个表表达式,然后在外部查询中对表表达式应用任何需要的逻辑查询处理。
(1)例如,下面的查询返回每个国家中不同的员工地址或客户地址的数量:
select country, COUNT(*) as numlocations from (select country, region, city from hr.Employees union select country, region, city from sales.Customers) as Ugroup by country;
(2)例如,下面的查询返回由员工地址为3或5的员工最近处理过的两个订单:、
select empid,orderid,orderdate from (select top (2) empid,orderid,orderdate from sales.Orders where empid=3 order by orderdate desc,orderid desc) as D1 union all select empid,orderid,orderdate from (select top (2) empid,orderid,orderdate from sales.Orders where empid=5 order by orderdate desc,orderid desc) as D2;
到此这篇关于sql server 交集,差集的用法详解的文章就介绍到这了,更多相关sql server 交集,差集 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SQLServer中求两个字符串的交集
使用javascript的数组来计算,代码如下: 复制代码 代码如下: use tempdb go if (object_id ('fn_getArray' ) is not null ) drop function dbo . fn_getArray go create function fn_getArray (@ inStr1 varchar (8000 ), @ inStr2 varchar (8000 )) returns varchar (8000 ) as begin declar
-

SQLServer 数据集合的交、并、差集运算
他们的对应关系可以参考下面图示相关测试实例如下: 相关测试实例如下: 复制代码 代码如下: use tempdb go if (object_id ('t1' ) is not null ) drop table t1 if (object_id ('t2' ) is not null ) drop table t2 go create table t1 (a int ) insert into t1 select 1 union select 2 union select 3 create
-
sql server 交集,差集的用法详解
概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便. 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合. 在T-SQL中.UNION集合运算可以将两个输入查询的结果组合成一个结果集.需要注意的是:如果一个行在任何一个输入集合中出现,它也会在UNION运算的结果中出现.T-SQL支持以下两种选项: (1)UNION ALL:不会删除重复行 -- union allselect country, region, city fr
-
SQL Server时间戳功能与用法详解
本文实例讲述了SQL Server时间戳功能与用法.分享给大家供大家参考,具体如下: 一直对时间戳这个概念比较模糊,相信有很多朋友也都会误认为:时间戳是一个时间字段,每次增加数据时,填入当前的时间值.其实这误导了很多朋友. 1.基本概念 时间戳:数据库中自动生成的唯一二进制数字,与时间和日期无关的, 通常用作给表行加版本戳的机制.存储大小为 8个字节. 每个数据库都有一个计数器,当对数据库中包含 timestamp 列的表执行插入或更新操作时,该计数器值就会增加.该计数器是数据库时间戳.这 可以
-
SQL Server UPDATE语句的用法详解
SQL Server UPDATE语句用于更新数据,下面就为您详细介绍SQL Server UPDATE语句语法方面的知识,希望可以让您对SQL Server UPDATE语句有更多的了解. 现实应用中数据库中的数据改动是免不了的.通常,几乎所有的用户数据库中的大部分数据都要进行某种程度的修改.在SQL Server数据库中要想修改数据库记录,就需要用UPDATE语句,UPDATE语句就是为了改变数据库中的现存数据而存在的.这条语句虽然有一些复杂的选项,但确实是最容易学习的语句之一.这是因为在大
-
SQL Server中索引的用法详解
目录 一.索引的介绍 什么是索引? 1.聚集索引和非聚集索引 2.索引的利弊 3.索引的存储机制 二.设置索引的权衡 1.什么情况下设置索引 2.什么情况下不要设置索引 三.聚集索引 1.使用SSMS创建聚集索引 2.使用T-SQL创建聚集索引 四.非聚集索引 1.SSMS创建方法同上,T-SQL创建方法如下: 2.添加索引选项 五.示例 六.管理索引 一.索引的介绍 什么是索引? 索引是一种磁盘上的数据结构,建立在表或视图的基础上.使用索引可以使数据的获取更快更高校,也会影响其他的一些性能,如
-
SQL Server 2012 FileTable 新特性详解
FileTable是基于FILESTREAM的一个特性.有以下一些功能: •一行表示一个文件或者目录. •每行包含以下信息: • •file_Stream流数据,stream_id标示符(GUID). •用户表示和维护文件及目录层次关系的path_locator和parent_path_locator •有10个文件属性 •支持对文件和文档的全文搜索和语义搜索的类型列. •filetable强制执行某些系统定义的约束和触发器来维护命名空间的语义 •针对非事务访问时,SQL Server配置FIL
-
MyBatis动态Sql之if标签的用法详解
最近在读刘增辉老师所著的<MyBatis从入门到精通>一书,很有收获,于是将自己学习的过程以博客形式输出,如有错误,欢迎指正,如帮助到你,不胜荣幸! 本篇博客主要讲解如何使用if标签生成动态的Sql,主要包含以下3个场景: 1.根据查询条件实现动态查询 2.根据参数值实现动态更新某些列 3.根据参数值实现动态插入某些列 1. 使用if标签实现动态查询 假设有这样1个需求:根据用户的输入条件来查询用户列表,如果输入了用户名,就根据用户名模糊查询,如果输入了邮箱,就根据邮箱精确查询,如果同时输入了
-
SQL Server批量插入数据案例详解
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题.下面介绍SQL Server支持的两种批量数据插入方法:Bulk和表值参数(Table-Valued Parameters),高效插入数据. 新建数据库: --Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create tab
-
SQL Server实现全文搜索查询详解
目录 一.概述 二.全文搜索查询 三.将全文搜索查询与 LIKE 谓词进行比较 四.全文搜索体系结构 4.1.SQL Server 进程 4.2.过滤器守护程序主机进程 五.全文搜索处理 5.1.全文索引过程 5.2.全文查询流程 六.全文索引体系结构 6.1.全文索引结构 6.2.全文索引片段 6.3.全文索引和常规 SQL Server 索引之间的差异 总结 一.概述 全文索引在表中包括一个或多个基于字符的列.这些列可以具有以下任何数据类型:char.varchar.nchar.nvarch
-
SQL Server的行级安全性详解
目录 一.前言 二.描述 三.权限 四.安全说明:侧信道攻击 五.跨功能兼容性 六.示例 一.前言 行级别安全性使您能够使用组成员身份或执行上下文来控制对数据库表中行的访问. 行级别安全性 (RLS) 简化了应用程序中的安全性设计和编码.RLS 可帮助您对数据行访问实施限制.例如,您可以确保工作人员仅访问与其部门相关的数据行.另一个示例是将客户的数据访问限制为仅与其公司相关的数据. 访问限制逻辑位于数据库层中,而不是远离另一个应用程序层中的数据.每次尝试从任何层访问数据时,数据库系统都会应用访问
-
sql server 自定义分割月功能详解及实现代码
在最近的项目开发过程中,遇到了Sql server自动分割月的功能需求,这里在网上整理下资料. 1.为何出现自定义分割月的需求 今天梳理一个平台的所有函数时,发现了一个自定义分割月函数,也就是指定分割月的开始日索引值(可以从1-31闭区间内的任何一个值)来获取指定日期所对应的分割月数值.这个函数当时是为了解决业务部门获取非标准月(标准月就是从每个月的第一天到最后一天组成一个完成的标准月份)的统计汇总数据的.例如:如果指定分割月的开始日索引值为5则表示某个月的5号到下个月的4号之间作为一个完整的分