Python爬虫教程知识点总结
一、为什么使用Python进行网络爬虫?
由于Python语言十分简洁,使用起来又非常简单、易学,通过Python 进行编写就像使用英语进行写作一样。另外Python 在使用中十分方便,并不需要IDE,而仅仅通过sublime text 就能够对大部分的中小应用进行开发;除此之外Python 爬虫的框架功能十分强大,它的框架能够对网络数据进行爬取,还能对结构性的数据进行提取,经常用在数据的挖掘、历史数据的存储和信息的处理等程序内;Python网络的支持库和html的解析器功能十分强大,借助网络的支持库通过较少代码的编写,就能够进行网页的下载,且通过网页的解析库就能够对网页内各标签进行解析,和正则的表达式进行结合,
十分便于进行网页内容的抓取。所以Python在网络爬虫网面有很大的优势。
二、判断网站数据是否支持爬取
几乎每个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定robots.txt。如果网站没有设定 robots.txt 就可以通过网络爬虫获取没有口令加密的数据,也就是这个网站所有页面数据都可以爬取。当然如果网站有 robots.txt 文档,就要判断是否有禁止访客获取的数据。
以淘宝网为例,在浏览器中访问 https://www.taobao.com/robots.txt,如图所示。

上图淘宝网的robots.txt文件内容
淘宝网允许部分爬虫访问它的部分路径,而对于没有得到允许的用户,则全部禁止爬取,代码如下:
User-Agent:* Disallow:/ 12
这一句代码的意思是除前面指定的爬虫外,不允许其他爬虫爬取任何数据。
三、requests 库抓取网站数据
1.如何安装 requests 库
1.首先在 PyCharm 中安装 requests 库
2.打开 PyCharm,单击“File”(文件)菜单
3.选择“Setting for New Projects…”命令
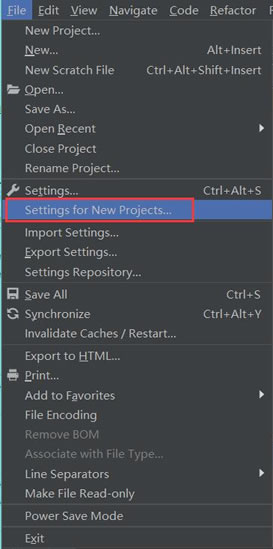
4.选择“Project Interpreter”(项目编译器)命令
5.确认当前选择的编译器,然后单击右上角的加号。
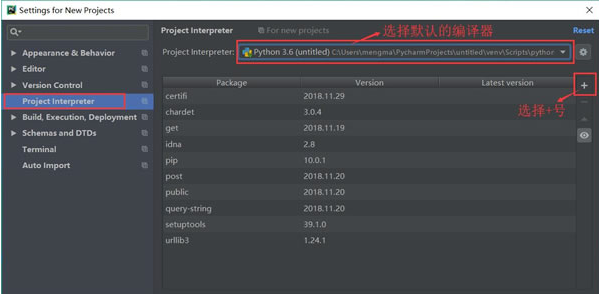
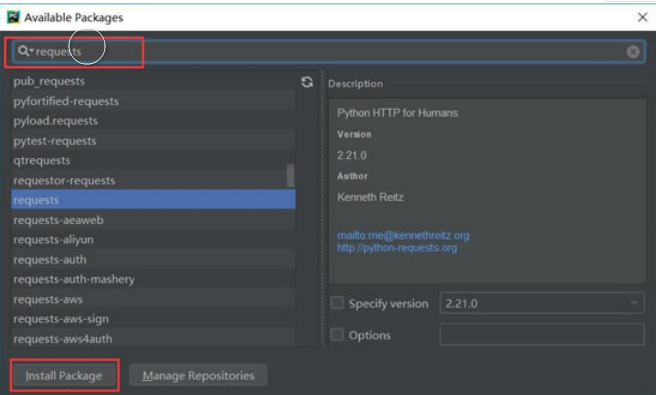
6.在搜索框输入:requests(注意,一定要输入完整,不然容易出错),然后单击左下角的“Install Package”(安装库)按钮。
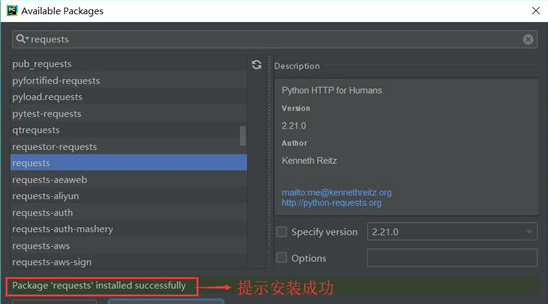
安装完成后,会在 Install Package 上显示“Package‘requests' installed successfully”(库的请求已成功安装),如果安装不成功将会显示提示信息。
四、爬虫的基本原理
网页请求的过程分为两个环节:
- Request (请求):每一个展示在用户面前的网页都必须经过这一步,也就是向服务器发送访问请求。
- Response(响应):服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容,客户端接收服务器响应的内容,将内容展示出来,就是我们所熟悉的网页请求
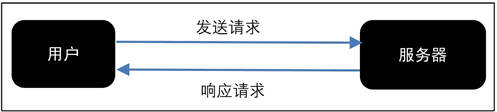
网页请求的方式也分为两种:
- GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
- POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
所以,在写爬虫前要先确定向谁发送请求,用什么方式发送。
五、使用 GET 方式抓取数据
复制任意一条首页首条新闻的标题,在源码页面按【Ctrl+F】组合键调出搜索框,将标题粘贴在搜索框中,然后按【Enter】键。
标题可以在源码中搜索到,请求对象是www.cntour.cn,请求方式是GET(所有在源码中的数据请求方式都是GET),如图 9所示。
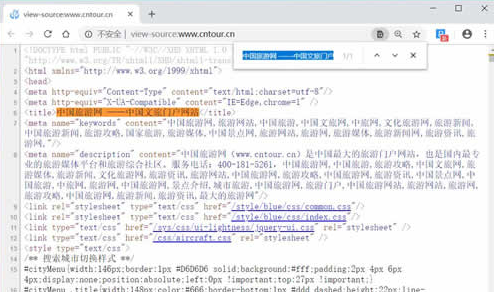
确定好请求对象和方式后,在 PyCharm 中输入以下代码:
import requests #导入requests包 url = 'http://www.cntour.cn/' strhtml = requests.get(url) #Get方式获取网页数据 print(strhtml.text) 1234

加载库使用的语句是 import+库的名字。在上述过程中,加载 requests 库的语句是:import requests。
用 GET 方式获取数据需要调用 requests 库中的 get 方法,使用方法是在 requests 后输入英文点号,如下所示:
requests.get 1
将获取到的数据存到 strhtml 变量中,代码如下:
strhtml = request.get(url) 1
这个时候 strhtml 是一个 URL 对象,它代表整个网页,但此时只需要网页中的源码,下面的语句表示网页源码:
strhtml.text 1
六、使用 POST 方式抓取数据
首先输入有道翻译的网址:http://fanyi.youdao.com/,进入有道翻译页面。
按快捷键 F12,进入开发者模式,单击 Network,此时内容为空,如图所示:

在有道翻译中输入“我爱中国”,单击“翻译”按钮
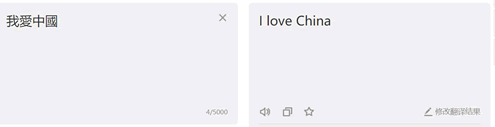
在开发者模式中,依次单击“Network”按钮和“XHR”按钮,找到翻译数据
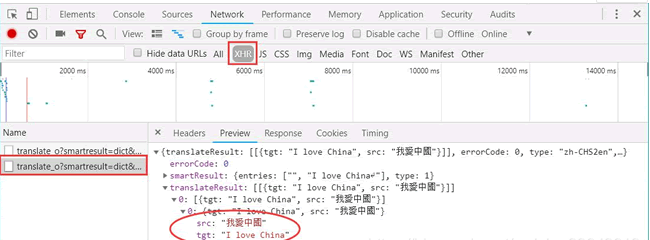
单击 Headers,发现请求数据的方式为 POST。
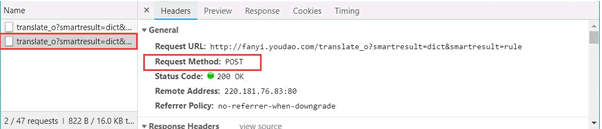
找到数据所在之处并且明确请求方式之后,接下来开始撰写爬虫。
首先,将 Headers 中的 URL 复制出来,并赋值给 url,代码如下:
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' 1
POST 的请求获取数据的方式不同于 GET,POST 请求数据必须构建请求头才可以。
Form Data 中的请求参数如图
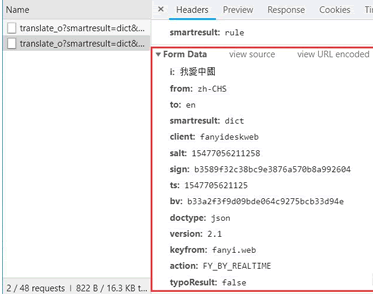
将其复制并构建一个新字典:
From_data={'i':'我愛中國','from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
1
将字符串格式的数据转换成 JSON 格式数据,并根据数据结构,提取数据,并将翻译结果打印出来,代码如下:
import json content = json.loads(response.text) print(content['translateResult'][0][0]['tgt']) 123
使用 requests.post 方法抓取有道翻译结果的完整代码如下:
import requests #导入requests包
import json
def get_translate_date(word=None):
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
From_data={'i':word,'from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
#请求表单数据
response = requests.post(url,data=From_data)
#将Json格式字符串转字典
content = json.loads(response.text)
print(content)
#打印翻译后的数据
#print(content['translateResult'][0][0]['tgt'])
if __name__=='__main__':
get_translate_date('我爱中国')
1234567891011121314
七、使用 Beautiful Soup 解析网页
通过 requests 库已经可以抓到网页源码,接下来要从源码中找到并提取数据。Beautiful Soup 是 python 的一个库,其最主要的功能是从网页中抓取数据。Beautiful Soup 目前已经被移植到 bs4 库中,也就是说在导入 Beautiful Soup 时需要先安装 bs4 库。
安装 bs4 库的方式如图 所示:
安装好 bs4 库以后,还需安装 lxml 库。如果我们不安装 lxml 库,就会使用 Python 默认的解析器。尽管 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器又支持一些第三方解析器,但是 lxml 库具有功能更加强大、速度更快的特点,因此笔者推荐安装 lxml 库。
安装 Python 第三方库后,输入下面的代码,即可开启 Beautiful Soup 之旅:
import requests #导入requests包
from bs4 import BeautifulSoup
url='http://www.cntour.cn/'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#main>div>div.mtop.firstMod.clearfix>div.centerBox>ul.newsList>li>a')
print(data)
1234567
代码运行结果如图。
Beautiful Soup 库能够轻松解析网页信息,它被集成在 bs4 库中,需要时可以从 bs4 库中调用。其表达语句如下:
from bs4 import BeautifulSoup 1
首先,HTML 文档将被转换成 Unicode 编码格式,然后 Beautiful Soup 选择最合适的解析器来解析这段文档,此处指定 lxml 解析器进行解析。解析后便将复杂的 HTML 文档转换成树形结构,并且每个节点都是 Python 对象。这里将解析后的文档存储到新建的变量 soup 中,代码如下:
soup=BeautifulSoup(strhtml.text,'lxml') 1
接下来用 select(选择器)定位数据,定位数据时需要使用浏览器的开发者模式,将鼠标光标停留在对应的数据位置并右击,然后在快捷菜单中选择“检查”命令
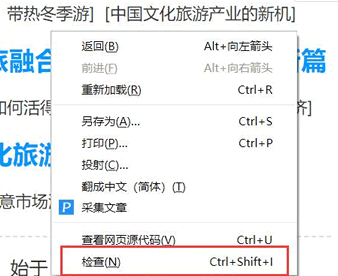
随后在浏览器右侧会弹出开发者界面,右侧高亮的代码(参见图 19(b))对应着左侧高亮的数据文本(参见图 19(a))。右击右侧高亮数据,在弹出的快捷菜单中选择“Copy”➔“Copy Selector”命令,便可以自动复制路径。
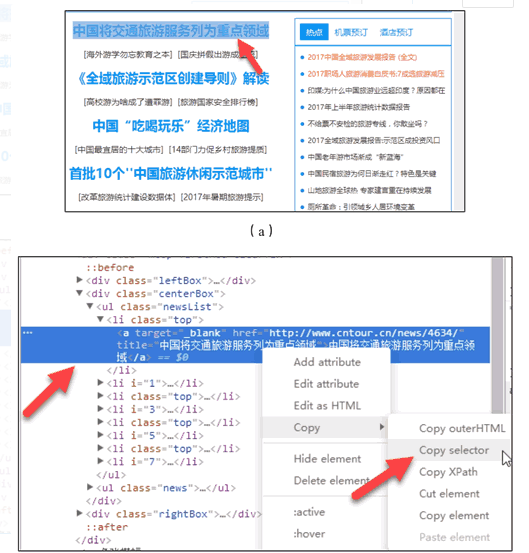
将路径粘贴在文档中,代码如下:
#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a 1
由于这条路径是选中的第一条的路径,而我们需要获取所有的头条新闻,因此将 li:nth-child(1)中冒号(包含冒号)后面的部分删掉,代码如下:
#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a 1
使用 soup.select 引用这个路径,代码如下:
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
1
八、清洗和组织数据
至此,获得了一段目标的 HTML 代码,但还没有把数据提取出来,接下来在 PyCharm 中输入以下代码:纯文本复制
for item in data:
result={
'title':item.get_text(),
'link':item.get('href')
}
print(result)
123456
代码运行结果如图 所示:
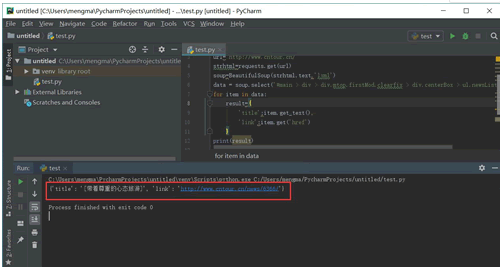
首先明确要提取的数据是标题和链接,标题在<a>标签中,提取标签的正文用 get_text() 方法。链接在<a>标签的 href 属性中,提取标签中的 href 属性用 get() 方法,在括号中指定要提取的属性数据,即 get('href')。
从图 20 中可以发现,文章的链接中有一个数字 ID。下面用正则表达式提取这个 ID。需要使用的正则符号如下:\d匹配数字+匹配前一个字符1次或多次
在 Python 中调用正则表达式时使用 re 库,这个库不用安装,可以直接调用。在 PyCharm 中输入以下代码:
import re
for item in data:
result={
"title":item.get_text(),
"link":item.get('href'),
'ID':re.findall('\d+',item.get('href'))
}
print(result)
12345678
运行结果如图 所示:
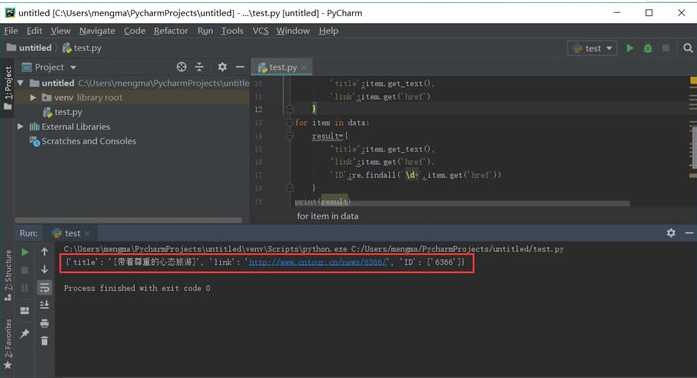
这里使用 re 库的 findall 方法,第一个参数表示正则表达式,第二个参数表示要提取的文本。
九.爬虫攻防战
爬虫是模拟人的浏览访问行为,进行数据的批量抓取。当抓取的数据量逐渐增大时,会给被访问的服务器造成很大的压力,甚至有可能崩溃。换句话就是说,服务器是不喜欢有人抓取自己的数据的。那么,网站方面就会针对这些爬虫者,采取一些反爬策略。
服务器第一种识别爬虫的方式就是通过检查连接的 useragent 来识别到底是浏览器访问,还是代码访问的。如果是代码访问的话,访问量增大时,服务器会直接封掉来访 IP。
那么应对这种初级的反爬机制,我们应该采取何种举措?
还是以前面创建好的爬虫为例。在进行访问时,我们在开发者环境下不仅可以找到 URL、Form Data,还可以在 Request headers 中构造浏览器的请求头,封装自己。服务器识别浏览器访问的方法就是判断 keyword 是否为 Request headers 下的 User-Agent,如图:
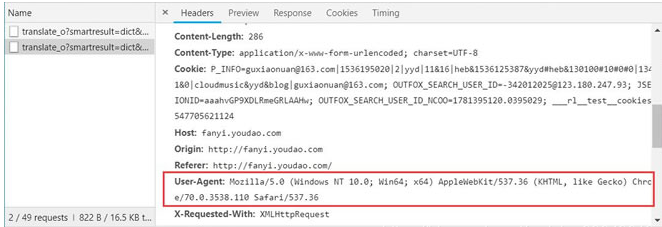
因此,我们只需要构造这个请求头的参数。创建请求头部信息即可,代码如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
response = request.get(url,headers=headers)
12
写到这里,很多读者会认为修改 User-Agent 很太简单。确实很简单,但是正常人1秒看一个图,而个爬虫1秒可以抓取好多张图,比如 1 秒抓取上百张图,那么服务器的压力必然会增大。也就是说,如果在一个 IP 下批量访问下载图片,这个行为不符合正常人类的行为,肯定要被封 IP。
其原理也很简单,就是统计每个IP的访问频率,该频率超过阈值,就会返回一个验证码,如果真的是用户访问的话,用户就会填写,然后继续访问,如果是代码访问的话,就会被封 IP。
这个问题的解决方案有两个,第一个就是常用的增设延时,每 3 秒钟抓取一次,代码如下:
import time time.sleep(3) 12
但是,我们写爬虫的目的是为了高效批量抓取数据,这里设置 3 秒钟抓取一次,效率未免太低。其实,还有一个更重要的解决办法,那就是从本质上解决问题。
不管如何访问,服务器的目的就是查出哪些为代码访问,然后封锁 IP。解决办法:为避免被封 IP,在数据采集时经常会使用代理。当然,requests 也有相应的 proxies 属性。
到此这篇关于Python爬虫教程知识点总结的文章就介绍到这了,更多相关Python爬虫教程分享内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫教程知识点总结
一.为什么使用Python进行网络爬虫? 由于Python语言十分简洁,使用起来又非常简单.易学,通过Python 进行编写就像使用英语进行写作一样.另外Python 在使用中十分方便,并不需要IDE,而仅仅通过sublime text 就能够对大部分的中小应用进行开发:除此之外Python 爬虫的框架功能十分强大,它的框架能够对网络数据进行爬取,还能对结构性的数据进行提取,经常用在数据的挖掘.历史数据的存储和信息的处理等程序内:Python网络的支持库和html的解析器功能十分强大,借助网络的
-
python爬虫基础知识点整理
首先爬虫是什么? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 根据我的经验,要学习Python爬虫,我们要学习的共有以下几点: Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy Python爬虫更高级的功能 1.Python基础学习 首先,我们要用Python写爬虫,肯定要了解Python的基础吧,万丈高楼平地起,
-

Python爬虫教程之利用正则表达式匹配网页内容
前言 Python爬虫,除了使用大家广为使用的scrapy架构外,还有很多包能够实现一些简单的爬虫,如BeautifulSoup.Urllib.requests,在使用这些包时,有的网络因为比较复杂,比较难以找到自己想要的代码,在这个时候,如果能够使用正则表达式,将能很方便地爬取到自己想要的数据. 何为正则表达式 正则表达式是一种描述字符串排列的一种语法规则,通过该规则可以在一个大字符串中匹配出满足规则的子字符串.简单来说,就是给定了一个字符串,在字符串中找到想要的字符串,如一个电话号码,一个I
-
一个入门级python爬虫教程详解
前言 本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义.组成部分.爬取流程,并讲解示例代码. 基础 爬虫的定义:定向抓取互联网内容(大部分为网页).并进行自动化数据处理的程序.主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料. 今日t条就是一只巨大的"爬虫". 爬虫由URL库.采集器.解析器组成. 流程 如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作. 代码 第一步:写一个采集
-
Python爬虫教程使用Scrapy框架爬取小说代码示例
目录 Scrapy框架简单介绍 创建Scrapy项目 创建Spider爬虫 Spider爬虫提取数据 items.py代码定义字段 fiction.py代码提取数据 pipelines.py代码保存数据 settings.py代码启动爬虫 结果展示 Scrapy框架简单介绍 Scrapy框架是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,是提取结构性数据而编写的应用框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,我们只需要少量的代码就能够快速抓取数据. 其框架如下图
-
python爬虫教程之爬取百度贴吧并下载的示例
测试url:http://tieba.baidu.com/p/27141123322?pn=begin 1end 4 复制代码 代码如下: import string ,urllib2 def baidu_tieba(url,begin_page,end_page): for i in range(begin_page, end_page+1): sName = string.zfill(i,5)+ '.html' print '正在下载第' + str(
-
Python 短视频爬虫教程
好难受,上次发了做游戏的居然没人看,每天为了给你们写啥,老夫心都操碎了~ 真的是,今天来给大家爬一波短视频网站吧,都是些很养眼的~ 网站地址在代码里面,大家用心一下就能看到了. 使用的软件 python 3.8 pycharm 2021.2 模块 requests parsel re concurrent.futures time warnings 不会安装模块看这篇:python模块的安装以及安装失败的解决方法 知道你们不想看那些步骤,我直接上代码吧 import requests impor
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫(入门教程、视频教程) 原创
python的版本经过了python2.x和python3.x等版本,无论哪种版本,关于python爬虫相关的知识是融会贯通的,我们关于爬虫这个方便整理过很多有价值的教程,小编通过本文章给大家做一个关于python爬虫相关知识的总结,以下就是全部内容: python爬虫的基础概述 1.什么是爬虫 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常是首页)开始,读
-
Python爬虫入门教程01之爬取豆瓣Top电影
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一.明确需求 爬取豆瓣Top250排行电影信息 电影名字 导演.主演 年份.国家.类型 评分.评价人数 电影简介 二.发送请求 Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模