详解C++实现匈牙利算法
目录
- 一、匈牙利算法介绍
- 二、最大匹配问题
- 三、最小点覆盖问题
- 四、匈牙利算法的应用
- 4.1、(洛谷P1129) [ZJOI2007]矩阵游戏
- 4.2、(vijos1204) CoVH之柯南开锁
- 4.3、(TYVJ P1035) 棋盘覆盖
一、匈牙利算法介绍
匈牙利算法(Hungarian algorithm)主要用于解决一些与二分图匹配有关的问题,所以我们先来了解一下二分图。
二分图(Bipartite graph)是一类特殊的图,它可以被划分为两个部分,每个部分内的点互不相连。下图是典型的二分图。

可以看到,在上面的二分图中,每条边的端点都分别处于点集X和Y中。匈牙利算法主要用来解决两个问题:求二分图的最大匹配数和最小点覆盖数。
这么说起来过于抽象了,我们现在从实际问题出发。
二、最大匹配问题
看完上面讲的,相信读者会觉得云里雾里的:这是啥?这有啥用?所以我们把这张二分图稍微做点手脚,变成下面这样:
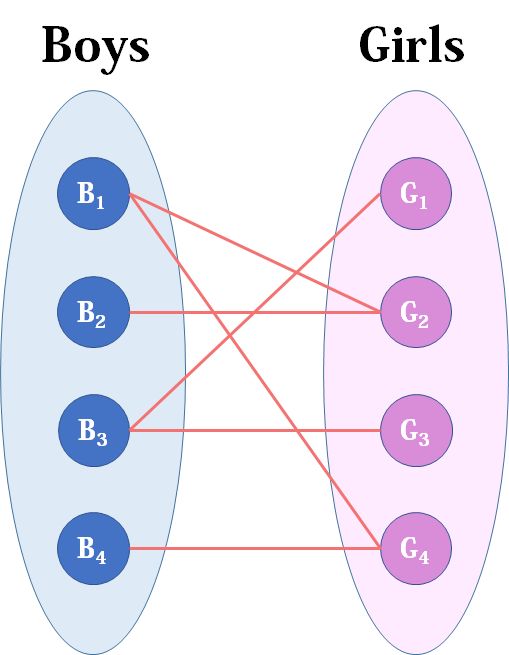
现在Boys和Girls分别是两个点集,里面的点分别是男生和女生,边表示他们之间存在“暧昧关系"。最大匹配问题相当于,假如你是红娘,可以撮合任何一对有暧昧关系的男女,那么你最多能成全多少对情侣?(数学表述:在二分图中最多能找到多少条没有公共端点的边)
现在我们来看看匈牙利算法是怎么运作的:
我们从B1看起(男女平等,从女生这边看起也是可以的),他与G2有暧昧,那我们就先暂时把他与G2连接(注意这时只是你作为一个红娘在纸上构想,你没有真正行动,此时的安排都是暂时的)。

来看B2,B2也喜欢G2,这时G2已经“名花有主”了(虽然只是我们设想的),那怎么办呢?我们倒回去看G2目前被安排的男友,是B1,B1有没有别的选项呢?有,G4,G4还没有被安排,那我们就给B1安排上G4。

然后B3,B3直接配上G1就好了,这没什么问题。至于B4,他只钟情于G4,G4目前配的是B1。B1除了G4还可以选G2,但是呢,如果B1选了G2,G2的原配B2就没得选了。我们绕了一大圈,发现B4只能注定单身了,可怜。(其实从来没被考虑过的G3更可怜)

这就是匈牙利算法的流程,至于具体实现,我们来看看代码:
int M, N; //M, N分别表示左、右侧集合的元素数量
int Map[MAXM][MAXN]; //邻接矩阵存图
int p[MAXN]; //记录当前右侧元素所对应的左侧元素
bool vis[MAXN]; //记录右侧元素是否已被访问过
bool match(int i)
{
for (int j = 1; j <= N; ++j)
if (Map[i][j] && !vis[j]) //有边且未访问
{
vis[j] = true; //记录状态为访问过
if (p[j] == 0 || match(p[j])) //如果暂无匹配,或者原来匹配的左侧元素可以找到新的匹配
{
p[j] = i; //当前左侧元素成为当前右侧元素的新匹配
return true; //返回匹配成功
}
}
return false; //循环结束,仍未找到匹配,返回匹配失败
}
int Hungarian()
{
int cnt = 0;
for (int i = 1; i <= M; ++i)
{
memset(vis, 0, sizeof(vis)); //重置vis数组
if (match(i))
cnt++;
}
return cnt;
}
其实流程跟我们上面描述的是一致的。注意这里使用了一个递归的技巧,我们不断往下递归,尝试寻找合适的匹配。
三、最小点覆盖问题
另外一个关于二分图的问题是求最小点覆盖:我们想找到最少的一些点,使二分图所有的边都至少有一个端点在这些点之中。倒过来说就是,删除包含这些点的边,可以删掉所有边。

这为什么用匈牙利算法可以解决呢?你如果以为我要长篇大论很久就错了,我们只需要一个定理:
(König定理)
一个二分图中的最大匹配数等于这个图中的最小点覆盖数。
好了,本节可以结束了,我们不是搞数学的,不需要证明。但是提供一个直观地找最小覆盖点集的方法:看题图,从左侧一个未匹配成功的点出发,走一趟匈牙利算法的流程(即紫色的箭头),所有左侧未经过的点,和右侧经过的点,即组成最小点覆盖。(即图中的B3、G2、G4)
对于每个左部节点,寻找增广路最多遍历整张二分图一次,因此,该算法时间复杂度为O(MN)
四、匈牙利算法的应用
一些题目,乍一看与上面这个男女配对的问题没有任何相似点,其实都可以用匈牙利算法。例如:
4.1、(洛谷P1129) [ZJOI2007]矩阵游戏
题目描述
小Q是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一个电脑益智游戏――矩阵游戏。矩阵游戏在一个$ N× N $ 黑白方阵进行(如同国际象棋一般,只是颜色是随意的)。每次可以对该矩阵进行两种操作:
行交换操作:选择矩阵的任意两行,交换这两行(即交换对应格子的颜色)
列交换操作:选择矩阵的任意两列,交换这两列(即交换对应格子的颜色)
游戏的目标,即通过若干次操作,使得方阵的主对角线(左上角到右下角的连线)上的格子均为黑色。
对于某些关卡,小Q百思不得其解,以致他开始怀疑这些关卡是不是根本就是无解的!于是小Q决定写一个程序来判断这些关卡是否有解。
输入格式
第一行包含一个整数T,表示数据的组数。
接下来包含T组数据,每组数据第一行为一个整数N,表示方阵的大小;接下来N行为一个 $ N× N $的01矩阵(0表示白色,1表示黑色)。
输出格式
包含T行。对于每一组数据,如果该关卡有解,输出一行Yes;否则输出一行No。
我们把矩阵转化为二分图(左侧集合代表各行,右侧集合代表各列,某位置为1则该行和该列之间有边)。我们想进行一系列交换操作,使得X1连上Y1,X2连上Y2,……
大家可以想象,所谓的交换,是不是可以等价为重命名?我们可以在保持当前二分图结构不变的情况下,把右侧点的编号进行改变,这与交换的效果是一样的。

所以想让X1、X2...与Y1、Y2...一一对应,其实只需要原图最大匹配数为4就行了。(这与组合数学中相异代表系的概念相合)。代码如下:
#include <cstdio>
#include <cstring>
int Map[205][205], p[205], vis[205], N, T;
bool match(int i){
for (int j = 1; j <= N; ++j){
if (Map[i][j] && !vis[j]){
vis[j] = 1;
if (p[j] == 0 || match(p[j])){
p[j] = i;
return true;
}
}
}
return false;
}
int Hungarian(){
int cnt = 0;
for (int i = 1; i <= N; ++i){
memset(vis, 0, sizeof(vis));
if (match(i))
cnt++;
}
return cnt;
}
int main(){
scanf("%d", &T);
while (T--){
scanf("%d", &N);
memset(p, 0, sizeof(p));
for (int i = 1; i <= N; ++i)
for (int j = 1; j <= N; ++j)
scanf("%d", &Map[i][j]);
puts(Hungarian() == N ? "Yes" : "No");
}
return 0;
}
4.2、(vijos1204) CoVH之柯南开锁
面对OIBH组织的嚣张气焰, 柯南决定深入牛棚, 一探虚实.
他经过深思熟虑, 决定从OIBH组织大门进入...........
OIBH组织的大门有一个很神奇的锁.
锁是由M*N个格子组成, 其中某些格子凸起(灰色的格子). 每一次操作可以把某一行或某一列的格子给按下去.

如果柯南能在组织限定的次数内将所有格子都按下去, 那么他就能够进入总部. 但是OIBH组织不是吃素的, 他们的限定次数恰是最少次数.
请您帮助柯南计算出开给定的锁所需的最少次数.
读入/Input:
第一行 两个不超过100的正整数N, M表示矩阵的长和宽
以下N行 每行M个数 非0即1 1为凸起方格输出/Output:
一个整数 所需最少次数
如果我们把样例的矩阵,转化为二分图的形式,是这样的:

按下一行或一列,其实就是删掉与某个点相连的所有边。现在要求最少的操作次数,想想看,这不就是求最小点覆盖数吗?所以直接套匈牙利算法即可。代码略。
4.3、(TYVJ P1035) 棋盘覆盖
描述 Description
给出一张nn(n<=100)的国际象棋棋盘,其中被删除了一些点,问可以使用多少12的多米诺骨牌进行掩盖。
输入格式 Input Format
第一行为n,m(表示有m个删除的格子)
第二行到m+1行为x,y,分别表示删除格子所在的位置
x为第x行
y为第y列
输出格式 Output Format
一个数,即最大覆盖格数
经典的多米诺覆盖问题大家都很熟悉,我们把棋盘染色,每个多米诺骨牌恰好覆盖一个白格和一个黑格(这里为了美观染成了其他颜色,下面仍将其称作黑格)。

我们删除了一些格子:

现在要求多米诺骨牌最大覆盖数。
你可能已经看出来了,我们在染色之后,黑格和白格可以构成一个二分图,每个白格都只和黑格相连,每个黑格也只和白格相连。在给所有黑格和白格编号后,我们把每个未删除的格子都与它上下左右紧邻的未删除的格子相连。很显然,这张二分图的最大匹配数,就是我们能放下最多的多米诺骨牌数。注意因为数据范围较大,要用邻接表存图。
#include <cstdio>
#include <cstring>
#define MAXN 5500
struct Edges
{
int to, next;
} edges[MAXN * 8];
int Map[105][105], head[MAXN], p[MAXN], vis[MAXN], N, cnt_edge;
inline int add(int from, int to)
{
edges[++cnt_edge].next = head[from];
head[from] = cnt_edge;
edges[cnt_edge].to = to;
}
inline int trans(int i, int j, int n) //把坐标转化为编号
{
return ((i - 1) * n + j + 1) / 2;
}
bool match(int i)
{
for (int e = head[i]; e; e = edges[e].next)
{
int j = edges[e].to;
if (!vis[j])
{
vis[j] = true;
if (p[j] == 0 || match(p[j]))
{
p[j] = i;
return true;
}
}
}
return false;
}
int Hungarian()
{
int cnt = 0;
for (int i = 1; i <= N; ++i)
{
memset(vis, 0, sizeof(vis));
if (match(i))
cnt++;
}
return cnt;
}
int main()
{
int n, m, x, y;
scanf("%d%d", &n, &m);
N = (n * n + 1) / 2;
memset(Map, -1, sizeof(Map));
for (int i = 1; i <= n; ++i)
for (int j = 1; j <= n; ++j)
Map[i][j] = 0;
for (int i = 0; i < m; ++i)
{
scanf("%d%d", &x, &y);
Map[x][y] = -1;
}
for (int i = 1; i <= n; i++)
for (int j = i % 2 ? 1 : 2; j <= n; j += 2)
if (Map[i][j] == 0)
{
if (Map[i + 1][j] != -1)
add(trans(i, j, n), trans(i + 1, j, n));
if (Map[i][j + 1] != -1)
add(trans(i, j, n), trans(i, j + 1, n));
if (Map[i - 1][j] != -1)
add(trans(i, j, n), trans(i - 1, j, n));
if (Map[i][j - 1] != -1)
add(trans(i, j, n), trans(i, j - 1, n));
}
printf("%d\n", Hungarian());
return 0;
}
以上就是详解C++实现匈牙利算法的详细内容,更多关于C++匈牙利算法的资料请关注我们其它相关文章!
相关推荐
-
c# 实现模糊PID控制算法
跑起来的效果看每个类的test方法,自己调用来测试 目的是看看哪个算法好用,移植的时候比较单纯没有研究懂算法,代码结构也没改动,只是移植到C#方便查看代码和测试,大家要拷贝也很方便,把整个类拷贝到.cs文件即可 这段算法在实际值低于目标值是工作正常,超过后会有问题,不知道如何调教 using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using System.Tex
-
python 贪心算法的实现
贪心算法 贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择.也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解. 贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关. 基本思路 思想 贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解.每一步只考虑一个数据,他的选取应该满足局部优化的条件.若
-
python动态规划算法实例详解
如果大家对这个生僻的术语不理解的话,那就先听小编给大家说个现实生活中的实际案例吧,虽然现在手机是相当的便捷,还可以付款,但是最初的时候,我们经常会使用硬币,其中,我们如果遇到手中有很多五毛或者1块钱硬币,要怎么凑出来5元钱呢?这么一个过程也可以称之为动态规划算法,下面就来看下详细内容吧. 从斐波那契数列看动态规划 斐波那契数列:Fn = Fn-1 + Fn-2 ( n = 1,2 fib(1) = fib(2) = 1) 练习:使用递归和非递归的方法来求解斐波那契数列的第 n 项 代码如下: #
-
C语言实现页面置换 先进先出算法(FIFO)
本文实例为大家分享了C语言实现页面置换算法的具体代码,供大家参考,具体内容如下 一.设计目的 加深对请求页式存储管理实现原理的理解,掌握页面置换算法中的先进先出算法. 二.设计内容 设计一个程序,有一个虚拟存储区和内存工作区,实现下述三种算法中的任意两种,计算访问命中率(命中率=1-页面失效次数/页地址流长度).附加要求:能够显示页面置换过程. 该系统页地址流长度为320,页面失效次数为每次访问相应指令时,该指令对应的页不在内存的次数. 程序首先用srand()和rand()函数分别进行初
-
详解python 支持向量机(SVM)算法
相比于逻辑回归,在很多情况下,SVM算法能够对数据计算从而产生更好的精度.而传统的SVM只能适用于二分类操作,不过却可以通过核技巧(核函数),使得SVM可以应用于多分类的任务中. 本篇文章只是介绍SVM的原理以及核技巧究竟是怎么一回事,最后会介绍sklearn svm各个参数作用和一个demo实战的内容,尽量通俗易懂.至于公式推导方面,网上关于这方面的文章太多了,这里就不多进行展开了~ 1.SVM简介 支持向量机,能在N维平面中,找到最明显得对数据进行分类的一个超平面!看下面这幅图: 如上图中,
-
python实现暗通道去雾算法的示例
何凯明博士的去雾文章和算法实现已经漫天飞了,我今天也就不啰里啰唆,直接给出自己python实现的完整版本,全部才60多行代码,简单易懂,并有简要注释,去雾效果也很不错. 在这个python版本中,计算量最大的就是最小值滤波,纯python写的,慢,可以进一步使用C优化,其他部分都是使用numpy和opencv的现成东东,效率还行. import cv2 import numpy as np def zmMinFilterGray(src, r=7): '''最小值滤波,r是滤波器半径''' ''
-
python实现AdaBoost算法的示例
代码 ''' 数据集:Mnist 训练集数量:60000(实际使用:10000) 测试集数量:10000(实际使用:1000) 层数:40 ------------------------------ 运行结果: 正确率:97% 运行时长:65m ''' import time import numpy as np def loadData(fileName): ''' 加载文件 :param fileName:要加载的文件路径 :return: 数据集和标签集 ''' # 存放数据及标记 da
-
python 实现非极大值抑制算法(Non-maximum suppression, NMS)
NMS 算法在目标检测,目标定位领域有较广泛的应用. 算法原理 非极大值抑制算法(Non-maximum suppression, NMS)的本质是搜索局部极大值,抑制非极大值元素. 算法的作用 当算法对一个目标产生了多个候选框的时候,选择 score 最高的框,并抑制其他对于改目标的候选框 适用场景 一幅图中有多个目标(如果只有一个目标,那么直接取 score 最高的候选框即可). 算法的输入 算法对一幅图产生的所有的候选框,以及每个框对应的 score (可以用一个 5 维数组 dets 表
-

C语言实现页面置换算法
本文实例为大家分享了C语言实现页面置换算法的具体代码,供大家参考,具体内容如下 操作系统实验 页面置换算法(FIFO.LRU.OPT) 概念: 1.最佳置换算法(OPT)(理想置换算法):从主存中移出永远不再需要的页面:如无这样的页面存在,则选择最长时间不需要访问的页面.于所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率. 2.先进先出置换算法(FIFO):是最简单的页面置换算法.这种算法的基本思想是:当需要淘汰一个页面时,总是选择驻留主存时
-
详解C++实现匈牙利算法
目录 一.匈牙利算法介绍 二.最大匹配问题 三.最小点覆盖问题 四.匈牙利算法的应用 4.1.(洛谷P1129) [ZJOI2007]矩阵游戏 4.2.(vijos1204) CoVH之柯南开锁 4.3.(TYVJ P1035) 棋盘覆盖 一.匈牙利算法介绍 匈牙利算法(Hungarian algorithm)主要用于解决一些与二分图匹配有关的问题,所以我们先来了解一下二分图. 二分图(Bipartite graph)是一类特殊的图,它可以被划分为两个部分,每个部分内的点互不相连.下图是典型的二
-
详解小白之KMP算法及python实现
在看子串匹配问题的时候,书上的关于KMP的算法的介绍总是理解不了.看了一遍代码总是很快的忘掉,后来决定好好分解一下KMP算法,算是给自己加深印象. 在将KMP字串匹配问题的时候,我们先来回顾一下字串匹配的暴力解法: 假设字符串str为: "abcgbabcdh", 字串substr为: "abcd" 从第一个字符开始比较,显然两个字符串的第一个字符相等('a'=='a'),然后比较第二个字符也相等('b'=='b'),继续下去,我们发现第4个字符不相等了('g'!
-
详解vue3.0 diff算法的使用(超详细)
前言:随之vue3.0beta版本的发布,vue3.0正式版本相信不久就会与我们相遇.尤玉溪在直播中也说了vue3.0的新特性typescript强烈支持,proxy响应式原理,重新虚拟dom,优化diff算法性能提升等等.小编在这里仔细研究了vue3.0beta版本diff算法的源码,并希望把其中的细节和奥妙和大家一起分享. 首先我们来思考一些大中厂面试中,很容易问到的问题: 1 什么时候用到diff算法,diff算法作用域在哪里? 2 diff算法是怎么运作的,到底有什么作用? 3 在v-f
-
详解Vue2的diff算法
前言 双端比较算法是vue2.x采用的diff算法,本篇文章只是对双端比较算法粗略的过程进行了一下分析,具体细节还是得Vue源码,Vue的源码在这 过程 假设当前有两个数组arr1和arr2 let arr1 = [1,2,3,4,5] let arr2 = [4,3,5,1,2] 那么其过程有五步 arr1[0] 和 arr2[0]比较 arr1[ arr1.length-1 ] 和 arr2[ arr2.length-1 ] 比较 arr1[0] 和 arr2[ arr2.length-1
-
详解Java实现分治算法
目录 一.前言 二.分治算法介绍 三.分治算法经典问题 3.1.二分搜索 3.2.快速排序 3.3.归并排序(逆序数) 3.4.最大子序列和 3.5.最近点对 四.结语 一.前言 在学习分治算法之前,问你一个问题,相信大家小时候都有存钱罐的经历,父母亲人如果给钱都会往自己的宝藏中存钱,我们每隔一段时间都会清点清点钱.但是一堆钱让你处理起来你可能觉得很复杂,因为数据相对于大脑有点庞大了,并且很容易算错,你可能会将它先分成几个小份算,然后再叠加起来计算总和就获得这堆钱的总数了 当然如果你觉得各个部分
-
详解非极大值抑制算法之Python实现
一.概述 这里不讨论通用的NMS算法(参考论文<Efficient Non-Maximum Suppression>对1维和2维数据的NMS实现),而是用于目标检测中提取分数最高的窗口的.例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数.但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况.这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口. NMS在计算机视觉领域有着非常重要的应用,如视频目标跟踪.数据挖掘
-
详解Python数据结构与算法中的顺序表
目录 0. 学习目标 1. 线性表的顺序存储结构 1.1 顺序表基本概念 1.2 顺序表的优缺点 1.3 动态顺序表 2. 顺序表的实现 2.1 顺序表的初始化 2.2 获取顺序表长度 2.3 读取指定位置元素 2.4 查找指定元素 2.5 在指定位置插入新元素 2.6 删除指定位置元素 2.7 其它一些有用的操作 3. 顺序表应用 3.1 顺序表应用示例 3.2 利用顺序表基本操作实现复杂操作 0. 学习目标 线性表在计算机中的表示可以采用多种方法,采用不同存储方法的线性表也有着不同的名称和特
-
详解Java中KMP算法的图解与实现
目录 图解 代码实现 图解 kmp算法跟之前讲的bm算法思想有一定的相似性.之前提到过,bm算法中有个好后缀的概念,而在kmp中有个好前缀的概念,什么是好前缀,我们先来看下面这个例子. 观察上面这个例子,已经匹配的abcde称为好前缀,a与之后的bcde都不匹配,所以没有必要再比一次,直接滑动到e之后即可. 那如果好前缀中有互相匹配的字符呢? 观察上面这个例子,这个时候如果我们直接滑到好前缀之后,则会过度滑动,错失匹配子串.那我们如何根据好前缀来进行合理滑动? 其实就是看当前的好前缀的前缀和后缀
-
详解opencv去除背景算法的方法比较
目录 背景减除法 (1)BackgroundSubtractorMOG (2)BackgroundSubtractorMOG2 (3)BackgroundSubtractorGMG 帧差法 最近做opencv项目时,使用肤色分割的方法检测目标物体时,背景带来的干扰非常让人头痛.于是先将背景分割出去,将影响降低甚至消除.由于初次接触opencv,叙述不当的地方还请指正. 背景减除法 (以下文字原文来源于https://docs.opencv.org/3.4.7/d8/d38/tutorial_bg