MySQL中in和exists区别详解
一、提前准备
为了大家学习方便,我在这里面建立两张表并为其添加一些数据。
一张水果表,一张供应商表。
水果表 fruits表
| f_id | f_name | f_price |
|---|---|---|
| a1 | apple | 5 |
| a2 | appricot | 2 |
| b1 | blackberry | 10 |
| b2 | berry | 8 |
| c1 | cocount | 9 |
供应商表 suppliers表
| s_id | s_name |
|---|---|
| 101 | 天虹 |
| 102 | 沃尔玛 |
| 103 | 家乐福 |
| 104 | 华润万家 |
我们将用这两张表做演示。
二、什么是exists
exists关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,那么exists的结果为true ,此时外层的查询语句将进行查询;如果子查询没有返回任何行,那么exists的结果为false,此时外层语句将不进行查询。
需要注意的是,当我们的子查询为 SELECT NULL 时,MYSQL仍然认为它是True。
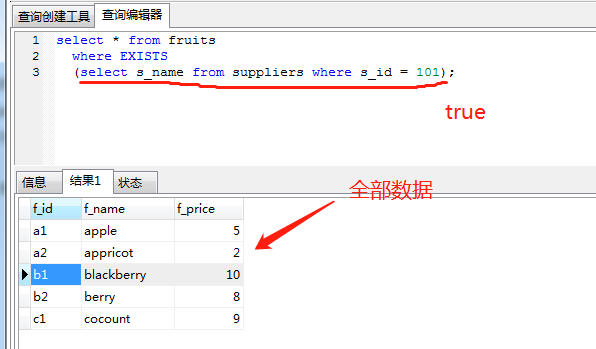
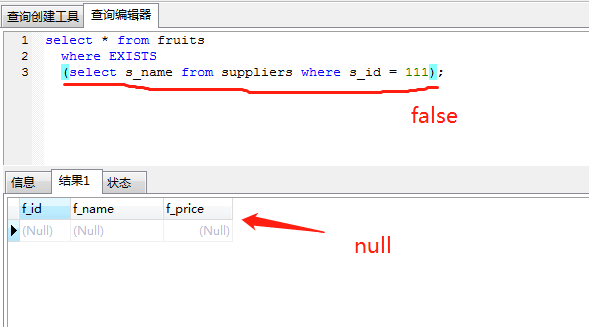
三、什么是in
in 关键字进行子查询时,内层查询语句仅仅返回一个数据列,这个数据列的值将提供给外层查询语句进行比较操作。
为了测试in 关键字,我在水果表中加了s_id一列
水果表 fruits表
| f_id | f_name | f_price | s_id |
|---|---|---|---|
| a1 | apple | 5 | 101 |
| a2 | appricot | 2 | 103 |
| b1 | blackberry | 10 | 102 |
| b2 | berry | 8 | 104 |
| c1 | cocount | 9 | 103 |
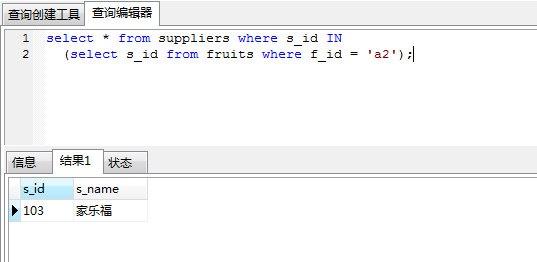
四、exists和in
in和exists到底有啥区别那,要什么时候用in,什么时候用exists?
我们先记住口诀再说细节!“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”
我想你已经看出来了,当fruits表数据很大的时候不适合用in,因为它最多会将fruits表数据全部遍历一次。
如:suppliers表有10000条记录,fruits表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差。
再如:suppliers表有10000条记录,fruits表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升。
但是:suppliers表有10000条记录,fruits表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快。
因此我们只需要记住口诀:“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”
五、not exists和not in
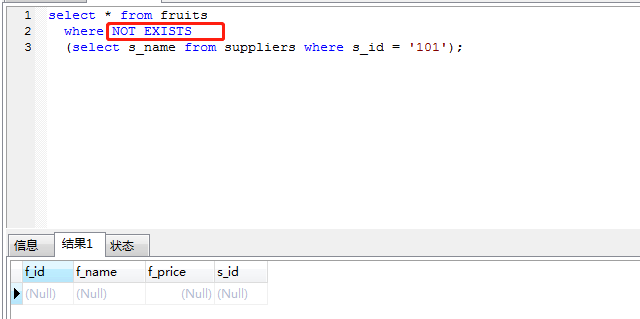
和exists一样,用到了suppliers上的id索引,exists()执行次数为fruits.length,不缓存exists()的结果集。
因为not in实质上等于!= and != ···,因为!=不会使用索引,故not in不会使用索引。
为啥not in不会使用索引?
我们假设有100万数据,s_id只有0和1两个值,利用索引我们要先读索引文件,然后二分查找,找到对应的数据磁盘指针,再根据读到的指针在磁盘上对应的数据,影响结果集50万,这种情况,和直接全表扫描哪个快显而易见。
如果你s_id字段是一个unique,就会用到索引。
如果你一定要用索引,可以用force index,不过效率不会有改善一般还会更慢就是了。
合理使用索引,Cardinality是一个重要指标,太小的话跟没建没区别,还浪费空间。
因此,不管suppliers和fruits大小如何,均使用not exists效率会更高。
到此这篇关于MySQL中in和exists区别详解的文章就介绍到这了,更多相关MySQL in和exists区别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

mysql中EXISTS和IN的使用方法比较
1.使用方式: (1)EXISTS用法 select a.batchName,a.projectId from ucsc_project_batch a where EXISTS (select b.id from ucsc_project b where a.projectId = b.id) 上面这条SQL的意思就是:以ucsc_project_batch为主表查询batchName与projectId字段,其中projectId字段存在于ucsc_project表中. EXISTS 会对外
-
mysql not in、left join、IS NULL、NOT EXISTS 效率问题记录
NOT IN.JOIN.IS NULL.NOT EXISTS效率对比 语句一:select count(*) from A where A.a not in (select a from B) 语句二:select count(*) from A left join B on A.a = B.a where B.a is null 语句三:select count(*) from A where not exists (select a from B where A.a = B.a) 知道以上三
-
MySQL中exists、in及any的基本用法
[1]exists 对外表用loop逐条查询,每次查询都会查看exists的条件语句. 当 exists里的条件语句能够返回记录行时(无论记录行是多少,只要能返回),条件就为真 , 返回当前loop到的这条记录.反之如果exists里的条件语句不能返回记录行,条件为假,则当前loop到的这条记录被丢弃. exists的条件就像一个boolean条件,当能返回结果集则为1,不能返回结果集则为 0. 语法格式如下: select * from tables_name where [not] exis
-
MYSQL IN 与 EXISTS 的优化示例介绍
优化原则:小表驱动大表,即小的数据集驱动大的数据集. ############# 原理 (RBO) ##################### select * from A where id in (select id from B) 等价于: for select id from B for select * from A where A.id = B.id 当B表的数据集必须小于A表的数据集时,用in优于exists. select * from A where exists (selec
-
mySQL中in查询与exists查询的区别小结
一.关于exists查询 explain select * from vendor where EXISTS(select * from area where area_code = vendor_prov_code ) limit 10 以上是一个典型的exists查询的sql语句. 它的作用方式是这样的:每次从vendor表中查询出一条数据,然后将这条数据中的vendor_prov_code值传递到exists查询中进行执行,也就是进行子查询的执行. 如果子查询查到的数据就返回布尔值true
-
对比分析MySQL语句中的IN 和Exists
背景介绍 最近在写SQL语句时,对选择IN 还是Exists 犹豫不决,于是把两种方法的SQL都写出来对比一下执行效率,发现IN的查询效率比Exists高了很多,于是想当然的认为IN的效率比Exists好,但本着寻根究底的原则,我想知道这个结论是否适用所有场景,以及为什么会出现这个结果. 网上查了一下相关资料,大体可以归纳为:外部表小,内部表大时,适用Exists:外部表大,内部表小时,适用IN.那我就困惑了,因为我的SQL语句里面,外表只有1W级别的数据,内表有30W级别的数据,按网上的说法应
-
MySQL中in与exists的使用及区别介绍
先放一段代码 for(int i=0;i<1000;i++){ for(int j=0;j<5;j++){ System.out.println("hello"); } } for(int i=0;i<5;i++){ for(int j=0;j<1000;j++){ System.out.println("hello"); } } 分析以上代码可以看到两行代码除了循环的次序不一致意外,其他并无区别,在实际执行时两者所消耗的时间和空间应该也是一
-
MySQL exists 和in 详解及区别
MySQL exists 和in 详解及区别 有一个查询如下: SELECT c.CustomerId, CompanyName FROM Customers c WHERE EXISTS( SELECT OrderID FROM Orders o WHERE o.CustomerID = cu.CustomerID) 这里面的EXISTS是如何运作呢?子查询返回的是OrderId字段,可是外面的查询要找的是CustomerID和CompanyName字段,这两个字段肯定不在OrderID里面啊
-
MySQL中in和exists区别详解
一.提前准备 为了大家学习方便,我在这里面建立两张表并为其添加一些数据. 一张水果表,一张供应商表. 水果表 fruits表 f_id f_name f_price a1 apple 5 a2 appricot 2 b1 blackberry 10 b2 berry 8 c1 cocount 9 供应商表 suppliers表 s_id s_name 101 天虹 102 沃尔玛 103 家乐福 104 华润万家 我们将用这两张表做演示. 二.什么是exists exists关键字后面的参数是一
-
MySQL中的SQL标准语句详解
目录 前言 对数据库的操作 对表的操作 表的创建 表的插入 表的修改 表的删除 表的查询 条件查询 前言 例如MySQL中的LIMIT语句就是MySQL独有的方言,其它数据库都不支持!当然,Oracle或SQL Server都有自己的方言. 语法要求: SQL语句可以单行或多行书写,以分号结尾: 可以用空格和缩进来来增强语句的可读性: 关键字不区别大小写,建议使用大写: 对数据库的操作 #语法: CREATE DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHAR
-
mysql中find_in_set()函数的使用详解
首先举个例子来说: 有个文章表里面有个type字段,它存储的是文章类型,有 1头条.2推荐.3热点.4图文等等 . 现在有篇文章他既是头条,又是热点,还是图文,type中以 1,3,4 的格式存储.那我们如何用sql查找所有type中有4的图文类型的文章呢?? 这就要我们的 find_in_set 出马的时候到了.以下为引用的内容: select * from article where FIND_IN_SET('4',type) --------------------------------
-
Mysql中的CHECK约束特性详解
功能说明 在MySQL 8.0.16以前, CREATE TABLE允许从语法层面输入下列CHECK约束,但实际没有效果: CHECK (expr) 在 MySQL 8.0.16,CREATE TABLE添加了针对所有存储引擎的表和列的CHECK约束的核心特性.CREATE TABLE允许如下针对表或列的约束语法: [CONSTRAINT [symbol]] CHECK (expr) [[NOT] ENFORCED] 可选的symbol指定了约束的名称,如果省略,MySQL会自动生成一个类似:$
-
Android通过json向MySQL中读写数据的方法详解【读取篇】
本文实例讲述了Android通过json向MySQL中读取数据的方法.分享给大家供大家参考,具体如下: 首先 要定义几个解析json的方法parseJsonMulti,代码如下: private void parseJsonMulti(String strResult) { try { Log.v("strResult11","strResult11="+strResult); int index=strResult.indexOf("[");
-
Android通过json向MySQL中读写数据的方法详解【写入篇】
本文实例讲述了Android通过json向MySQL中写入数据的方法.分享给大家供大家参考,具体如下: 先说一下如何通过json将Android程序中的数据上传到MySQL中: 首先定义一个类JSONParser.Java类,将json上传数据的方法封装好,可以直接在主程序中调用该类,代码如下 public class JSONParser { static InputStream is = null; static JSONObject jObj = null; static String j
-
Mysql中Join的使用实例详解
在前几章节中,我们已经学会了如果在一张表中读取数据,这是相对简单的,但是在真正的应用中经常需要从多个数据表中读取数据. 本章节我们将向大家介绍如何使用MySQL 的 JOIN 在两个或多个表中查询数据. 你可以在SELECT, UPDATE 和 DELETE 语句中使用Mysql 的 join 来联合多表查询. 以下我们将演示MySQL LEFT JOIN 和 JOIN 的使用的不同之处. 在命令提示符中使用JOIN 我们在RUNOOB数据库中有两张表 tcount_tbl 和 runoob_t
-
在MySQL中自定义参数的使用详解
MySQL变量包括系统变量和系统变量.这次的学习任务是用户自定义变量.用户变量主要包括局部变量和会话变量. 用户自定义变量的声明方法形如:@var_name,其中变量名称由字母.数字."."."_"和"$"组成.当然,在以字符串或者标识符引用时也可以包含其他字符(例如:@'my-var',@"my-var",或者@my-var). 用户自定义变量是会话级别的变量.其变量的作用域仅限于声明其的客户端链接.当这个客户端断开时,其所
-
linux shell中“.” 和 “./”执行的区别详解
目前注意到的区别主要在于环境变量的作用域上: 1. 如果使用" ./ " 执行,可以理解为程序运行在一个全新的shell中,不继承当前shell的环境变量的值, 同时若在程序中改变了当前shell中的环境变量(不使用export),则当前shell的环境变量值不变. 2. 如果使用" . "执行,则程序继承当前shell中的环境变量,同时,若在程序中改变了当前shell中的环境变量(不使用export),则当前shell中该环境变量的值也会改变 另外一个区别点在于,
-
Java中 % 与Math.floorMod() 区别详解
%为取余(rem),Math.floorMod()为取模(mod) 取余取模有什么区别呢? 对于整型数a,b来说,取模运算或者取余运算的方法都是: 1.求 整数商: c = a/b; 2.计算模或者余数: r = a - c*b. 区别是: 取余运算在计算商值向0方向舍弃小数位 取模运算在计算商值向负无穷方向舍弃小数位 比如a=4,b=-3时,a/b = -1.3333... 此时,取余c=1,取模c=-2 (%在不同语言中有不同的意义,比如Java或者c/c++中%为取余,python中%则为