MyBatis入门学习教程-MyBatis快速入门
目录
- Mybatis
- 一、快速开始
- 1、创建 Maven 项目
- 2、导入 Maven 依赖
- 3、配置 Maven 插件
- 4、新建数据库,导入表格
- 5、编写 Mybatis 配置文件
- 6、编写实体类
- 7、编写 mapper 接口
- 8、编写 mapper 实现
- 9、Mybatis 配置文件中,添加 mapper 映射
- 10、编写 Mybatis 工具类
- 11、测试
- 二、日志添加
- 1、添加 Maven 依赖
- 2、添加 log4j 配置
- 3、Mybatis 中配置 LOG
- 4、执行测试
- 三、Mybatis 对象分析
- 1、Resources
- 2、SqlSessionFactoryBuilder
- 3、SqlSessionFactory
- 4、SqlSession
- 四、改进 MybatisUtil
- 五、输入映射
- 1、使用下标(不推荐)
- 2、使用注解
- 3、使用 map
- 六、输出映射
- 1、resultType
- 2、resultMap
- 3、数据库表中列与实体类属性不一致的处理方式
- 七、#{} 和 ${} 的区别
- 八、Mybatis 全局配置文件
- 1、配置内容总览
- 2、属性(properties)
- 3、设置(settings)
- 4、类型别名(typeAliases)
- 5、 映射器(Mappers)
- 6、数据源(dataSource)
- 7、事务(
transactionManager) - 九、关系映射
- 1、对一关系
- 2、对多关系
- 十、动态 SQL
- 十一、分页插件
- 1、快速开始
- 2、PageHelper 介绍
- 3、PageInfo 介绍
- 十二、缓存
- 1、一级缓存
- 2、二级缓存
- 十三、反向生成器
- 1、配置
- 2、使用
- 十四.总结
Mybatis
MyBatis ,是国内最火的持久层框架
采用了ORM思想解决了实体类和数据库表映射的问题。对JDBC进行了封装,屏蔽了JDBCAPI底层的访问细节,避免我们与jdbc的api打交 道,就能完成对数据的持久化操作。
O--Object java对象
R- Relation 关系,就是数据库中的一张表
M-mapping 映射
一、快速开始
Mybatis 官方帮助文档: https://mybatis.org/mybatis-3/zh/index.html
1、创建 Maven 项目
2、导入 Maven 依赖
这里,我们要导入 mybatis的依赖、mysql 的一类、单元测试的依赖
<dependencies>
<!--mybatis-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
<!--单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
3、配置 Maven 插件
这里,要配置的,是 Maven 的编译插件,我们指定源文件和编译后的文件都是 java 1.8 版本的
<build>
<plugins>
<!--编译插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
4、新建数据库,导入表格

CREATE TABLE `team` ( `teamId` int NOT NULL AUTO_INCREMENT COMMENT '球队ID', `teamName` varchar(50) DEFAULT NULL COMMENT '球队名称', `location` varchar(50) DEFAULT NULL COMMENT '球队位置', `createTime` date DEFAULT NULL COMMENT '球队建立时间', PRIMARY KEY (`teamId`) ) ENGINE=InnoDB AUTO_INCREMENT=1003 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
5、编写 Mybatis 配置文件
我们可以直接在官网,获取配置文件的示例
日后在开发时,建议读者创建一个文档,存放配置文件的编写规则,方便开发
<property>中的内容,可以通过配置文件的方式获取,我们后面再介绍
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--mybatis 环境,可以为 mybatis 配置多套环境,然后根据 id 切换-->
<environments default="development">
<environment id="development">
<!--事务类型:使用 JDBC 事务,使用 Connection 的提交和回滚-->
<transactionManager type="JDBC"/>
<!--数据源 dataSource:创建数据库 Connection 对象 type: POOLED 使用数据库的连接池 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mybatis_study?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT"/>
<property name="username" value="admin"/>
<property name="password" value="123"/>
</dataSource>
</environment>
</environments>
<!--mapper映射,这里我们先不写,后面再讲-->
<!--<mappers>-->
<!-- <mapper resource="org/mybatis/example/BlogMapper.xml"/>-->
<!--</mappers>-->
</configuration>
6、编写实体类
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Team {
private Integer teamId;
private String teamName;
private String location;
private Date createTime;
}
7、编写 mapper 接口
public interface TeamMapper {
/**
* 获取全部 team 信息
* @return
*/
List<Team> getAll();
}
8、编写 mapper 实现
实现,是用 .xml 文件编写的
id:接口中非方法
resultTyoe:接口方法的返回值(在配置前,必须写全类名)
注意: XxxMapper.xml,必须要和对应的 mapper 接口,同包同名

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace绑定一个指定的Dao/Mapper接口-->
<mapper namespace="top.faroz.dao.TeamMapper">
<select id="getAll" resultType="top.faroz.pojo.Team">
select * from team
</select>
</mapper>
也可以将 .xml 实现,放在 resources 下,但是一定要注意,同包同名:

9、Mybatis 配置文件中,添加 mapper 映射
<!--mapper映射-->
<mappers>
<package name="top.faroz.dao"/>
</mappers>
编写完 .xml 实现后,一定要在配置文件中,添加 mapper 映射
<!--mapper映射--> <mappers> <package name="top.faroz.dao"/> </mappers>

10、编写 Mybatis 工具类
工具类用来创建 sqlSession的单例工厂
并添加一个方法,用来获取 sqlSession 连接
public class MybatisUtil {
/**
* 连接工厂
* 用来创建连接
*/
private static SqlSessionFactory sqlSessionFactory;
static {
//使用MyBatis第一步:获取SqlSessionFactory对象
try {
String resource = "mybatis.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
/**
* 通过配置文件,创建工程
* (配置文件就是 resources 下的 mybatis.xml)
*/
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
public static SqlSession getSqlSession() {
//设置为true,自动提交事务
return sqlSessionFactory.openSession(true);
}
}
11、测试
@Test
public void getAllTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
TeamMapper mapper = sqlSession.getMapper(TeamMapper.class);
List<Team> all = mapper.getAll();
for (Team team : all) {
System.out.println(team);
}
sqlSession.close();
}
测试结果如下:

二、日志添加
1、添加 Maven 依赖
<!--log4j日志-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2、添加 log4j 配置

log4j.properties
我们可以调整日志输出的级别,除了 DEBUG外,还可以有 INFO,WARNING , ERROR
# Global logging configuration info warning error log4j.rootLogger=DEBUG,stdout # Console output... log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
现在是在控制台输出,未来,可能我们的项目,是要部署在客户的服务器上的,我们可以将日志信息固定输出到某个外部文件当中
3、Mybatis 中配置 LOG
<!--配置日志-->
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>

4、执行测试
控制台会显示详细的日志信息

三、Mybatis 对象分析
1、Resources

Resources 类,顾名思义就是资源,用于读取资源文件。其有很多方法通过加载并解析资源文件,返回不同类型的 IO 流对象。
2、SqlSessionFactoryBuilder
用来创建 SqlSessionFactory 的创造者,在整个项目中,只会使用一次,就是用来创建 SqlSessionFactory 的。用后即丢
3、SqlSessionFactory
创建 sqlSession 的单例工厂。在整个项目中,应该只有一个 SqlSessionFactory 的单例
4、SqlSession
一个 SqlSession 对应着一次数据库会话,一次会话以SqlSession 对象的创建开始,以 SqlSession 对象的关闭结束。
SqlSession 接口对象是线程不安全的,所以每次数据库会话结束前,需要马上调用其 close()方法,将其关闭。再次需要会话,再次创建。
四、改进 MybatisUtil
在 快速开始 栏目中,我们将获取 Mybatis 的 sqlSession 对象的过程,封装成了一个工具类
但是,sqlSession 并没有作为一个成员变量,存储在 MybatisUtil 中,这样,我们对 sqlSession 执行 close ,必须要手动去调用我们外部获得的 sqlSession ,其实,我们可以将 sqlSession 变成一个成员变量,然后,在 MybatisUtil 中,写一个close 方法。
但是,我们要注意,sqlSession 是线程不安全的,每次使用完后,我们都需要进行 close,然后,在下次使用的时候,再次连接 sqlSession ,如果把 sqlSession ,作为一个静态成员变量,放在 MybatisUtil 中,势必会引发线程相关的问题。
为了解决这个问题,我们需要来介绍一下 ThreadLocal
1、ThreadLocal
2、使用 ThreadLocal 来改写
3、小结
我个人其实是不建议将 sqlSession 作为一个静态成员变量的,并且官方文档也不建议我们这么做。我写这一小节的主要目的,还是为了介绍一下 ThreadLocal
五、输入映射
之前,我们的测试中,输入都是单个值,如果我们的输入中,有多个值,该怎么办呢?
1、使用下标(不推荐)
如果有多个参数,可以使用:
#{arg0},#{arg1},#{arg2}…,或者#{param0},#{param2},#{param3}…的方式,获取不同参数
但是这种方式,不推荐使用
2、使用注解
我们可以在对应的 mapper 接口的参数前,加上 @Param 注解,并且在 .xml 实现类中,直接使用注解中定义的参数名
接口:
Team selectByNameAndLocation(@Param("name") String name,@Param("location") String location);
实现:
<select id="selectByNameAndLocation" resultType="top.faroz.pojo.Team">
select * from team where teamName=#{name} and location=#{location}
</select>
测试:
@Test
public void selectByNameAndLocationTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
TeamMapper mapper = sqlSession.getMapper(TeamMapper.class);
Team team = mapper.selectByNameAndLocation("雄鹿", "威斯康星州密尔沃基");
System.out.println(team);
sqlSession.close();
}

3、使用 map
传入的参数,可以为 map ,.xml文件中,获取的参数,要和 map 中的 key 值保持一致
接口:
Team selectByName(Map map);
实现:
<select id="selectByName" resultType="top.faroz.pojo.Team" parameterType="map">
select * from team where teamName=#{name}
</select>
测试:
@Test
public void selectByNameTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
TeamMapper mapper = sqlSession.getMapper(TeamMapper.class);
Map<String, Object> map = new HashMap<>();
map.put("name","雄鹿");
Team team = mapper.selectByName(map);
System.out.println(team);
sqlSession.close();
}
六、输出映射
1、resultType
1)、输出简单类型
就是一般的,输出单个 String 或者 Integer 类型,前面的示例有很多,这里不再演示了
2)、输出 pojo 类型
List<Team> queryAll();
<!--接口方法返回是集合类型,但是映射文件中的resultType需要指定集合中的类型,不是集合本身。--> <select id="queryAll" resultType="com.kkb.pojo.Team"> select * from team; </select>
3)、输出 map 类型
当我们只需要查询表中几列数据的时候可以将sql的查询结果作为Map的key和value。一般使用的是Map<Object,Object>。
Map 作为接口返回值,sql 语句的查询结果最多只能有一条记录。大于一条记录会抛出TooManyResultsException异常。 如果有多行,使用List<Map<Object,Object>>。
Map<Object,Object> queryTwoColumn(int teamId); List<Map<Object,Object>> queryTwoColumnList();
<select id="queryTwoColumn" resultType="java.util.HashMap" paramType="int">
select teamName,location from team where teamId = #{id}
</select>
<select id="queryTwoColumnList" resultType="java.util.HashMap">
select teamName,location from team
</select>
@Test
public void test08(){
Map<String, Object> map = teamMapper.queryTwoColumn(); System.out.println(map);
}
@Test
public void test09(){
List<Map<String, Object>> list = teamMapper.queryTwoColumnList();
for (Map<String, Object> map : list) {
System.out.println(map);
}
}
2、resultMap
resultMap 可以自定义 sql 的结果和 java 对象属性的映射关系。更灵活的把列值赋值给指定属性。
一般主键列用id , 其余列用result column:表示数据库表中的列名,不区分大小写 property:表示实体类中的对应的属性名,区分大小写 javaType: 实体类中的对应的属性的类型,可以省略,mybatis会自己推断 jdbcType="数据库中的类型column的类型" 一般省略
<resultMap id="baseResultMap" type="com.kkb.pojo.Team"> <!--主键列,使用 id--> <id column="teamId" property="teamId" javaType="java.lang.Integer"></id> <!--其余列,使用 result--> <result column="teamName" property="teamName" javaType="java.lang.String"></result> <result column="location" property="location" javaType="java.lang.String"></result> <result column="createTime" property="createTime" javaType="java.util.Date"></result> </resultMap>
实现语句,使用的时候,返回值就由原来的 resultType,改为我们写的 resultMap:
<select id="queryAll2" resultMap="baseResultMap"> select * from team; </select>
使用 resultMap 进行属性映射,还可以解决属性名与数据库表列名不一致的问题
3、数据库表中列与实体类属性不一致的处理方式
1)、使用 resultMap 去解决
上面讲过,这里就不再演示了
2)、sql 中起别名
假如 sql 中的命名方式,是使用下划线方式的,而 pojo 中,使用的是驼峰命名方式,那我们可以用如下起别名的方式,将查询出的结果,换成驼峰命名方式:
select user_id as userId,user_name as userName,user_age as userAge from users where user_id=#{id};
七、#{} 和 ${} 的区别
这个问题,也是面试题常考的
#{}:表示一个占位符,通知Mybatis 使用实际的参数值代替。并使用 PrepareStatement 对象执行 sql 语句, #{…}代替sql 语句的“?”。这个是Mybatis 中的首选做法,安全迅速。
通过这种方式,可以防止 sql 注入。
${}:表示字符串原样替换,通知Mybatis 使用$包含的“字符串”替换所在位置。使用 Statement或者PreparedStatement 把 sql 语句和${} 的内容连接起来。一般用在替换表名, 列名,不同列排序等操作。
这种方式,可以修改 sql 语句的列,比如说,我们有这么个需求:
需要分别根据 name,age,address 等查询用户信息,按照一般的写法,就要写 3 个 sql
select * from xxx where name = #{name}
select * from xxx where age = #{age}
select * from xxx where address = #{address}
我们可以看到,不同的,只是 where 后面的部分,这里,我们就可以用 ${}去替换 where 后面的部分,从而不用写那么多 sql
select * from xxx where ${column} = #{columnValue}
这里要注意,因为是字符串拼接非方式,所以,${}千万不能用在参数上面,不然可能会产生 sql 注入的问题。但为什么可以用在 sql 的其他位置?这是因为,如果在非参数的地方,写上 sql 注入的语句,就会造成 sql 语句错误,从而报错。
八、Mybatis 全局配置文件
1、配置内容总览
配置的时候,少几个配置没有关系,但是一定要按照下面的顺去配置
configuration(配置)
properties--属性:加载外部的配置文件,例如加载数据库的连接信息
Settings--全局配置参数:例如日志配置
typeAliases--类型别名
typeHandlers----类型处理器
objectFactory-----对象工厂
Plugins------插件:例如分页插件
Environments----环境集合属性对象
environment(环境变量)
transactionManager(事务管理器)
dataSource(数据源)
Mappers---映射器:注册映射文件用
2、属性(properties)
可以通过属性配置,让 Mybatis 去读取外部的配置文件,比如加载数据库的连接信息
1)、新建配置文件
在 resources 文件夹下,建立 jdbc.properties 配置文件
jdbc.driver=com.mysql.cj.jdbc.Driver jdbc.url=jdbc:mysql://127.0.0.1:3306/mybatis_study?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT jdbc.username=admin jdbc.password=123
2)、mybatis 配置中,引入配置文件信息
<!--加载配置文件--> <properties resource="jdbc.properties"/>
3)、读取配置文件
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
3、设置(settings)
MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为.例如我们配置的日志就是应用之一。其余内容参考设置文档
https://mybatis.org/mybatis-3/zh/configuration.html#settings
4、类型别名(typeAliases)
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。
1)已支持的别名

2)自定义别名
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。例如:
<typeAliases> <typeAlias alias="Author" type="domain.blog.Author"/> <typeAlias alias="Blog" type="domain.blog.Blog"/> <typeAlias alias="Comment" type="domain.blog.Comment"/> <typeAlias alias="Post" type="domain.blog.Post"/> <typeAlias alias="Section" type="domain.blog.Section"/> <typeAlias alias="Tag" type="domain.blog.Tag"/> </typeAliases>
当这样配置时,Blog 可以用在任何使用 domain.blog.Blog 的地方。
(下面👇这个方法应该更便捷)
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean,比如:
<typeAliases> <package name="top.faroz.pojo"/> </typeAliases>
<select id="getUserList" resultType="user">
select * from user
</select>
5、 映射器(Mappers)

方式一:【推荐使用】
<!-- 使用相对于类路径的资源引用 --> <mappers> <mapper resource="org/mybatis/builder/AuthorMapper.xml"/> <mapper resource="org/mybatis/builder/BlogMapper.xml"/> <mapper resource="org/mybatis/builder/PostMapper.xml"/> </mappers>
方式二:使用class文件绑定
<!-- 使用映射器接口实现类的完全限定类名 --> <mappers> <mapper class="org.mybatis.builder.AuthorMapper"/> <mapper class="org.mybatis.builder.BlogMapper"/> <mapper class="org.mybatis.builder.PostMapper"/> </mappers>
注意点:
接口和配置文件同名接口和它的Mapper配置文件必须在同一个包下
方式三:使用扫描包进行注入绑定
<!-- 将包内的映射器接口实现全部注册为映射器 --> <mappers> <package name="org.mybatis.builder"/> </mappers>
6、数据源(dataSource)
有三种内建的数据源类型(也就是 type="[UNPOOLED|POOLED|JNDI]"):
UNPOOLED– 这个数据源的实现会每次请求时打开和关闭连接。虽然有点慢,但对那些数据库连接可用性要求不高的简单应用程序来说POOLED– 这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的连接实例时所必需的初始化和认证时间。 (数据库连接池)JNDI – 这个数据源实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的数据源引用。
默认使用POOLED
7、事务(transactionManager)
1)、默认是需要手动提交事务的
Mybatis 框架是对 JDBC 的封装,所以 Mybatis 框架的事务控制方式,本身也是用 JDBC 的 Connection对象的 commit(), rollback().Connection 对象的 setAutoCommit()方法来 设置事务提交方式的。
自动提交和手工提交、<transactionManager type="JDBC"/>该标签用于指定 MyBatis所使用的事务管理器。MyBatis 支持两种事务管理器类型:JDBC 与 MANAGED。
JDBC:使用JDBC的事务管理机制,通过Connection对象的 commit()方法提交,通过rollback()方法 回滚。默认情况下,mybatis将自动提交功能关闭了,改为了手动提交,观察日志可以看出,所以我们在程序中都需要自己提交事务或者回滚事务。

MANAGED:由容器来管理事务的整个生命周期(如Spring容器)。
2)、自动提交事务

九、关系映射
1、对一关系
有这么一个需求,有许多学生,很多学生对应某个老师,现在要将学生和对应老师的属性查询出来
SQL语句:
# 学生表
drop table if exists `student`;
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '学生 id',
`name` varchar(50) DEFAULT NULL COMMENT '学生姓名',
`tid` int DEFAULT NULL COMMENT '学生所属老师 id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1003 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into student value (1,'jojo',1);
insert into student value (2,'dio',1);
insert into student value (3,'faro',2);
insert into student value (4,'kkk',2);
insert into student value (5,'ttt',3);
# 老师表
drop table if exists `teacher`;
CREATE TABLE `teacher` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '老师 id',
`name` varchar(50) DEFAULT NULL COMMENT '老师姓名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1003 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into teacher value (1,'老师1');
insert into teacher value (2,'老师2');
insert into teacher value (3,'老师3');
学生:
public class Student {
private int id;
private String name;
private Teacher teacher;
}
老师:
public class Teacher {
private int id;
private String name;
}
1)、按照查询嵌套处理
接口:
List<Student> getAll();
.xml 实现
相当于在 resultMap 中,再执行一次查询
<select id="getAll" resultMap="stusta">
select * from student
</select>
<resultMap id="stusta" type="Student" >
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="tid" column="tid"/>
<!--这里的tid的值,会传递到 getTeacher 中,从而查询出对应教师-->
<association property="teacher" column="tid" javaType="Teacher" select="getTeacher"/>
</resultMap>
<select id="getTeacher" resultType="Teacher">
select * from teacher where id = #{id}
</select>

测试:
@Test
public void getAllTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
/**
* 使用动态代理的方式,生成 mapper 的实现类
*/
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
List<Student> all = mapper.getAll();
for (Student student : all) {
System.out.println(student);
}
sqlSession.close();
}

2)、按照结果嵌套处理
这种方法类似于 联表查询
<!--方法2:按照结果嵌套处理(这种方式更好懂)-->
<select id="getStudentList" resultMap="StudentTeacher">
select s.id sid,s.name sname,t.name tname,t.id tid
from student s,teacher t
where s.tid=t.id
</select>
<resultMap id="StudentTeacher" type="Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<association property="teacher" javaType="Teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
</association>
</resultMap>

按照方便程度来说,明显是第一种方式比较方便(sql写的少)
但是按照性能来说,是第二种性能更好(毕竟只要查询一次数据库)
2、对多关系
一对多的方式和多对一差不多
比如:一个老师拥有多个学生
环境搭建,和刚才一样编写实体类
public class Student {
private int id;
private String name;
private int tid;
}
public class Teacher {
private int id;
private String name;
//一个老师多个学生
private List<Student> students;
}
1)、按照查询嵌套查询
接口:
List<Teacher> getAll();
.xml 实现
这里的 ofType,指明的是集合中元素的泛型

<select id="getAll" resultMap="getStaStu">
select * from teacher
</select>
<resultMap id="getStaStu" type="Teacher">
<id column="id" property="id"/>
<result column="name" property="name"/>
<!--这里的id ,是老师的id ,会自动映射到子查询的中的 tid 中-->
<collection property="students" column="id" javaType="ArrayList" ofType="Student" select="selectStudentByTid"/>
</resultMap>
<select id="selectStudentByTid" resultType="Student">
select * from student where tid =#{tid}
</select>
测试:
@Test
public void getAllTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
/**
* 使用动态代理的方式,生成 mapper 的实现类
*/
TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class);
List<Teacher> all = mapper.getAll();
for (Teacher teacher : all) {
System.out.println(teacher);
}
sqlSession.close();
}

2)、按照结果嵌套查询
接口:
List<Teacher> getAll();
.xml 实现:
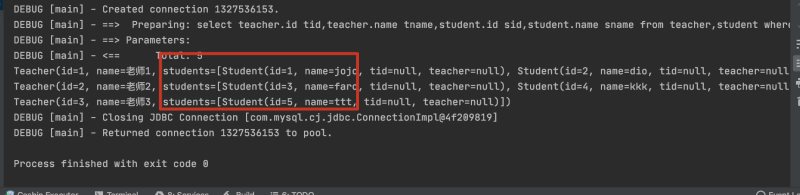
<select id="getAll" resultMap="getStaStu">
select teacher.id tid,teacher.name tname,student.id sid,student.name sname
from teacher,student
where teacher.id=student.tid;
</select>
<resultMap id="getStaStu" type="Teacher">
<id column="tid" property="id"/>
<result column="tname" property="name"/>
<collection property="students" javaType="ArrayList" ofType="Student">
<result column="sid" property="id"/>
<result column="sname" property="name"/>
</collection>
</resultMap>
测试:
@Test
public void getAllTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
/**
* 使用动态代理的方式,生成 mapper 的实现类
*/
TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class);
List<Teacher> all = mapper.getAll();
for (Teacher teacher : all) {
System.out.println(teacher);
}
sqlSession.close();
}
十、动态 SQL
使用动态 SQL ,避免了 SQL 拼接的烦恼
where标签在select中的使用
注意: 在 mybatis 的 xml 实现中 >可以直接使用,但是 <不可以直接使用,必须使用转移符号

<select id="queryByVO" parameterType="QueryVO" resultMap="baseResultMap">
select * from team
<where>
<!-- 如果用户输入了名称,就模糊查询 and teamName like '%?%'-->
<if test="name!=null ">
and teamName like concat(concat('%',#{name}),'%')
</if>
<if test="beginTime!=null ">
and createTime>=#{beginTime}
</if>
<if test="endTime!=null ">
and createTime<=#{endTime}
</if>
<if test="location!=null ">
and location=#{location}
</if>
</where>
</select>
模糊查询:
使用模糊查询的时候,一定要使用 concat 函数,将字符串进行拼接,不能使用 + 号
<select id="getByName" resultType="top.faroz.pojo.Teacher" parameterType="string">
select * from teacher
<where>
<if test="name!=null">
-- 使用 concat 函数,将多个字符串进行拼接
and name like concat(concat('%',#{name}),'%')
</if>
</where>
</select>
set标签在update中的使用
<update id="update1" parameterType="com.kkb.pojo.Team">
update team
<set>
<if test="teamName!=null">
teamName=#{teamName},
</if>
<if test="location!=null">
location=#{location},
</if>
<if test="createTime!=null">
createTime=#{createTime},
</if>
</set>
where teamId=#{teamId}
</update>
forEach标签
批量添加
<insert id="addList" parameterType="arraylist">
INSERT INTO team (teamName,location) VALUES
<!--collection:要遍历的集合;参数是集合类型,直接写list item:遍历的集合中的每一个数据 separator:将遍历的结果用,分割-->
<foreach collection="list" item="t" separator=",">
(#{t.teamName},#{t.location})
</foreach>
</insert>
批量删除
<delete id="delList" >
delete from team where teamId in
<!--collection:要遍历的集合;参数是集合类型,直接写list item:遍历的集合中的每一个数据separator:将遍历的结果用,分割
open="(" close=")":表示将遍历结果用open close包裹起来-->
<foreach collection="list" item="teamId" separator="," open="(" close=")">
#{teamId}
</foreach>
</delete>
SQL 片段
提取SQL片段:
<sql id="if-title-author">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
引用SQL片段:
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<!-- 引用 sql 片段,如果refid 指定的不在本文件中,那么需要在前面加上 namespace -->
<include refid="if-title-author"></include>
<!-- 在这里还可以引用其他的 sql 片段 -->
</where>
</select>
注意:
①、最好基于 单表来定义 sql 片段,提高片段的可重用性
②、在 sql 片段中不要包括 where
十一、分页插件
分页插件,我们使用 pageHelper
1、快速开始
1)、Maven 依赖
<!--pagehelper-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.10</version>
</dependency>
2)、Mybatis全局配置文件中添加插件配置
<plugins>
<!-- 引入 pageHelper插件 -->
<!--注意这里要写成PageInterceptor, 5.0之前的版本都是写PageHelper, 5.0之后要换成PageInterceptor-->
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!--reasonable:分页合理化参数,默认值为false,直接根据参数进行查询。当该参数设置为 true 时,pageNum<=0 时会查询第一页, pageNum>pages(超过总数时),会查询最后一页。 方言可以省略,会根据连接数据的参数url自动推断-->
<!--<property name="reasonable" value="true"/>-->
</plugin>
</plugins>
3)、使用插件
2、PageHelper 介绍
PageHelper 会拦截查询语句,然后添加分页语句
@Test
public void getAllTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
/**
* 使用动态代理的方式,生成 mapper 的实现类
*/
TeamMapper mapper = sqlSession.getMapper(TeamMapper.class);
/**
* 查询页数为1,查询5条
*/
PageHelper.startPage(2,5);
List<Team> all = mapper.getAll();
for (Team team : all) {
System.out.println(team);
}
sqlSession.close();
}

3、PageInfo 介绍
可以用来打印分页的相关信息,如总条数,当前页数,总页数等
@Test
public void getAllTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
/**
* 使用动态代理的方式,生成 mapper 的实现类
*/
TeamMapper mapper = sqlSession.getMapper(TeamMapper.class);
/**
* 查询页数为1,查询5条
*/
PageHelper.startPage(2,5);
List<Team> all = mapper.getAll();
for (Team team : all) {
System.out.println(team);
}
PageInfo<Team> pageInfo = new PageInfo<>(all);
System.out.println("分页信息如下:");
System.out.println("总条数:"+pageInfo.getTotal());
System.out.println("总页数:"+pageInfo.getPages());
System.out.println("当前页数:"+pageInfo.getPageNum());
System.out.println("每页条数:"+pageInfo.getPageSize());
sqlSession.close();
}

十二、缓存
通过使用缓存,可以在第一次查询的时候,将查询到的信息,放入缓存,这样,在第二次查询的时候,就会走缓存,从而,减轻数据库压力、提高查询效率,解决高并发问题。
MyBatis 也有一级缓存和二级缓存,并且预留了集成第三方缓存的接口。
1、一级缓存
自动开启,SqlSession级别的缓存
在操作数据库时需要构造 sqlSession对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数 据将不再从数据库查询,从而提高查询效率。
当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。 Mybatis默认开启一级缓存,存在内存中(本地缓存)不能被关闭,可以调用clearCache()来清空本地缓存,或者改变缓存的作用域。
1)、一级缓存介绍

当用户发起第一次查询team=1001的时候,先去缓存中查找是否有team=1001的对象;如果没有,继续向数据中发送查询语句,查询成功之后会将teamId=1001的结果存入缓存 中;
当用户发起第2次查询team=1001的时候,先去缓存中查找是否有team=1001的对象,因为第一次查询成功之后已经存储到缓存中,此时可以直接从缓存中获取到该数据,意味 着不需要再去向数据库发送查询语句。
如果SqlSession执行了commit(有增删改的操作),此时该SqlSession对应的缓存区域被整个清空,目的避免脏读。
**前提:**SqlSession未关闭。
2)、清空缓存的方式
1s、 session.clearCache( ) ; 2、 execute update(增删改) ; 3、 session.close( ); 4、 xml配置 flushCache="true" ; 5、 rollback; 6、 commit。
2、二级缓存
Mapper 级别的缓存,可以跨 sqlSession
1)、二级缓存介绍
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace。
不同的sqlSession两次执行相同namespace下的sql语句参数相同即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获 取数据将不再从数据库查询,从而提高查询效率。
Mybatis默认没有开启二级缓存,需要在setting全局参数中配置开启二级缓存。 如果缓存中有数据就不用从数据库中获取,大大提高系统性能。
与一级缓存一样,一旦反生 增删改,并commit,就会清空缓存的数据,从而避免数据脏读
其原理图如下:

2)、使用二级缓存

3)、二级缓存的禁用
为什么需要禁用二级缓存?
在某些情况下,有一些数据被修改的频率是十分频繁的,一旦开启二级缓存,那么对其缓存清空的操作也会十分频繁,从而增大数据库的压力,我们可以但为这些 sql 查询,关闭二级缓存:
在开始了二级缓存的XML中对应的statement中设置useCache=false禁用当前Select语句的二级缓存,意味着该SQL语句每次只需都去查询数据库,不会查询缓存。 useCache默认值是true。对于一些很重要的数据尽不放在二级缓存中。
4)、缓存的属性配置
<cache>
<property name="eviction" value="LRU"/><!--回收策略为LRU-->
<property name="flushInterval" value="60000"/><!--自动刷新时间间隔为60S-->
<property name="size" value="1024"/><!--最多缓存1024个引用对象-->
<property name="readOnly" value="true"/><!--只读-->
</cache>
源码如下:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface CacheNamespace {
Class<? extends Cache> implementation() default PerpetualCache.class;
Class<? extends Cache> eviction() default LruCache.class;
long flushInterval() default 0L;
int size() default 1024;
boolean readWrite() default true;
boolean blocking() default false;
Property[] properties() default {};
}
/**属性介绍:
1.映射语句文件中的所有select语句将会被缓存;
2.映射语句文件中的所有CUD操作将会刷新缓存;
3.缓存会默认使用LRU(Least Recently Used)算法来收回;
3.1、LRU – 最近最少使用的:移除最长时间不被使用的对象。
3.2、FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
3.3、SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。 3.4、WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
4.缓存会根据指定的时间间隔来刷新(默认情况下没有刷新间隔,缓存仅仅调用语句时刷新);
5.缓存会存储列表集合或对象(无论查询方法返回什么),默认存储1024个对象。
6.缓存会被视为是read/write(可读/可写)的缓存,意味着检索对象不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。*/
如果想在命名空间中共享相同的缓存配置和实例,可以使用cache-ref 元素来引用另外一个缓存。
所谓命名空间,其实就是一个个 xml 实现
<cache-ref namespace="com.kkb.mapper.TeamMapper" /> //引用TeamMapper命名空间中的cache。
十三、反向生成器
使用反向生成器,就可以根据数据库表格,去自动生成持久层的代码
1、配置
略
2、使用
这里介绍其中的部分使用注意点
1)、动态更新/插入
带 selective 关键字的,表示动态改变
//动态插入 mapper.insertSelective(User user); //动态更新 mapper.updateByPrimaryKeySelective(User user);
对于插入,是对插入对象中,属性为空的地方,不写上插入 sql
对于更新,是对属性为空的部分,不执行更新操作()即不会用新对象的空洞部分,去覆盖元数据区
2)、多条件查询
多条件查询,需要用到 XxxExample

使用步骤如下:
//1、创建被查询对象的 Example 对象
EbookExample ebookExample = new EbookExample();
//2、创建盛放查询条件的容器
EbookExample.Criteria criteria = ebookExample.createCriteria();
//3、在容器中,防止多查询条件
criteria.andNameLike("spring");//模糊查询
criteria.andNameEqualTo("spr");//等于
//...还有很多,对于每个属性,都有等量的多查询条件可供选择
//4、传入 Example 对象,进行多条件查询
mapper.selectByExample(ebookExample);
十四.总结
以上就是本文针对MyBatis入门学习教程-MyBatis快速入门的全部内容,希望大家多多关注我们的其他内容!
相关推荐
-

Java集合之HashMap用法详解
本文实例讲述了Java集合之HashMap用法.分享给大家供大家参考,具体如下: HashMap是最常用的Map集合,它的键值对在存储时要根据键的哈希码来确定值放在哪里. HashMap 中作为键的对象必须重写Object的hashCode()方法和equals()方法 import java.util.Map; import java.util.HashMap; public class lzwCode { public static void main(String [] args) { M
-
如何简单使用mybatis注解
使用注解开发 本质:反射机制实现 底层:动态代理 1.注解在接口上的实现 public interface UserMapper { @Select("select * from user") List<User> getUsers(); } 2.使用注解时,需要在核心配置文件中绑定接口 <mappers> <mapper class="com.xiao.dao.UserMapper"/> </mappers> 3.测
-
Java集合系列之HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在定位查找元素时会优于LinkedList,而LinkedList在添加删除元素时会优于ArrayList.而本篇介绍的HashMap综合了二者的优势,它的底层是基于哈希表实现的,如果不考虑哈希冲突的话,HashMap在增删改查操作上的时间复杂度都能够达到惊人的O(1).我们先看看它所基于的哈希表的结
-
详解mybatis多对一关联查询的方式
根据ID查询学生信息,要求该学生的教师和班级信息一并查出 第一种关联方式 1.修改实体类Student,追加关联属性,用于封装关联的数据 修改完以后重新生成get set方法还有toString方法 private Teacher teacher; private Classes classes; 2.修改TeacherMapper相关配置 1.接口类 增加 Teacher selectTeacherById(Integer tid); 2.xml映射文件 增加 <sql id="para
-
mybatisplus 的SQL拦截器实现关联查询功能
由于项目中经常会使用到一些简单地关联查询,但是mybatisplus还不支持关联查询,不过在看官方文档的时候发现了mybatisplus的SQL拦截器(其实也是mybatis的)就想着能不能在SQL执行的时候做一些处理以至于可以支持关联查询,于是就动手开始了,目前还只是一个初步的demo,但是一些基本的关联查询功能经过验证是没有问题的 环境信息 jdk: 1.8 springboot: 2.3.4.RELEASE mybatisplus: 3.4.2 lombok:1.18.12 代码设计 代码
-
mybatis-plus雪花算法自动生成机器id原理及源码
1.雪花算法原理 雪花算法使用一个 64 bit 的 long 型的数字作为全局唯一 id.这 64 个 bit 中,其中 1 个 bit 是不用的,然后用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号. 1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数.生成的id一般都是用整数,所以最高位固定为0. 41bit-时间戳,用来记录时间戳,毫秒级. 10bit-工作机器id,用来记录工作机器id. 12bit-序列号,序列号,用来
-
Mybatis CURD及模糊查询功能的实现
命名空间namespace: 配置文件中namespace中的名称为对应Mapper接口或者Dao接口的完整包名,必须一致! 1.查询(select) select: 接口中的方法名与映射文件中的SQL语句ID 一一对应 id parameterType resultType 案例:根据id查询用户 1.写接口(在UserMapper中添加对应的方法) public interface UserMapper { //根据ID查询用户 User getuserByID(int id); } 2.U
-
关于mybatis的一级缓存和二级缓存的那些事儿
一.缓存是什么 缓存其实就是存储在内存中的临时数据,这里的数据量会比较小,一般来说,服务器的内存也是有限的,不可能将所有的数据都放到服务器的内存里面,所以, 只会把关键数据放到缓存中,缓存因为速度快,使用方便而出名! 二.为什么需要缓存 BS架构里面,用户的所有操作都是对数据库的增删改查,其中查询的操作是最多的,但如果用户想要某个数据时每次都去数据库查询,这无疑会增加数据库的压力,而且获取时间效率也会降低,所以为了解决这些问题,缓存应用而生,使用了缓存之后,服务器只需要查询一次数据库,然后将数据
-
浅谈MyBatis-plus入门使用
一.初始化 SpringBoot 项目 首先使用 Spring Initializer 脚手架初始化一个 SpringBoot 项目.然后在 pom.xml 中添加相关的依赖: <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency&g
-
MyBatis入门学习教程-MyBatis快速入门
目录 Mybatis 一.快速开始 1.创建 Maven 项目 2.导入 Maven 依赖 3.配置 Maven 插件 4.新建数据库,导入表格 5.编写 Mybatis 配置文件 6.编写实体类 7.编写 mapper 接口 8.编写 mapper 实现 9.Mybatis 配置文件中,添加 mapper 映射 10.编写 Mybatis 工具类 11.测试 二.日志添加 1.添加 Maven 依赖 2.添加 log4j 配置 3.Mybatis 中配置 LOG 4.执行测试 三.Mybati
-
Spring boot学习教程之快速入门篇
前言 首先来说一下为什么使用 Spring Boot,之前我用的后端 WEB 开发框架一直都是 PlayFramework的 1.2.7 版本(目前已经停止更新), 不得不说这个框架非常好用,但是由于 Play2.x 版本和 Play1.x 版本差别巨大,并且不兼容,所以现在面临着选择新的框架的问题,问了下身边的朋友,发现他们都在用 Spring ,然而我发现 Spring 的话,经常要配置各种东西,习惯了 Play 的简单明了的配置方式,确实有些不习惯 Spring ,这个时候发现了 Spri
-
MyBatis入门学习教程(一)-MyBatis快速入门
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis .2013年11月迁移到Github. iBATIS一词来源于"internet"和"abatis"的组合,是一个基于Java的持久层框架.iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO) 首先给大家介绍MyBatis的含义
-
mybatis快速入门学习教程新手注意问题小结
什么是mybatis MyBatis是支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索.MyBatis使用简单的XML或注解用于配置和原始映射,将接口和Java的POJOs(Plan Old Java Objects,普通的Java对象)映射成数据库中的记录. orm工具的基本思想 无论是用过的hibernate,mybatis,你都可以法相他们有一个共同点: 1. 从配置文件(通常是XML配置文件中)得到 ses
-
mybatis框架入门学习教程
MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以使用简单的XML或注解用于配置和原始映射,将接口和Java的POJO(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录. 1.创建工程,导入jar包 创建一个java工程或者web工程都可以,然后导入mybatis的jar包和依赖包还有数据库的jar包,本人使用Oracle10g数据库
-
Vue + OpenLayers 快速入门学习教程
Openlayers 是一个模块化.高性能并且功能丰富的WebGIS客户端的JavaScript包,用于显示地图及空间数据,并与之进行交互,具有灵活的扩展机制. 简单来说,使用 Openlayers(后面简称ol) 可以很灵活自由的做出各种地图和空间数据的展示.而且这个框架是完全免费和开源的. 前言 本文记录 Vue 使用 OpenLayers 入门,使用 OpenLayers 创建地图组件,分别使用 OpenLayers 提供的地图和本地图片做为地图. Overview OpenLayers
-
Python装饰器入门学习教程(九步学习)
装饰器(decorator)是一种高级Python语法.装饰器可以对一个函数.方法或者类进行加工.在Python中,我们有多种方法对函数和类进行加工,比如在Python闭包中,我们见到函数对象作为某一个函数的返回结果.相对于其它方式,装饰器语法简单,代码可读性高.因此,装饰器在Python项目中有广泛的应用. 这是在Python学习小组上介绍的内容,现学现卖.多练习是好的学习方式. 第一步:最简单的函数,准备附加额外功能 # -*- coding:gbk -*- '''示例1: 最简单的函数,表
-
Ajax入门学习教程(一)
1 什么是AJAX AJAX(Asynchronous JavaScript And XML)翻译成中文就是"异步Javascript和XML".即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML). AJAX还有一个最大的特点就是,当服务器响应时,不用刷新整个浏览器页面,而是可以局部刷新.这一特点给用户的感受是在不知不觉中完成请求和响应过程. 与服务器异步交互: 浏览器页面局部刷新: 2. 同步交互与异步交互 同步交互:客户端发出一个
-
Kotlin入门学习教程之可见性修饰符
目录 前言 1.包场景下的可见性修饰符 2.类内部声明的成员 总结 前言 在Kotlin中四种可见性修饰符:private.protected.internal.public,如果没有显示指定修饰符的话,默认可见性是public. 四种修饰符的说明 public修饰符表示 公有 .此修饰符的范围最大.当不声明任何修饰符时,系统会默认使用此修饰符. internal修饰符表示 模块 .对于模块的范围在下面会说明. protected修饰符表示 私有`+`子类.值得注意的是,此修饰符不能用于顶层声明
-
详解Spring batch 入门学习教程(附源码)
Spring batch 是一个开源的批处理框架.执行一系列的任务. 在 spring batch 中 一个job 是由许多 step 组成的.而每一个 step 又是由 READ-PROCESS-WRITE task或者 单个 task 组成. 1. "READ-PROCESS-WRITE" 处理,根据字面意思理解就可以: READ 就是从资源文件里面读取数据,比如从xml文件,csv文件,数据库中读取数据. PROCESS 就是处理读取的数据 WRITE 就是将处理过的数据写入到