关于Tensorflow分布式并行策略
tensorFlow中主要包括了三种不同的并行策略,其分别是数据并行、模型并行、模型计算流水线并行,具体参考Tenssorflow白皮书,在接下来分别简单介绍三种并行策略的原理。
数据并行
一个简单的加速训练的技术是并行地计算梯度,然后更新相应的参数。数据并行又可以根据其更新参数的方式分为同步数据并行和异步数据并行,同步的数据并行方式如图所示,tensorflow图有着很多的部分图模型计算副本,单一的客户端线程驱动整个训练图,来自不同的设备的数据需要进行同步更新。这种方式在实现时,主要的限制就是每一次更新都是同步的,其整体计算时间取决于性能最差的那个设备。

数据并行还有异步的实现方式,如图所示,与同步方式不同的是,在处理来自不同设备的数据更新时进行异步更新,不同设备之间互不影响,对于每一个图副本都有一个单独的客户端线程与其对应。在这样的实现方式下,即使有部分设备性能特别差甚至中途退出训练,对训练结果和训练效率都不会造成太大影响。但是由于设备间互不影响,所以在更新参数时可能其他设备已经更好的更新过了,所以会造成参数的抖动,但是整体的趋势是向着最好的结果进行的。所以说这种方式更适用于数据量大,更新次数多的情况。

模型并行
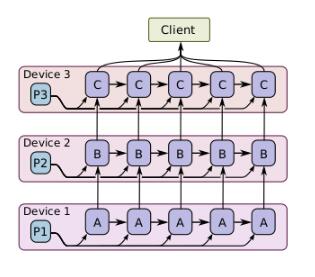
一个模型并行训练的例子如图所示,其针对的训练对象是同一批样本数据,但是将不同的模型计算部分分布在不同的计算设备上同时执行。
模型计算流水线并行
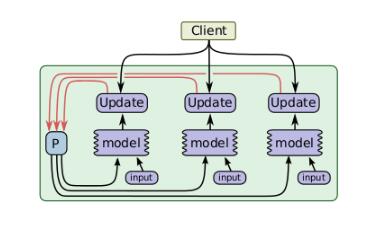
此并行方式主要针对在同一个设备中并发实现模型的计算,如图是其并发计算步骤,可以发现它实际上与异步数据并行有些相似,但是唯一不同的是此方式的并行发生在同一个设备上,而不是在不同的设备之间。并且在计算一批简单的样例时,允许进行“填充间隙”,这可以充分利用空闲的设备资源。
以上这篇关于Tensorflow分布式并行策略就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用Tensorflow实现可视化中间层和卷积层
为了查看网络训练的效果或者便于调参.更改结构等,我们常常将训练网络过程中的loss.accurcy等参数. 除此之外,有时我们也想要查看训练好的网络中间层输出和卷积核上面表达了什么内容,这可以帮助我们思考CNN的内在机制.调整网络结构或者把这些可视化内容贴在论文当中辅助说明训练的效果等. 中间层和卷积核的可视化有多种方法,整理如下: 1. 以矩阵(matrix)格式手动输出图像: 用简单的LeNet网络训练MNIST数据集作为示例: x = tf.placeholder(tf.float32,
-
tensorflow实现简单的卷积神经网络
本文实例为大家分享了Android九宫格图片展示的具体代码,供大家参考,具体内容如下 一.知识点总结 1. 卷积神经网络出现的初衷是降低对图像的预处理,避免建立复杂的特征工程.因为卷积神经网络在训练的过程中,自己会提取特征. 2. 灵感来自于猫的视觉皮层研究,每一个视觉神经元只会处理一小块区域的视觉图像,即感知野.放到卷积神经网络里就是每一个隐含节点只与设定范围内的像素点相连(设定范围就是卷积核的尺寸),而全连接层是每个像素点与每个隐含节点相连.这种感知野也称之为局部感知. 例如,一张10
-

详解Tensorflow数据读取有三种方式(next_batch)
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
浅谈tensorflow1.0 池化层(pooling)和全连接层(dense)
池化层定义在tensorflow/python/layers/pooling.py. 有最大值池化和均值池化. 1.tf.layers.max_pooling2d max_pooling2d( inputs, pool_size, strides, padding='valid', data_format='channels_last', name=None ) inputs: 进行池化的数据. pool_size: 池化的核大小(pool_height, pool_width),如[3,3].
-
关于Tensorflow分布式并行策略
tensorFlow中主要包括了三种不同的并行策略,其分别是数据并行.模型并行.模型计算流水线并行,具体参考Tenssorflow白皮书,在接下来分别简单介绍三种并行策略的原理. 数据并行 一个简单的加速训练的技术是并行地计算梯度,然后更新相应的参数.数据并行又可以根据其更新参数的方式分为同步数据并行和异步数据并行,同步的数据并行方式如图所示,tensorflow图有着很多的部分图模型计算副本,单一的客户端线程驱动整个训练图,来自不同的设备的数据需要进行同步更新.这种方式在实现时,主要的限制就是
-
tensorflow之并行读入数据详解
最近研究了一下并行读入数据的方式,现在将自己的理解整理如下,理解比较浅,仅供参考. 并行读入数据主要分 1. 创建文件名列表 2. 创建文件名队列 3. 创建Reader和Decoder 4. 创建样例列表 5. 创建批列表(读取时可要可不要,一般情况下样例列表可以执行读取数据操作,但是在实际训练的时候往往需要批列表来分批进行数据的组织,提取) 其具体流程如下: 一. 文件名列表: 文件名列表是一个list类型的数据,里面的内容是需要用的数据文件名.可以使用常规的python语法入:[file1
-
Mapreduce分布式并行编程
目录 1.什么是并行计算 2.现在mapreduce能做什么? map:映射 reduce:做比较,工作整合,上下游 有些操作放在map.reduce里面都可以 1.project(投射)map完成 2.filter(过滤)map完成 3.key(汇集) 数据SQL: oss和hive的区别? 1. 搭建各类环境 2. 搭建.配置zookeeper 3. 启动zookeeper 4. 安装配置java 5. 主从节点格式化 6. 启动集群 7. 安装Scala 8. 启动spark集群 9. j
-
TensorFlow神经网络优化策略学习
在神经网络模型优化的过程中,会遇到许多问题,比如如何设置学习率的问题,我们可通过指数衰减的方式让模型在训练初期快速接近较优解,在训练后期稳定进入最优解区域:针对过拟合问题,通过正则化的方法加以应对:滑动平均模型可以让最终得到的模型在未知数据上表现的更加健壮. 一.学习率的设置 学习率设置既不能过大,也不能过小.TensorFlow提供了一种更加灵活的学习率设置方法--指数衰减法.该方法实现了指数衰减学习率,先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训
-
Java分布式锁的三种实现方案
方案一:数据库乐观锁 乐观锁通常实现基于数据版本(version)的记录机制实现的,比如有一张红包表(t_bonus),有一个字段(left_count)记录礼物的剩余个数,用户每领取一个奖品,对应的left_count减1,在并发的情况下如何要保证left_count不为负数,乐观锁的实现方式为在红包表上添加一个版本号字段(version),默认为0. 异常实现流程 -- 可能会发生的异常情况 -- 线程1查询,当前left_count为1,则有记录 select * from t_bonus
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-
TensorFlow实现卷积神经网络CNN
一.卷积神经网络CNN简介 卷积神经网络(ConvolutionalNeuralNetwork,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因
-
TensorFlow搭建神经网络最佳实践
一.TensorFLow完整样例 在MNIST数据集上,搭建一个简单神经网络结构,一个包含ReLU单元的非线性化处理的两层神经网络.在训练神经网络的时候,使用带指数衰减的学习率设置.使用正则化来避免过拟合.使用滑动平均模型来使得最终的模型更加健壮. 程序将计算神经网络前向传播的部分单独定义一个函数inference,训练部分定义一个train函数,再定义一个主函数main. 完整程序: #!/usr/bin/env python3 # -*- coding: utf-8 -*- ""&
-
tensorflow构建BP神经网络的方法
之前的一篇博客专门介绍了神经网络的搭建,是在python环境下基于numpy搭建的,之前的numpy版两层神经网络,不能支持增加神经网络的层数.最近看了一个介绍tensorflow的视频,介绍了关于tensorflow的构建神经网络的方法,特此记录. tensorflow的构建封装的更加完善,可以任意加入中间层,只要注意好维度即可,不过numpy版的神经网络代码经过适当地改动也可以做到这一点,这里最重要的思想就是层的模型的分离. import tensorflow as tf import nu
-
一文学会Hadoop与Spark等大数据框架知识
目录 一个实际的需求场景:日志分析 Hadoop Hadoop的生态坏境 Spark Spark整体架构 Spark核心概念 Spark的核心组件 海量数据的存储问题很早就已经出现了,一些行业或者部门因为历史的积累,数据量也达到了一定的级别.很早以前,当一台电脑无法存储这么庞大的数据时,采用的解决方案是使用NFS(网络文件系统)将数据分开存储.但是这种方法无法充分利用多台计算机同时进行分析数据. 一个实际的需求场景:日志分析 日志分析是对日志中的每一个用户的流量进行汇总求和.对于一个日志文件,如