正则表达式量词与贪婪的使用详解
目录
- 0.写在前面
- 1.量词
- 2.贪婪模式前传
- 2.1 使用 a+ 进行匹配
- 2.2 使用 a* 进行匹配
- 3.贪婪模式
- 4.非贪婪模式
- 5.独占模式
- 5.1 贪婪匹配过程
- 5.2 非贪婪匹配过程
- 5.3 独占匹配过程
- 6.写在最后
0.写在前面
在上一篇文章中,我们学习了正则的一些基础元字符,相信大家都已经忘却的差不多了,可以点击上面的链接再温习下。
今天我们一起来学习下正则中量词的三种匹配模式,贪婪模式、非贪婪模式、独占模式,这些模式会改变正则中量词的匹配行为,是每次贪婪的匹配到更多呢,还是不贪婪见好就收呢,如果不了解这些,我们写出的正则很可能是错误的,甚至会引发严重的线上性能问题。
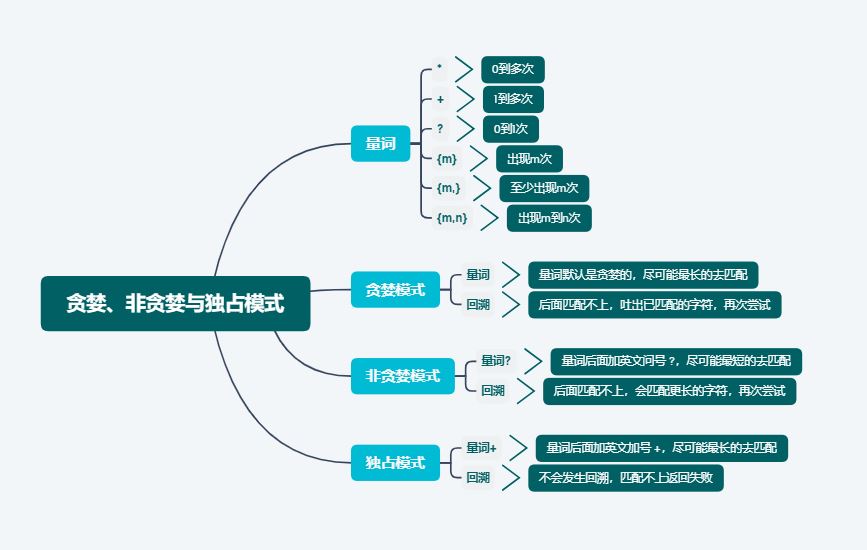
1.量词
本篇文章所讲的内容和量词关系比较密切,先回顾下:
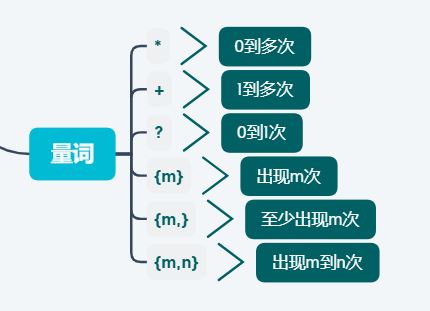
我们还可以用 {m,n} 的方式来表示 * + ? 这3种元字符:
| 元字符 | 同义表示方法 | 示例 |
|---|---|---|
| * | {0,} | ab* 可以匹配 a 或者 abb |
| + | {1,} | ab+ 可以匹配 ab 或者 abb 但不能匹配 a |
| ? | {0,1} | ab? 可以匹配 a 或者 ab 但不能匹配 abb |
2.贪婪模式前传
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尽可能最大长度的去匹配目标字符串,我们用正则 a+ 和 a* 来匹配字符串 aaabb 测试一下。
2.1 使用 a+ 进行匹配
可以看到只匹配到了1个结果 aaa
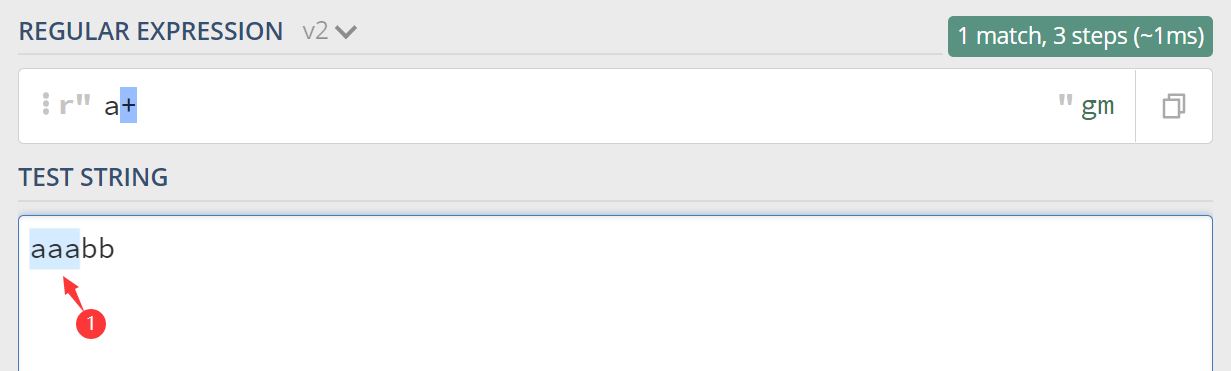
对应的 Python 代码如下:
import re print(re.findall(r'a+', 'aaabb')) 输出:['aaa']
2.2 使用 a* 进行匹配
可以看到匹配到了4个结果,其中还有3个是空字符串
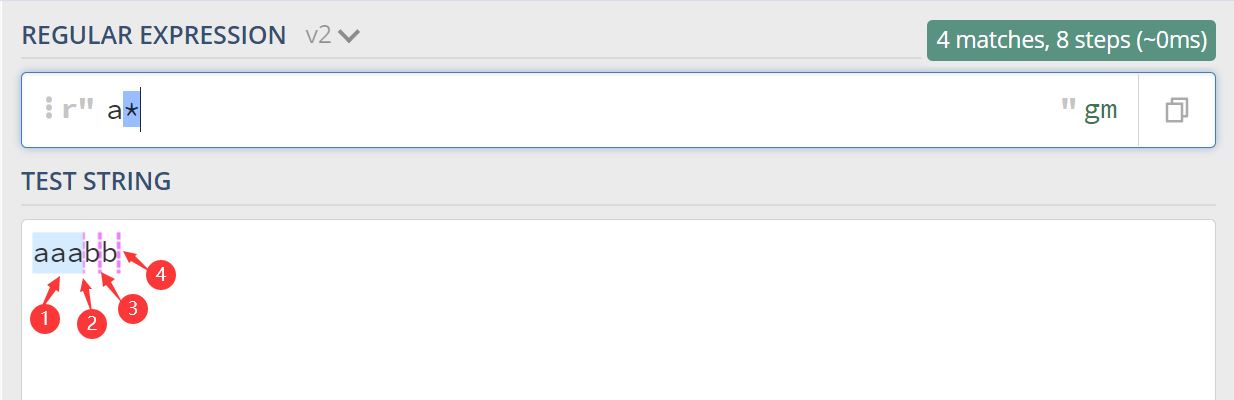
对应的 Python 代码如下:
import re print(re.findall(r'a*', 'aaabb')) 输出:['aaa', '', '', '']
为什么会匹配到空字符串呢?因为星号(*)代表匹配0到多次,匹配0次就是空字符串,那前面还有个 aaa 呢,为什么 aaa 之间的空字符串没有被匹配到?
这就引入到了我们今天要讲的,贪婪模式与非贪婪模式,从字面上很好理解,贪婪模式就是尽可能多的匹配,非贪婪模式就是尽可能少的匹配。
3.贪婪模式
一起来分析下上面正则 a* 的匹配过程:
| 字符串 | a | a | a | b | b | 空字符串 |
|---|---|---|---|---|---|---|
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 |
| 匹配 | 开始 | 结束 | 说明 | 匹配内容 |
|---|---|---|---|---|
| 第一次 | 0 | 3 | 到第一个字母b发现不匹配,输出aaa | aaa |
| 第二次 | 3 | 3 | 匹配剩下的bb,发现匹配不上,输出空字符串 | 空字符串 |
| 第三次 | 4 | 4 | 匹配剩下的b,发现匹配不上,输出空字符串 | 空字符串 |
| 第四次 | 5 | 5 | 匹配剩下的空字符串,输出空字符串 | 空字符串 |
a* 在匹配字符串 aaabb 时,会尽可能多的把前面的 a 都匹配上,直到第一个字母 b 不满足要求为止,匹配上3个 a,后面每次匹配的都是空字符串。
看到这里,相信你已经对贪婪模式有了更深的印象,贪婪模式的特点就是尽可能进行最大长度匹配,就是有多少要多少,下面我们在一起来看下与它完全相反的匹配模式。
4.非贪婪模式
上面讲完了贪婪模式,贪婪模式是尽可能最大长度匹配,非贪婪模式就是尽可能最小长度匹配,在量词的后面加一个问号(?),就成了非贪婪模式,比如 a*?
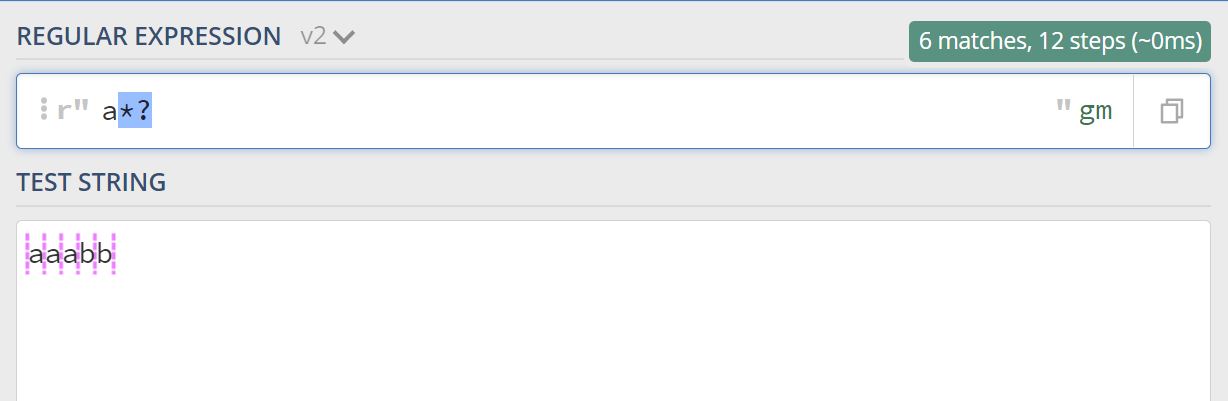
对应的 Python 代码如下:
import re // 贪婪匹配 print(re.findall(r'a*', 'aaabb')) 输出:['aaa', '', '', ''] // 非贪婪匹配 print(re.findall(r'a*?', 'aaabb')) 输出:['', 'a', '', 'a', '', 'a', '', '', '']
学完了贪婪模式与非贪婪模式,你可能会问,我什么情况下会用到呢,下面举个栗子感受下:
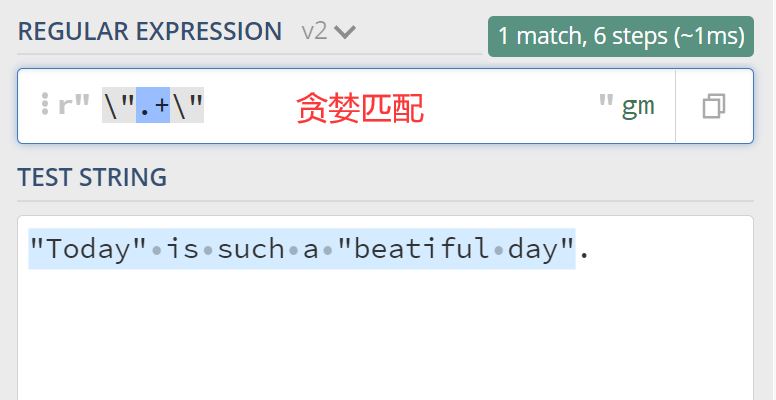
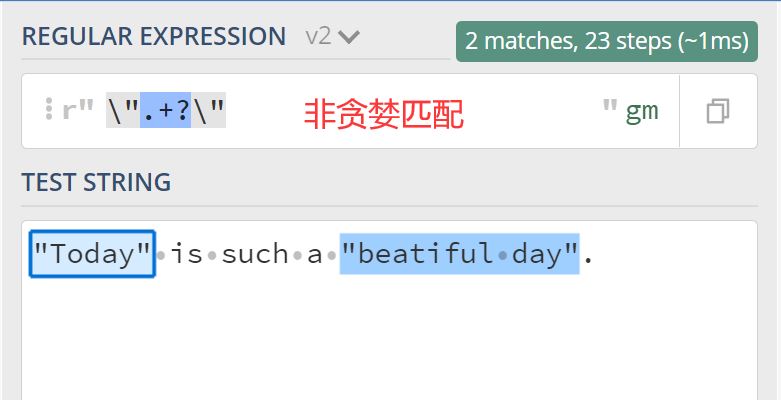
需求是查找一段字符串中,所有双引号括起来的内容,上面使用贪婪匹配与非贪婪匹配的对比,差别很明显对吧。
5.独占模式
不管是贪婪模式,还是非贪婪模式,匹配过程中都需要发生回溯才能完成想要的功能,但是在有一些场景,我们不需要回溯,匹配不上直接返回失败就可以了,因此正则匹配中还有另外一种模式,独占模式,它和贪婪模式很像,但匹配过程中不会发生回溯,在一些使用场景中性能会更好。
先来讲讲什么是回溯,再举个栗子,有一个正则表达式和目标字符串,我们分别看下在三种匹配模式下都发生了什么:
5.1 贪婪匹配过程
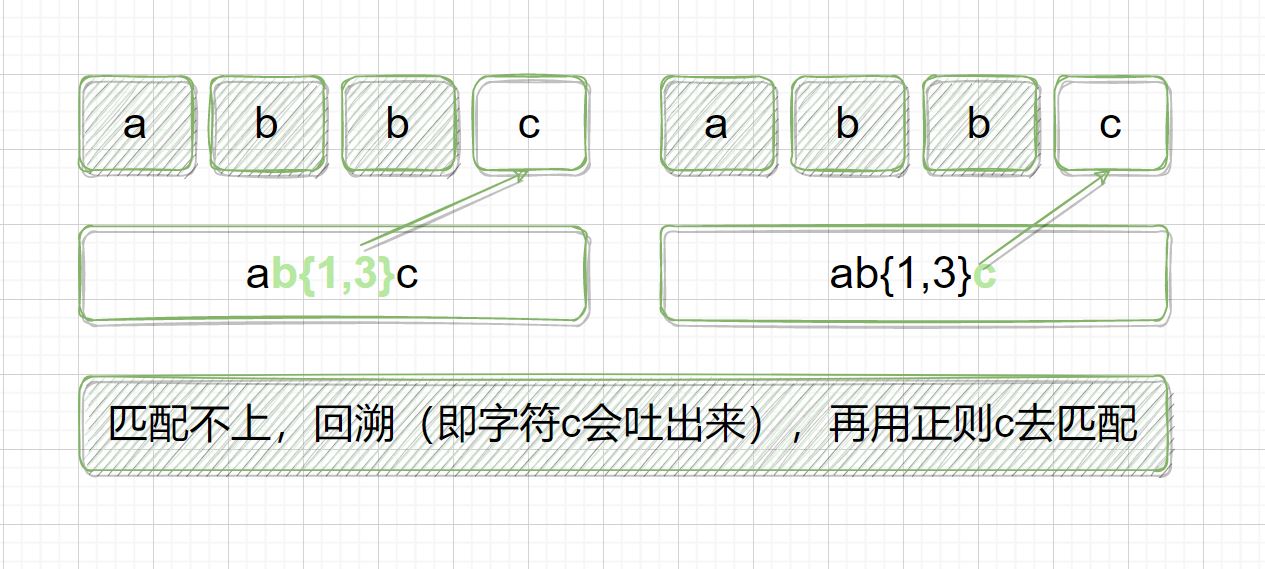
正则表达式:ab{1,3}c
目标字符串:abbc
在匹配时,b{1,3} 会尽可能长的去匹配目标字符串,匹配完 abb 之后,因为要尽可能长的匹配(3个 b),目标字符串中的c就会匹配不上,这个时候会发生向前回溯,吐出当前字符 c,用正则中的 c 去匹配,匹配成功。
import regex
print(regex.findall(r'ab{1,3}c', 'abbc'))
输出:['abbc']
5.2 非贪婪匹配过程
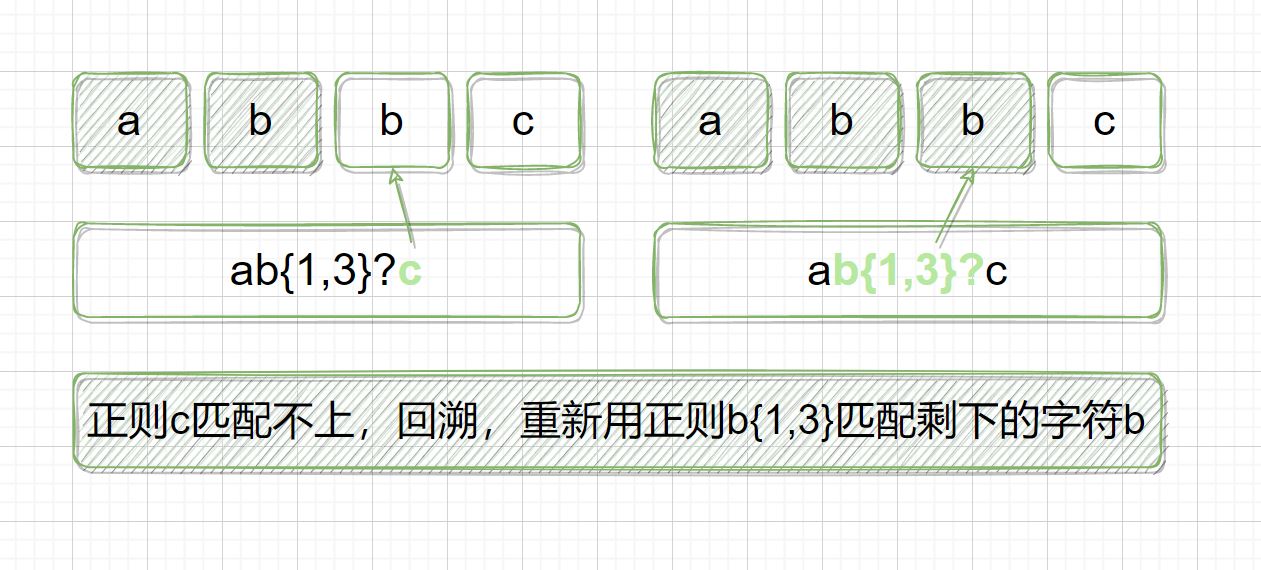
正则表达式:ab{1,3}?c
目标字符串:abbc
在匹配时,b{1,3} 会尽可能短的去匹配目标字符串,匹配完 ab 之后,会直接用正则 c 去匹配目标字符串剩下的 b,匹配不上,发生向前回溯,重新用正则 b{1,3} 匹配 目标字符串剩下的 b,然后正则 c 匹配 目标字符串剩下的 c,匹配成功。
import regex
print(regex.findall(r'ab{1,3}?c', 'abbc'))
输出:['abbc']
5.3 独占匹配过程
在量词后面加上 + 就是独占模式。
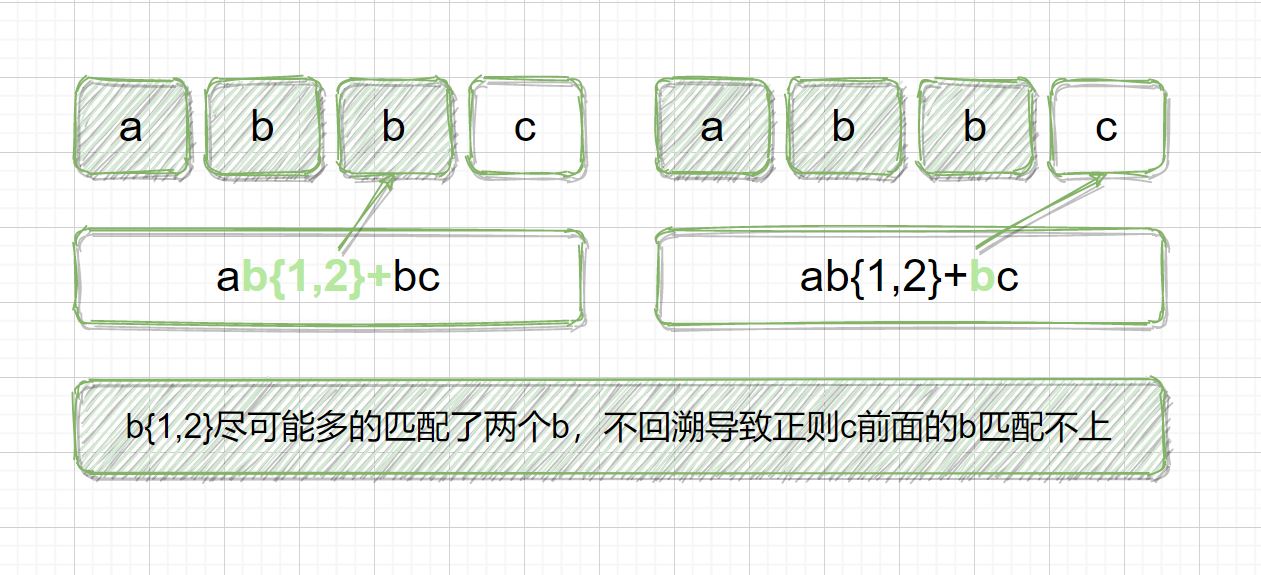
正则表达式:ab{1,2}+bc
目标字符串:abbc
在匹配时,b{1,2} 会尽可能长的去匹配目标字符串,匹配完 abb 之后,会用正则 b 匹配目标字符串剩下的 c,匹配不上,不回溯,匹配失败。
import regex
print(regex.findall(r'ab{1,2}+bc', 'abbc'))
输出:[]
6.写在最后
最后在总结下上面讲到的内容:
到这里,正则表达式的量词与贪婪就讲完了,如果有问题可以给我留言评论,谢谢。
正则表达式在线校验工具:https://regex101.com/
到此这篇关于正则表达式量词与贪婪的使用详解的文章就介绍到这了,更多相关正则表达式 量词与贪婪内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

正则表达式之 贪婪与非贪婪模式详解(概述)
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配.非贪婪模式只被部分NFA引擎所支持. 属于贪婪模式的量词,也叫做匹配优先量词,包括: "{m,n}"."{m,}"."?"."*"和"+". 在一些使用NFA引擎的语言中,在匹配优先量词后加上"?",即变成属于非
-
正则表达式(regex) 贪婪模式、懒惰模式使用方法
正则表达式贪婪匹配模式,对于初学者,往往也很容易出错.有时候需要匹配一个段代码内容,发现匹配与想要不一致.发现原来,跟贪婪模式有关系.如下,我们看下例子: 什么是贪婪模式 字符串有: "<h3>abd</h3><h3>bcd</h3>",我们想匹配<h3>-</h3>内容,正则表达式如下: 1.h3开头与结尾,"<h3>待添加</h3>" <h3></h
-
[正则表达式]贪婪模式与非贪婪模式
复制代码 代码如下: /** ** author: site120 ** function : get script part from html document **/ var loadJs = function(str , delayTime) { var delayTime = delayTime || 100; var regExp_scriptTag = new RegExp("<\\s*sc
-
小议正则表达式效率 贪婪、非贪婪与回溯
先扫盲一下什么是正则表达式的贪婪,什么是非贪婪?或者说什么是匹配优先量词,什么是忽略优先量词? 好吧,我也不知道概念是什么,来举个例子吧. 某同学想过滤之间的内容,那是这么写正则以及程序的. 复制代码 代码如下: $str = preg_replace('%<script>.+?</script>%i','',$str);//非贪婪 看起来,好像没什么问题,其实则不然.若 复制代码 代码如下: $str = '<script<script>alert(docume
-
浅谈php正则表达式中的非贪婪模式匹配的使用
通常我们会这么写: 复制代码 代码如下: $str = "http://www.baidu/.com?url=www.sina.com/"; preg_match("/http:(.*)com/", $str, $matches); print_r($matches); 结果: 复制代码 代码如下: Array ( [0] => http://www.baidu/.com?url=www.sina.com [1] => //www.baidu/.com?
-
正则表达式量词与贪婪的使用详解
目录 0.写在前面 1.量词 2.贪婪模式前传 2.1 使用 a+ 进行匹配 2.2 使用 a* 进行匹配 3.贪婪模式 4.非贪婪模式 5.独占模式 5.1 贪婪匹配过程 5.2 非贪婪匹配过程 5.3 独占匹配过程 6.写在最后 0.写在前面 在上一篇文章中,我们学习了正则的一些基础元字符,相信大家都已经忘却的差不多了,可以点击上面的链接再温习下. 今天我们一起来学习下正则中量词的三种匹配模式,贪婪模式.非贪婪模式.独占模式,这些模式会改变正则中量词的匹配行为,是每次贪婪的匹配到更多呢,还是
-
轻松入门正则表达式之非贪婪匹配篇详解
非贪婪匹配 (.*?) import re a = '456qwe789rty123abc' re=re.findall('456(.*?)789',a) print(re) 通常情况,满足匹配规则"456(.*?)789"的内容通常不止一个,那么findall()函数会从字符串的起始位置开始寻找文本A,找到后开始寻找文本B,当找到第一个文本B后,暂时停止寻找,将文本A和文本B之间的内容存入列表:然后继续寻找文本A,并重复之前的步骤,直到到达字符串的结束位置,并将所有匹配到的内容存入列
-
正则表达式中问号(?)的正确用法详解
目录 1.直接跟随在子表达式后面 2.非贪婪匹配 3.非获取匹配 4.断言 参考资料: 正则表达式中“?”的用法大概有以下几种 1.直接跟随在子表达式后面 这种方式是最常用的用法,具体表示匹配前面的一次或者0次,类似于{0,1},如:abc(d)?可匹配abc和abcd 2.非贪婪匹配 关于贪婪和非贪婪,贪婪匹配的意思是,在同一个匹配项中,尽量匹配更多所搜索的字符,非贪婪则相反.正则匹配的默认模式是贪婪模式,当?号跟在如下限制符后面时,使用非贪婪模式(*,+,?,{n},{n,},{n,m})
-
正则表达式教程之匹配一组字符详解
本文实例讲述了正则表达式教程之匹配一组字符的方法.分享给大家供大家参考,具体如下: 注:在所有例子中正则表达式匹配结果包含在源文本中的[和]之间,有的例子会使用Java来实现,如果是java本身正则表达式的用法,会在相应的地方说明.所有java例子都在JDK1.6.0_13下测试通过. 一.匹配多个字符中的某一个 在上一篇<正则表达式教程之匹配单个字符详解>中的一个匹配以na或sa开头的文本文件例子中,使用的正则表达式是.a.\.txt.如果还有一个文件是cal.txt,那么也将会被匹配到.如
-
JS中正则表达式全局匹配模式 /g用法详解
本文章来详细介绍js中正则表达式的全局匹配模式 /g用法,代码如下: var str = "123#abc"; var re = /abc/ig; console.log(re.test(str)); //输出ture console.log(re.test(str)); //输出false console.log(re.test(str)); //输出ture console.log(re.test(str)); //输出false 在创建正则表达式对象时如果使用了"g&q
-
使用正则表达式实现网页爬虫的思路详解
网页爬虫:就是一个程序用于在互联网中获取指定规则的数据. 思路: 1.为模拟网页爬虫,我们可以现在我们的tomcat服务器端部署一个1.html网页.(部署的步骤:在tomcat目录的webapps目录的ROOTS目录下新建一个1.html.使用notepad++进行编辑,编辑内容为: ) 2.使用URL与网页建立联系 3.获取输入流,用于读取网页中的内容 4.建立正则规则,因为这里我们是爬去网页中的邮箱信息,所以建立匹配 邮箱的正则表达式:String regex="\w+@\w+(\.\w+
-
Oracle通过正则表达式分割字符串 REGEXP_SUBSTR的代码详解
REGEXP_SUBSTR函数格式如下: function REGEXP_SUBSTR(string, pattern, position, occurrence, modifier) string :需要进行正则处理的字符串 pattern :进行匹配的正则表达式 position :起始位置,从第几个字符开始正则表达式匹配(默认为1) occurrence :标识第几个匹配组,默认为1 modifier :模式('i'不区分大小写进行检索:'c'区分大小写进行检索.默认为'c') SELEC
-
java正则表达式之Pattern与Matcher类详解
Pattern.split方法详解 /** * 测试Pattern.split方法 */ @Test public void testPatternSplit() { String str = "{0x40, 0x11, 0x00, 0x00}"; // 分割符为:逗号, {,}, 空白符 String regex = "[,\\{\\}\\s]"; Pattern pattern = Pattern.compile(regex); /* * 1. split 方法
-
Python正则表达式re.compile()和re.findall()详解
目录 前言 网页中的代码: 提取的方法: re.findall中参数re.S的意义: 参考: 总结 前言 在使用爬虫提取网页中的部分信息时,采用到了re.compile()与re.findall()两种方法,目的:把网页中的“某某城市土地规划表”截取并打印出来. 网页中的代码: <span class='tab-details'>某某城市土地规划表</span> 提取的方法: def parse_response(html): pattern = re.compile('class
-
正则表达式问号的四种用法详解
原文符号 因为?在正则表达式中有特殊的含义,所以如果想匹配?本身,则需要转义,\? 有无量词 问号可以表示重复前面内容的0次或一次,也就是要么不出现,要么出现一次. 非贪婪匹配 贪婪匹配 在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配 string pattern1 = @"a.*c"; // greedy match Regex regex = new Regex(pattern1); regex.Match("abcabc"); // return