Python pandas索引的设置和修改方法
目录
- 前言
- 创建索引
- pd.Index
- pd.IntervalIndex
- pd.CategoricalIndex
- pd.DatetimeIndex
- pd.PeriodIndex
- pd.TimedeltaIndex
- 读取数据
- set_index
- reset_index
- set_axis
- 操作行索引
- 操作列索引
- rename
- 字典形式
- 函数形式
- 使用案例
- 按日统计总消费
- 按日、性别统计小费均值,消费总和
- 笨方法
- 总结
前言
本文主要是介绍Pandas中行和列索引的4个函数操作:
- set_index
- reset_index
- set_axis
- rename
创建索引
快速回顾下Pandas创建索引的常见方法:
pd.Index
In [1]:
import pandas as pd import numpy as np
In [2]:
# 指定类型和名称
s1 = pd.Index([1,2,3,4,5,6,7],
dtype="int",
name="Peter")
s1
Out[2]:
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64', name='Peter')
pd.IntervalIndex
新的间隔索引 IntervalIndex 通常使用 interval_range()函数来进行构造,它使用的是数据或者数值区间,基本用法:
In [3]:
s2 = pd.interval_range(start=0, end=6, closed="left") s2
Out[3]:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5), [5, 6)],
closed='left',
dtype='interval[int64]')
pd.CategoricalIndex
In [4]:
s3 = pd.CategoricalIndex(
# 待排序的数据
["S","M","L","XS","M","L","S","M","L","XL"],
# 指定分类顺序
categories=["XS","S","M","L","XL"],
# 排需
ordered=True,
# 索引名字
name="category"
)
s3
Out[4]:
CategoricalIndex(['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'], categories=['XS', 'S', 'M', 'L', 'XL'], ordered=True, name='category', dtype='category')
pd.DatetimeIndex
以时间和日期作为索引,通过date_range函数来生成,具体例子为:
In [5]:
# 日期作为索引,D代表天
s4 = pd.date_range("2022-01-01",periods=6, freq="D")
s4
Out[5]:
DatetimeIndex(['2022-01-01', '2022-01-02', '2022-01-03',
'2022-01-04','2022-01-05', '2022-01-06'],
dtype='datetime64[ns]', freq='D')
pd.PeriodIndex
pd.PeriodIndex是一个专门针对周期性数据的索引,方便针对具有一定周期的数据进行处理,具体用法如下:
In [6]:
s5 = pd.PeriodIndex(['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04'], freq = '2H') s5
Out[6]:
PeriodIndex(['2022-01-01 00:00', '2022-01-02 00:00',
'2022-01-03 00:00','2022-01-04 00:00'],
dtype='period[2H]', freq='2H')
pd.TimedeltaIndex
In [7]:
data = pd.timedelta_range(start='1 day', end='3 days', freq='6H') data
Out[7]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
In [8]:
s6 = pd.TimedeltaIndex(data) s6
Out[8]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
读取数据
下面通过一份 简单的数据来讲解4个函数的使用。数据如下:

set_index
设置单层索引
In [10]:
# 设置单层索引
df1 = df.set_index("name")
df1
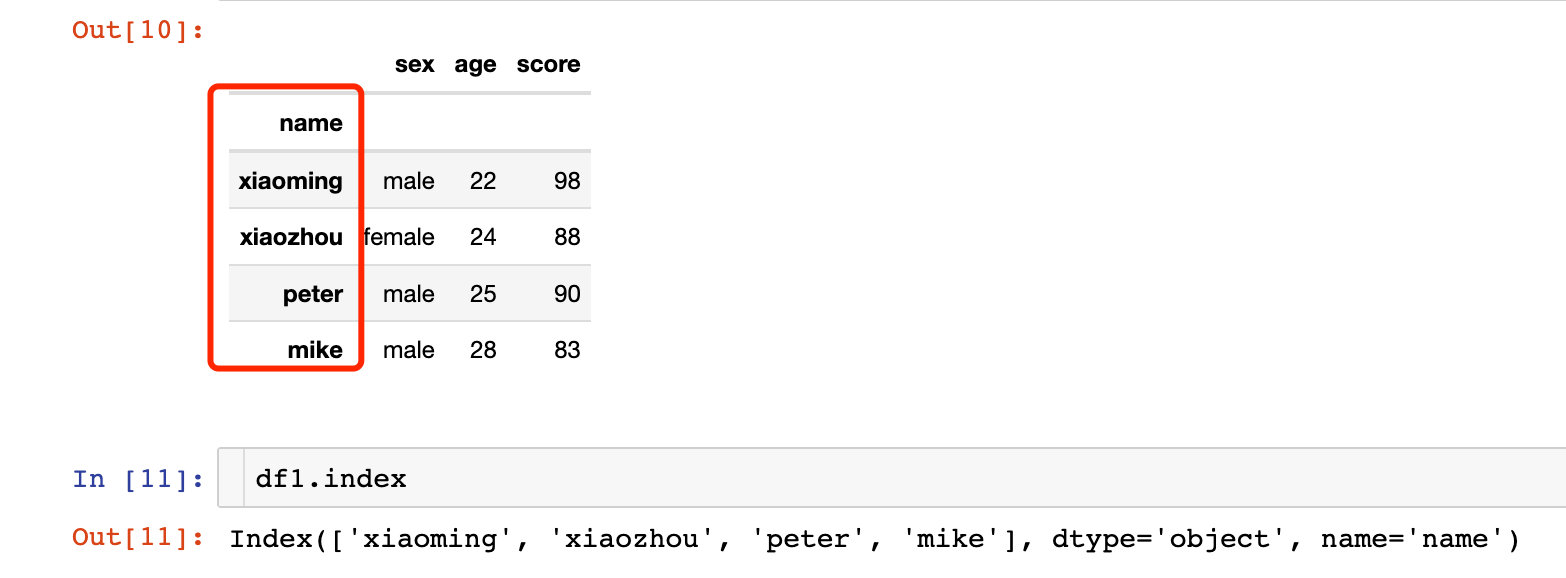
我们发现df1的索引已经变成了name字段的相关值。
下面是设置多层索引:
# 设置两层索引 df2 = df.set_index(["sex","name"]) df2

reset_index
对索引的重置:

针对多层索引的重置:

多层索引直接原地修改:

set_axis
将指定的数据分配给所需要的轴axis。其中axis=0代表行方向,axis=1代表列方向。
两种不同的写法:
axis=0 等价于 axis="index" axis=1 等价于 axis="columns"
操作行索引
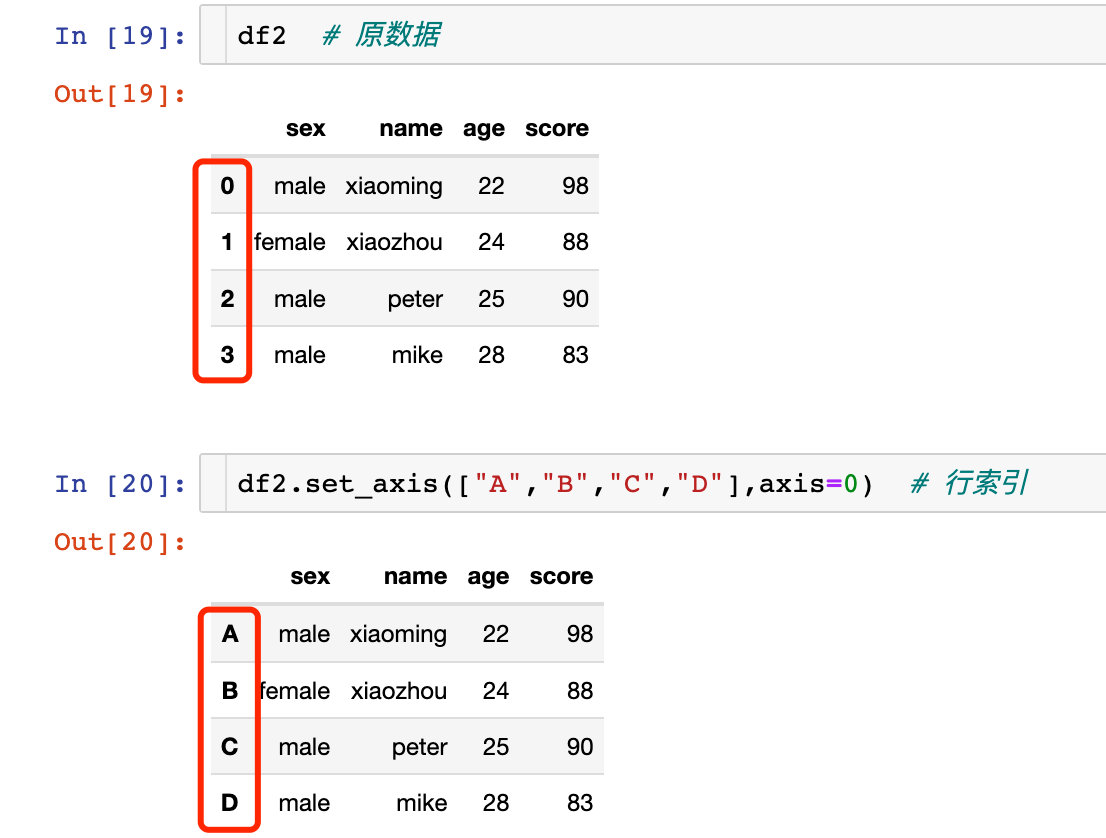
使用 index 效果相同:

原来的df2是没有改变的。如果我们想改变生效,同样也可以直接原地修改:
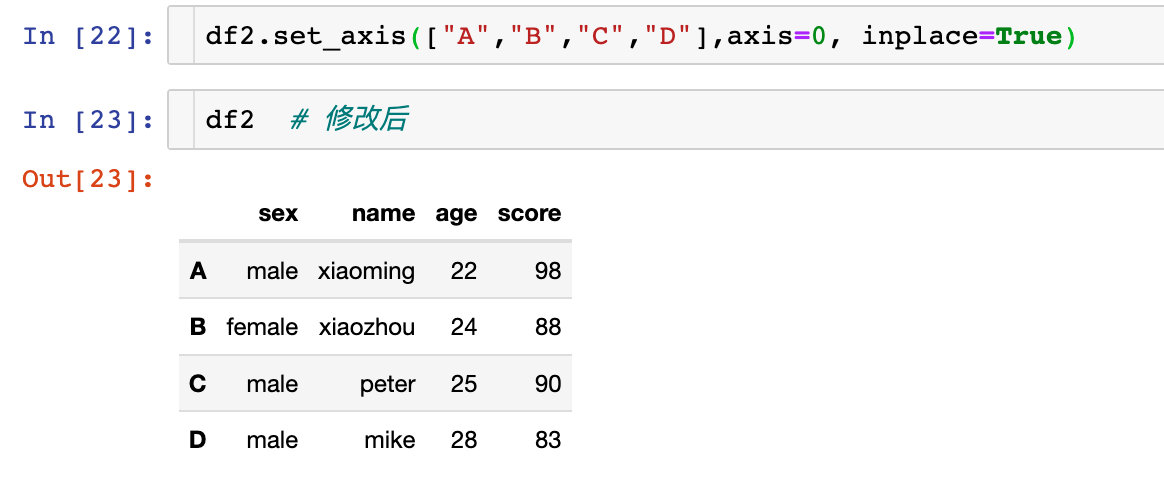
操作列索引
针对axis=1或者axis="columns"方向上的操作。
1、直接传入我们需要修改的新名称:

使用axis="columns"效果相同:
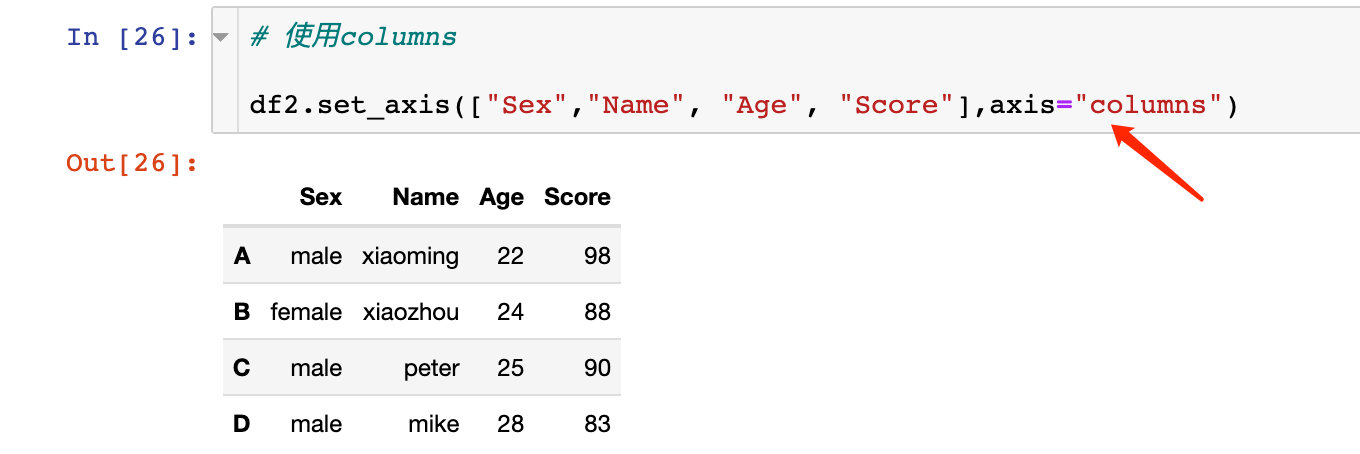
同样也可以直接原地修改:

rename
给行索引或者列索引进行重命名,假设我们的原始数据如下:

字典形式
1、通过传入的一个或者多个属性的字典形式进行修改:
In [29]:
# 修改单个列索引;非原地修改
df2.rename(columns={"Sex":"sex"})

同时修改多个列属性的名称:

函数形式
2、通过传入的函数进行修改:
In [31]:
# 传入函数 df2.rename(str.upper, axis="columns")

也可以使用匿名函数lambda:
# 全部变成小写 df2.rename(lambda x: x.lower(), axis="columns")
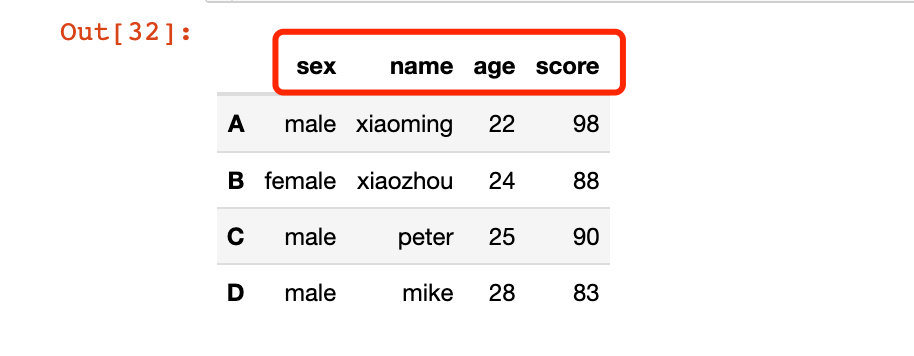
使用案例
In [33]:
在这里我们使用的是可视化库plotly_express库中的自带数据集tips:
import plotly_express as px tips = px.data.tips() tips

按日统计总消费
In [34]:
df3 = tips.groupby("day")["total_bill"].sum()
df3
Out[34]:
day Fri 325.88 Sat 1778.40 Sun 1627.16 Thur 1096.33 Name: total_bill, dtype: float64
In [35]:
我们发现df3其实是一个Series型的数据:
type(df3) # Series型的数据
Out[35]:
pandas.core.series.Series
In [36]:
下面我们通过reset_index函数将其变成了DataFrame数据:
df4 = df3.reset_index() df4

我们把列方向上的索引重新命名下:
In [37]:
# 直接原地修改
df4.rename(columns={"day":"Day", "total_bill":"Amount"},
inplace=True)
df4

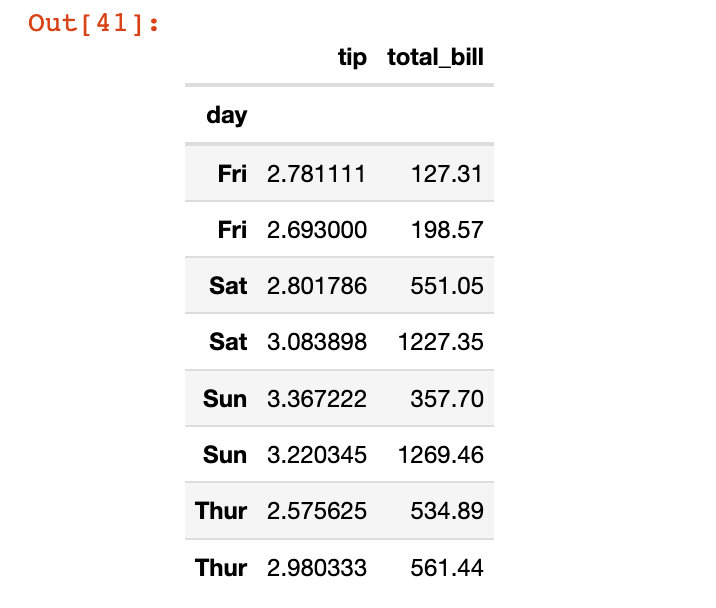
按日、性别统计小费均值,消费总和
In [38]:
df5 = tips.groupby(["day","sex"]).agg({"tip":"mean", "total_bill":"sum"})
df5

我们发现df5是df5是一个具有多层索引的数据框:
In [39]:
type(df5)
Out[39]:
pandas.core.frame.DataFrame
我们可以选择重置其中一个索引:

在重置索引的同时,直接丢弃原来的字段信息:下面的sex信息被删除
In [41]:
df5.reset_index(["sex"],drop=True) # 非原地修改
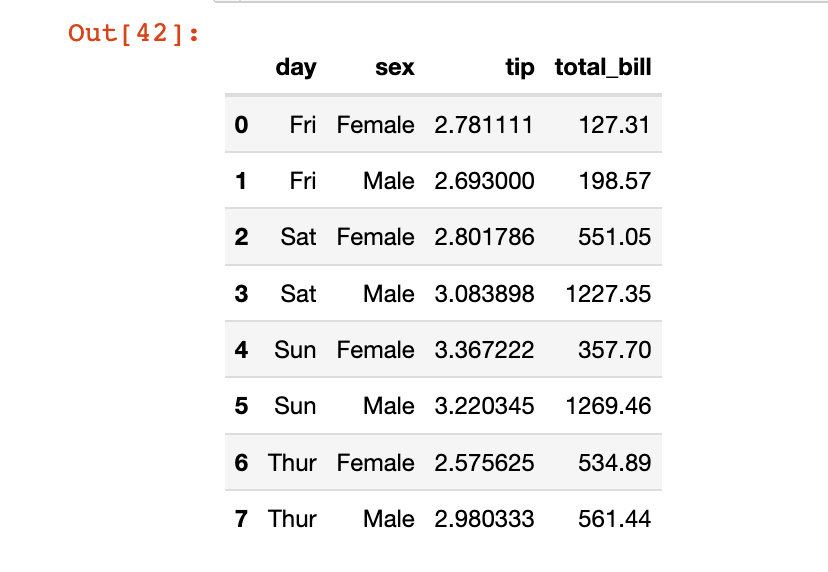
列方向上的索引直接原地修改:
df5.reset_index(inplace=True) # 原地修改 df5
笨方法
最后介绍一个笨方法来修改列索引的名称:就是将新的名称通过列表的形式全部赋值给数据框的columns属性

在列索引个数少的时候用起来挺方便的,如果多了不建议使用。
总结
到此这篇关于Python pandas索引的设置和修改的文章就介绍到这了,更多相关pandas索引设置和修改内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对Pandas MultiIndex(多重索引)详解
创建多重索引 In [16]: df = pd.DataFrame(np.random.randn(3, 8), index=['A', 'B', 'C'], columns=index) In [17]: df Out[17]: first bar baz foo qux \ second one two one two one two one A 0.895717 0.805244 -1.206412 2.565646 1.431256 1.340309 -1.170299 B 0.4108
-
pandas实现选取特定索引的行
如下所示: >>> import numpy as np >>> import pandas as pd >>> index=np.array([2,4,6,8,10]) >>> data=np.array([3,5,7,9,11]) >>> data=pd.DataFrame({'num':data},index=index) >>> print(data) num 2 3 4 5 6 7 8 9
-
pandas带有重复索引操作方法
有的时候,可能会遇到表格中出现重复的索引,在操作重复索引的时候可能要注意一些问题. 一.判断索引是否重复 a.Series索引重复判断 s = Series([1,2,3,4,5],index=["a","a","b","b","c"]) print(s.index.is_unique) #False Series.index.is_unique为False表示索引重复. b.DataFrame索引重复判断
-
pandas通过索引进行排序的示例
如下所示: import pandas as pd df = pd.DataFrame([1, 2, 3, 4, 5], index=[10, 52, 24, 158, 112], columns=['S']) df.sort_index(inplace=True) print df 以上这篇pandas通过索引进行排序的示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-

Python pandas索引的设置和修改方法
目录 前言 创建索引 pd.Index pd.IntervalIndex pd.CategoricalIndex pd.DatetimeIndex pd.PeriodIndex pd.TimedeltaIndex 读取数据 set_index reset_index set_axis 操作行索引 操作列索引 rename 字典形式 函数形式 使用案例 按日统计总消费 按日.性别统计小费均值,消费总和 笨方法 总结 前言 本文主要是介绍Pandas中行和列索引的4个函数操作: set_index
-
Linux部署python爬虫脚本,并设置定时任务的方法
去年因项目需要,用python写了个爬虫.因爬到的数据需要存到生产环境的PG数据库.所以需要将脚本部署到CentOS服务器,并设置定时任务,自动启动脚本. 实施步骤如下: 1.安装pip(操作系统自带了python2.6可以直接用,但是没有pip) # 下载pip安装包 wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=834b2904f92d46aaa333267fb1c922bb" --
-
对python字典元素的添加与修改方法详解
1.字典中的键存在时,可以通过字典名+下标的方式访问字典中改键对应的值,若键不存在则会抛出异常.如果想直接向字典中添加元素可以直接用字典名+下标+值的方式添加字典元素,只写键想后期对键赋值这种方式会抛出异常. >>>a=['apple','banana','pear','orange'] >>> a ['apple', 'banana', 'pear', 'orange'] >>> a={1:'apple',2:'banana',3:'pear',4:
-
Python之列表的插入&替换修改方法
用例子说明 fruit = ['pineapple','grape','pear'] fruit[0:0] = ['Orange'] #在fruit集合中第一位插入字符串'Orange' print(fruit) #['Orange','pineapple','grape','pear'] fruit[0] = 'Grapefruit' #将fruit集合的第一位元素替换为'Grapefruit' print(fruit) #['Grapefruit','pineapple','grape','
-
Python pandas库中isnull函数使用方法
前言: python的pandas库中有⼀个⼗分便利的isnull()函数,它可以⽤来判断缺失值,我们通过⼏个例⼦学习它的使⽤⽅法.⾸先我们创建⼀个dataframe,其中有⼀些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[7,
-
利用Python pandas对Excel进行合并的方法示例
前言 在网上找了很多Python处理Excel的方法和代码,都不是很尽人意,所以自己综合网上各位大佬的方法,自己进行了优化,具体的代码如下. 博主也是新手一枚,代码肯定有很多需要优化的地方,欢迎各位大佬提出建议~ 代码我自己已经用了一段时间,可以直接拿去用 主要功能 按行合并 ,即保留固定的表头(如前几行),实现多个Excel相同格式相同名字的表单按纵轴合并: 按列合并. 即保留固定的首列,实现多个Excel相同格式相同名字的表单按横轴合并: 表单集成 ,实现不同Excel中相同sheet的集成
-
Python中pycharm编辑器界面风格修改方法
教你配置属于自己的PYcharm界面色彩风格,PYthon学习必备 GO 第一步,换成深色背景,保护视力 PyCharm默认的背景是白色的,比较刺眼.还是换成深色的比较好,而且感觉比较酷一点. 修改方法:进入PyCharm,File ==>setting==> Appearance&Behavior ==> Appearance,右侧找到Theme一项,换成Darcula. 第二步,修改字体,换一个更好看的字体 修改方法:进入PyCharm,File ==> setting
-
Python pandas求方差和标准差的方法实例
目录 准备 1.求方差 1.1对全表进行操作 1.1.1求取每列的方差 1.1.2 求取每行的方差 1.2 对单独的一行或者一列进行操作 1.2.1 求取单独某一列的方差 1.2.2 求取单独某一行的方差 1.3 对多行或者多列进行操作 1.3.1 求取多列的方差 1.3.2 求取多行的方差 2 求标准差 2.1对全表进行操作 2.1.1对每一列求标准差 2.1.2 对每一行求标准差 2.2 对单独的一行或者一列进行操作 2.2.1 对某一列求标准差 2.2.2 对某一行求标准差 2.3 对多行
-
使用Python Pandas处理亿级数据的方法
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择.这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据: 硬件环境 CPU:3.5 GHz Intel Core i7 内存:32 GB HDDR 3 1600 MHz 硬盘:3 TB Fusion Drive 数据分析
-
Python Pandas学习之Pandas数据结构详解
目录 1Pandas介绍 2Pandas数据结构 2.1Series 2.2DataFrame 1 Pandas介绍 2008年WesMcKinney开发出的库 专门用于数据挖掘的开源python库 以Numpy为基础,借力Numpy模块在计算方面性能高的优势 基于matplotlib,能够简便的画图 独特的数据结构 Numpy已经能够帮助我们处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas学习的目的在什么地方呢? 增强图表可读性 便捷的数据处理能力 读取文件方便