盘点Python 爬虫中的常见加密算法
目录
- 前言
- 1. 基础常识
- 2. Base64伪加密
- 3. MD5加密
- 4. AES/DES对称加密
- 1.密钥
- 2.填充
- 3.模式
前言
今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征、加密的方式有哪些等等,知道了这些之后对于我们逆向破解这些加密的参数会起到不少的帮助!
相信大家在数据抓取的时候,会碰到很多加密的参数,例如像是"token"、"sign"等等,今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征、加密的方式有哪些等等,知道了这些之后对于我们逆向破解这些加密的参数会起到不少的帮助!
1. 基础常识
首先我们需要明白的是,什么是加密和解密?顾名思义
- 加密(Encryption): 将明文数据变换为密文的过程
- 解密(Decryption): 加密的逆过程,即由密文恢复出原明文的过程。
加密和解密算法的操作通常都是在一组密钥的控制下进行的,分别成为是加密密钥(Encryption Key)和解密密钥(Decryption Key),
如下图所示:

而加密算法当中又分为是对称加密和非对称加密以及散列算法,其中
- 对称加密:即加密与解密时使用的是相同的密钥,例如RC4、AES、DES等加密算法
- 非对称加密:即加密与解密时使用不相同的密钥,例如RSA加密算法等
- 散列算法:又称为是哈希函数。对不同长度的输入消息产生固定的输出,该输出值就是散列值
2. Base64伪加密
Base64严格意义上来说不算做事加密的算法,只是一种编码的方式,它是一种用64个字符,分别是A-Z、a-z、0-9、+、/这64个字符,实现对数据的编码,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。我们使用Python来对任意网址进行Base64的编码操作,代码如下:
import base64
# 想将字符串转编码成base64,要先将字符串转换成二进制数据
url = "www.baidu.com"
bytes_url = url.encode("utf-8")
str_url = base64.b64encode(bytes_url) # 被编码的参数必须是二进制数据
print(str_url)
输出:
b'd3d3LmJhaWR1LmNvbQ=='
那么同样地,我们也可以对其进行解码的操作,代码如下:
url = "d3d3LmJhaWR1LmNvbQ=="
str_url = base64.b64decode(url).decode("utf-8")
print(str_url)
输出:
www.baidu.com
3. MD5加密
MD5是一种被广泛使用的线性散列算法,且加密之后产生的是一个固定长度(32位或者是16位)的数据,由字母和数字组成,大小写统一。其最后加密生成的数据是不可逆的,也就是说不能够轻易地通过加密后的数据还原到原始的字符串,除非是通过暴力破解的方式。
我们在Python当中来实现一下MD5加密:
import hashlib
str = 'this is a md5 demo.'
hl = hashlib.md5()
hl.update(str.encode(encoding='utf-8'))
print('MD5加密前为 :' + str)
print('MD5加密后为 :' + hl.hexdigest())
输出:
MD5加密前为 :this is a md5 demo.
MD5加密后为 :b2caf2a298a9254b38a2e33b75cfbe75
就像上文提到的,针对MD5加密可以通过暴力破解的方式来降低其安全性,因此在实操过程当中,我们会添加盐值(Salt)或者是双重MD5加密等方式来增加其可靠性,代码如下:
# post传入的参数
params = "123456"
# 加密后需拼接的盐值(Salt)
salt = "asdfkjalksdncxvm"
def md5_encrypt():
m = md5()
m.update(params.encode('utf8'))
sign1 = m.hexdigest()
return sign1
def md5_encrypt_with_salt():
m = md5()
m.update((md5_encrypt() + salt).encode('utf8'))
sign2 = m.hexdigest()
return sign2
4. AES/DES对称加密
首先我们来讲DES加密,全称是Data Encryption Standard,即数据加密标准,在对称性加密当中比较常见的一种,也就是加密和解密过程当中使用的密钥是相同的,因此想要破解的话,通过暴力枚举的方式,只要计算的能力足够强还是可以被破解的。
AES的全称是Advanced Encryption Standard,是DES算法的替代者,也是当今最流行的对称加密算法之一。想要弄清楚AES算法,首先就得弄明白三个基本的概念:密钥、填充和模式。
1.密钥
密钥我们之前已经说了很多了,大家可以将其想象成是一把钥匙,既可以用其来进行上锁,可以用其来进行解锁。AES支持三种长度的密钥:128位、192位以及256位。
2.填充
而至于填充这一概念,AES的分组加密的特性我们需要了解,具体如下图所示:
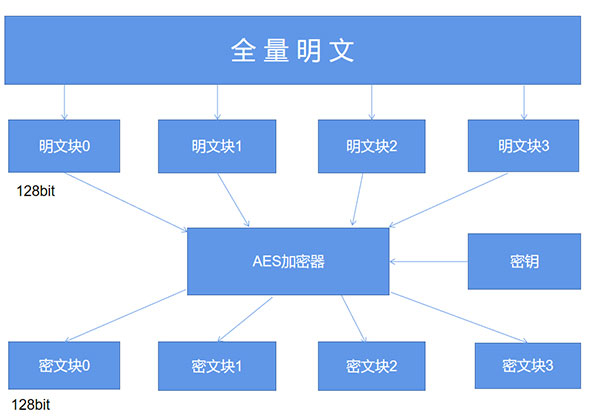
简单来说,AES算法在对明文加密的时候,并不是把整个明文一股脑儿地加密成一整段密文,而是把明文拆分成一个个独立的明文块,每一个明文块的长度为128比特。
这些明文块经过AES加密器的复杂处理之后,生成一个个独立的密文块,将这些密文块拼接到一起就是最终的AES加密的结果了。
那么这里就有一个问题了,要是有一段明文的长度是196比特,如果按照每128比特一个明文块来拆分的话,第二个明文块只有64比特了,不足128比特该怎么办呢?这个时候就轮到填充来发挥作用了,默认的填充方式是PKCS5Padding以及ISO10126Padding。
不过在AES加密的时候使用了某一种填充方式,解密的时候也必须采用同样的填充方式。
3.模式
AES的工作模式,体现在了把明文块加密成密文块的处理过程中,主要有五种不同的工作模式,分别是CBC、ECB、CTR、CFB以及OFB模式,同样地,如果在AES加密过程当中使用了某一种工作模式,解密的时候也必须采用同样地工作模式。最后我们用Python来实现一下AES加密。
import base64
from Crypto.Cipher import AES
def AES_encrypt(text, key):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
text = text.encode("utf-8")
encryptor = AES.new(key.encode('utf-8'), AES.MODE_ECB)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text.decode('utf-8')
到此这篇关于盘点Python 爬虫中的常见加密算法的文章就介绍到这了,更多相关Python 加密算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现ElGamal加密算法的示例代码
在密码学中,ElGamal加密算法是一个基于迪菲-赫尔曼密钥交换的非对称加密算法.它在1985年由塔希尔·盖莫尔提出.GnuPG和PGP等很多密码学系统中都应用到了ElGamal算法. ElGamal加密算法可以定义在任何循环群G上.它的安全性取决于G上的离散对数难题. 使用Python实现ElGamal加密算法,完成加密解密过程,明文使用的是125位数字(1000比特). 代码如下: import random from math import pow a = random.randint(2
-
python3 常见解密加密算法实例分析【base64、MD5等】
本文实例讲述了python3 常见解密加密算法.分享给大家供大家参考,具体如下: 一.使用base64 Base64编码,64指A-Z.a-z.0-9.+和/这64个字符,还有"="号不属于编码字符,而是填充字符. 优点:方法简单 缺点:不保险,别人拿到密文可以自己解密出明文 编码原理:将3个字节转换成4个字节((3 X 8)=24=(4X6)),先读入3个字节,每读一个字节,左移8位,再右移四次,每次6位,这样就有4个字节了. 解码原理:将4个字节转换成3个字节,先读入4个6位(用或
-

python算法加密 pyarmor与docker
目录 前言 一 基础配置 安装 二 基本语法 2.1 加密 Python 脚本 2.2 运行加密脚本 2.3 发布加密脚本 三.pyarmor&docker 3.1 Dockerfile 3.2 requirements.txt 3.3 加密函数lock_by_pyarmor.py 3.4 主函数myprocessor.py 3.5 创建镜像并验证效果 前言 为了避免代码泄露的风险,我们往往需要对代码进行加密,PyArmor 是一个用于加密和保护 Python 脚本的工具.它能够在运行时刻保护
-
Python实现常见的几种加密算法(MD5,SHA-1,HMAC,DES/AES,RSA和ECC)
生活中我们经常会遇到一些加密算法,今天我们就聊聊这些加密算法的Python实现.部分常用的加密方法基本都有对应的Python库,基本不再需要我们用代码实现具体算法. MD5加密 全称:MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致.md5加密算法是不可逆的,所以解密一般都是通过暴力穷举方法,通过网站的接口实现解密.Python代码: i
-
python 中的pycrypto 算法加密
目录 一.安装 二.AES 加密解密 三.SHA加密 四.RSA算法生成密钥对 五.使用密钥对加密解密 六.加签和验签 一.安装 pycryto能实现大致3种类型的数据加密(单向加密.对称加密 和非对称加密),产生随机数,生成密钥对,数字签名 单向加密:Crypto.Hash,其中中包含MD5.SHA1.SHA256等 对称加密:Crypto.Cipher,如常见的DES等 非对称加密:Crypto.Cipher,如常见的AES加密等 随机数操作:Crypto.Random,也可以使用Pytho
-
利用python设计图像加密技术(Arnold算法)
目录 1.加密算法要求 2.Arnold置乱原理 3.python实现 4.结果分析与总结 下面展示了图像的加密和解密过程(左边是输入图像,中间是加密后的结果,右边是解密后的图像): 1.加密算法要求 (1)加密算法必须是可逆的,拥有配套的解密算法 (2)必须是安全的,拦截者不能轻易的破解加密方式 (3)不能造成数据量剧增,比如一个1kb的图像加密后变为100kb 2.Arnold置乱原理 Arnold置乱又称为猫脸置乱,据说是因为Arnold首先对猫脸图像应用了这个算法.置乱的含义是置换和打乱
-
python3中rsa加密算法详情
前言: rsa加密,是一种加密算法,目前而言,加密算法,是对数据.密码等进行加密.第一次接触rsa加密算法是linux中免密登陆设置,当时一直以为密钥加密是像token一样的,直到现在才发现并不是,而是一种数据加密的方式,其实也可以理解,在Linux设计哲学的理解下:“一切皆文件”,就可以把他们当成类似的东西来理解.无非就是拿着a字符串和b字符串进行比较,如果返回trun,那么就可以进行下一步的操作,否则就会被返回异常. 在这里,其实有一个逻辑,就是先把数据进行一次加密,然后进行数据传输,在接收
-
盘点Python加密解密模块hashlib的7种加密算法(推荐)
前言 在程序中我们经常可以看到有很多的加密算法,比如说MD5 sha1等,今天我们就来了解下这下加密算法的吧,在了解之前我们需要知道一个模块嘛就是hashlib,他就是目前Python一个提供字符加密的模块,它加密的字符类型为二进制编码,所以直接加密字符串会报错. import hashlib string='任性的90后boy' #使用encode进行转换 sha1 = hashlib.sha1() sha1.update(string.encode('utf-8')) res = sha1.
-
盘点Python 爬虫中的常见加密算法
目录 前言 1. 基础常识 2. Base64伪加密 3. MD5加密 4. AES/DES对称加密 1.密钥 2.填充 3.模式 前言 今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征.加密的方式有哪些等等,知道了这些之后对于我们逆向破解这些加密的参数会起到不少的帮助! 相信大家在数据抓取的时候,会碰到很多加密的参数,例如像是"token"."sign"等等,今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征.
-
python爬虫中多线程的使用详解
queue介绍 queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue.python3直接queue即可 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性. #多线程实战栗子(糗百) #用一个队列Queue对象, #先产生所有url,put进队列: #开启多线程,把q
-
python爬虫中PhantomJS加载页面的实例方法
PhantomJS作为常用获取页面的工具之一,我们已经讲过页面测试.代码评估和捕获屏幕这几种使用的方式.当然最厉害的还是网页方面的捕捉,这里就不再讲述了.今天我们要讲的是它加载页面的新方法,这个可能很多人不知道.其实经常会用到,感兴趣的小伙伴一起进入今天的学习之中吧~ 可以利用 phantom 来实现页面的加载,下面的例子实现了页面的加载并将页面保存为一张图片. var page = require('webpage').create();page.open('http://cuiqingcai
-
scrapy在python爬虫中搭建出错的解决方法
在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了.一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题.有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点. 问题描述: 安装位置: 环境变量: 解决办法: 文件命名叫 scrapy.py,明显和scrapy自己的包名冲突了,这里 class StackOverFlowSpider(scrapy.Spider) 会直接找当前文件(scrapy.py
-
celery在python爬虫中定时操作实例讲解
使用定时功能对于我们想要快速获取某个数据来说,是一个非常好的方法.这样我们就不用苦苦守在电脑屏幕前,只为蹲到某个想要的东西.在之前我们已经讲过time函数进行定时操作,这算是time函数的比较基础的一个用法了.其实定时功能同样可以用celery实现,具体的方法我们往下看: 爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能.在上述基础上,我们将`tasks.py`文件改成如下内容 from celery impor
-
python爬虫中采集中遇到的问题整理
在爬虫的获取数据上,一直在讲一些爬取的方法,想必小伙伴们也学习了不少.在学习的过程中遇到了问题,大家也会一起交流解决,找出不懂和出错的地方.今天小编想就爬虫采集数据时遇到的问题进行一个整理,以及在遇到不同的问题时,我们应该想的是什么样的解决思路,具体内容如下分享给大家. 1.需要带着cookie信息访问 比如大多数的社交化软件,基本上都是需要用户登录之后,才能看到有价值的东西,其实很简单,我们可以使用Python提供的cookielib模块,实现每次访问都带着源网站给的cookie信息去访问,这
-
python爬虫中url管理器去重操作实例
当我们需要有一批货物需要存放时,最好的方法就是有一个仓库进行保管.我们可以把URL管理器看成一个收集了数据的大仓库,而下载器就是这个仓库货物的搬运者.关于下载器的问题,我们暂且不谈.本篇主要讨论的是在url管理器中,我们遇到重复的数据应该如何识别出来,避免像仓库一样过多的囤积相同的货物.听起来是不是很有意思,下面我们一起进入今天的学习. URL管理器到底应该具有哪些功能? URL下载器应该包含两个仓库,分别存放没有爬取过的链接和已经爬取过的链接. 应该有一些函数负责往上述两个仓库里添加链接 应该
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是
-
python爬虫中抓取指数的实例讲解
有一些数据我们是没法直观的查看的,需要通过抓取去获得.听到指数这个词,有的小伙伴们觉得很复杂,似乎只在股票的时候才听说的,比如一些数据的涨跌分析都是比较棘手的问题.不过指数对于我们的数据分析还是很有帮助的,今天小编就python爬虫中抓取指数得方法给大家带来讲解. 刚好这几天需要用到这个爬虫,结果发现baidu指数的请求有点变化,所以就改了改: import requests import sys import time word_url = 'http://index.baidu.com/ap
-
Python爬虫中Selenium实现文件上传
前言:大部分的文件上传功能都是用input标签实现,这样就完全可以把它看作一个输入框,可以通过send_keys()指定文件进行上传了. 本章中用到的关键方法如下: send_keys():上传文件或者输入文本 from selenium import webdriver import time driver = webdriver.Chrome() driver.get('http://file.yiyuen.com/file/') # 定位上传按钮,添加本地文件 driver.find_el