pandas分批读取大数据集教程
如果你的电脑内存较小那么想在本地做一些事情是很有局限性的(哭丧脸),比如想拿一个kaggle上面的竞赛来练练手,你会发现多数训练数据集都是大几G或者几十G的,自己那小破电脑根本跑不起来。行,你有8000w条样本你牛逼,我就取400w条出来跑跑总行了吧(狡滑脸)。
下图是2015年kaggle上一个CTR预估比赛的数据集:

看到train了吧,原始数据集6个G,特征工程后得多大?那我就取400w出来train。为了节省时间和完整介绍分批读入数据的功能,这里以test数据集为例演示。其实就是使用pandas读取数据集时加入参数chunksize。
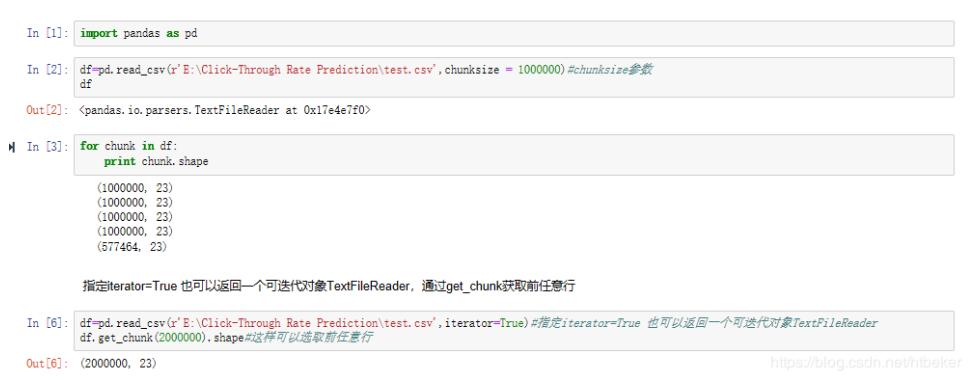
可以通过设置chunksize大小分批读入,也可以设置iterator=True后通过get_chunk选取任意行。
当然将分批读入的数据合并后就是整个数据集了。
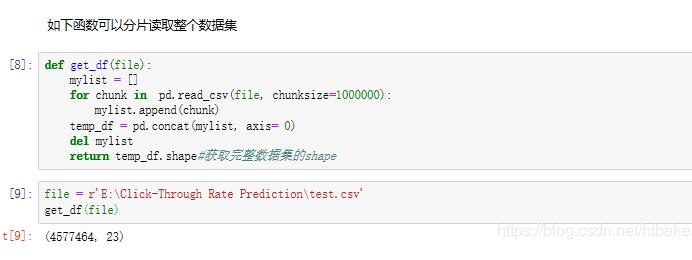
ok了!
补充知识:用Pandas 处理大数据的3种超级方法
易上手, 文档丰富的Pandas 已经成为时下最火的数据处理库。此外,Pandas数据处理能力也一流。
其实无论你使用什么库,大量的数据处理起来往往回遇到新的挑战。
数据处理时,往往会遇到没有足够内存(RAM)这个硬件问题。 企业往往需要能够存够数百, 乃至数千 的GB 数据。
即便你的计算机恰好有足够的内存来存储这些数据, 但是读取数据到硬盘依旧非常耗时。
别担心! Pandas 数据库会帮我们摆脱这种困境。 这篇文章包含3种方法来减少数据大小,并且加快数据读取速度。 我用这些方法,把超过100GB 的数据, 压缩到了64GB 甚至32GB 的内存大小。
快来看看这三个妙招吧。
数据分块
csv 格式是一种易储存, 易更改并且用户易读取的格式。 pandas 有read_csv ()方法来上传数据,存储为CSV 格式。当遇到CSV 文件过大,导致内存不足的问题该怎么办呢?试试强大的pandas 工具吧!我们先把整个文件拆分成小块。这里,我们把拆分的小块称为chunk。
一个chunk 就是我们数据的一个小组。 Chunk 的大小主要依据我们内存的大小,自行决定。
过程如下:
1.读取一块数据。
2.分析数据。
3.保存该块数据的分析结果。
4.重复1-3步骤,直到所有chunk 分析完毕。
5.把所有的chunk 合并在一起。
我们可以通过read_csv()方法Chunksize来完成上述步骤。 Chunksize是指pandas 一次能读取到多少行csv文件。这个当然也是建立在RAM 内存容量的基础上。
假如我们认为数据呈现高斯分布时, 我们可以在一个chunk 上, 进行数据处理和视觉化, 这样会提高准确率。
当数据稍微复杂时, 例如呈现泊松分布时, 我们最好能一块块筛选,然后把每一小块整合在一起。 然后再进行分析。很多时候, 我们往往删除太多的不相关列,或者删除有值行。 我们可以在每个chunk 上,删除不相关数据, 然后再把数据整合在一起,最后再进行数据分析。
代码如下:
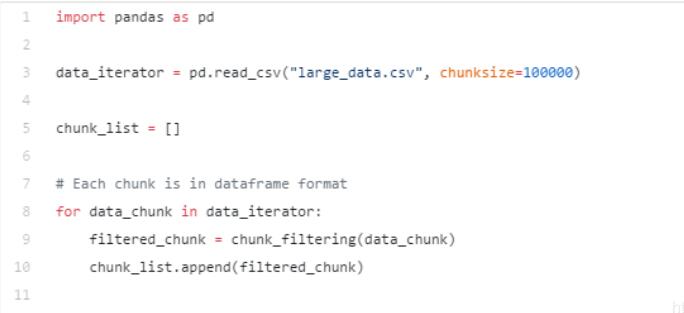
删除数据
有时候, 我们一眼就能看到需要分析的列。事实上, 通常名字,账号等列,我们是不做分析的。
读取数据前, 先跳过这些无用的列,可以帮我们节省很多内存。 Pandas 可以允许我们选择想要读取的列。
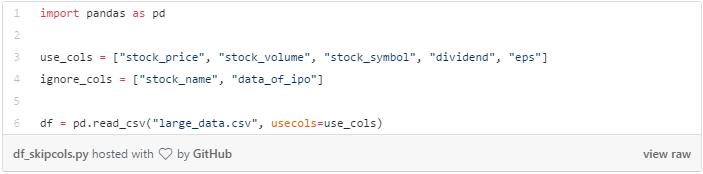
把包含无用信息的列删除掉, 往往给我们节省了大量内存。
此外,我们还可以把有缺失值的行,或者是包含“NA” 的行删除掉。 通过dropna()方法可以实现:
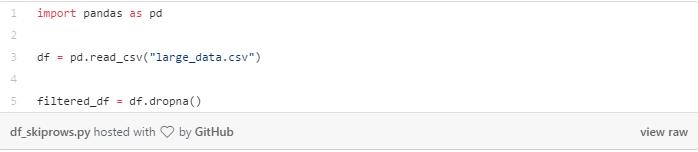
有几个非常有用的参数,可以传给dropna():
how: 可选项:“any”(该行的任意一列如果出现”NA”, 删除该行)
“all” (只有某行所有数数据全部是”NA” 时才删除)
thresh: 设定某行最多包含多少个NA 时,才进行删除
subset: 选定某个子集,进行NA 查找
可以通过这些参数, 尤其是thresh 和 subset 两个参数可以决定某行是否被删除掉。
Pandas 在读取信息的时候,无法删除列。但是我们可以在每个chunk 上,进行上述操作。
为列设定不同的数据类型
数据科学家新手往往不会对数据类型考虑太多。 当处理数据越来越多时, 就非常有必要考虑数据类型了。
行业常用的解决方法是从数据文件中,读取数据, 然后一列列设置数据类型。 但当数据量非常大时, 我们往往担心内存空间不够用。
在CSV 文件中,例如某列是浮点数, 它往往会占据更多的存储空间。 例如, 当我们下载数据来预测股票信息时, 价格往往以32位浮点数形式存储。
但是,我们真的需要32位浮点数码? 大多数情况下, 股票价格以小数点后保留两位数据进行交易。 即便我们想看到更精确的数据, 16位浮点数已经足够了。
我们往往会在读取数据的时候, 设置数据类型,而不是保留数据原类型。 那样的话,会浪费掉部分内存。
通过read_csv() 中设置dtype参数来完成数据类型设置。还可以设置字典类型,设置该列是键, 设置某列是字典的值。
请看下面的pandas 例子:

文章到这里结束了! 希望上述三个方法可以帮你节省时间和内存。
以上这篇pandas分批读取大数据集教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

在Python中利用Pandas库处理大数据的简单介绍
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择.这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据: 硬件环境 CPU:3.5 GHz Intel Core i7 内存:32 GB HDDR 3 1600 MHz 硬
-
详解10个可以快速用Python进行数据分析的小技巧
一些小提示和小技巧可能是非常有用的,特别是在编程领域.有时候使用一点点黑客技术,既可以节省时间,还可能挽救"生命". 一个小小的快捷方式或附加组件有时真是天赐之物,并且可以成为真正的生产力助推器.所以,这里有一些小提示和小技巧,有些可能是新的,但我相信在下一个数据分析项目中会让你非常方便. Pandas中数据框数据的Profiling过程 Profiling(分析器)是一个帮助我们理解数据的过程,而Pandas Profiling是一个Python包,它可以简单快速地对Pandas 的
-
pandas对dataFrame中某一个列的数据进行处理的方法
背景:dataFrame的数据,想对某一个列做逻辑处理,生成新的列,或覆盖原有列的值 下面例子中的df均为pandas.DataFrame()的数据 1.增加新列,或更改某列的值 df["列名"]=值 如果值为固定的一个值,则dataFrame中该列所有值均为这个数据 2.处理某列 df["列名"]=df.apply(lambda x:方法名(x,入参2),axis=1) 说明: 1.方法名为单独的方法名,可以处理传入的x数据 2.x为每一行的数据,做为方法的入参1
-
pandas 使用apply同时处理两列数据的方法
多的不说,看了代码就懂了! df = pd.DataFrame ({'a' : np.random.randn(6), 'b' : ['foo', 'bar'] * 3, 'c' : np.random.randn(6)}) def my_test(a, b): return a + b df['Value'] = df.apply(lambda row: my_test(row['a'], row['c']), axis=1) print df 以上这篇pandas 使用apply同时处理两列
-
pandas分批读取大数据集教程
如果你的电脑内存较小那么想在本地做一些事情是很有局限性的(哭丧脸),比如想拿一个kaggle上面的竞赛来练练手,你会发现多数训练数据集都是大几G或者几十G的,自己那小破电脑根本跑不起来.行,你有8000w条样本你牛逼,我就取400w条出来跑跑总行了吧(狡滑脸). 下图是2015年kaggle上一个CTR预估比赛的数据集: 看到train了吧,原始数据集6个G,特征工程后得多大?那我就取400w出来train.为了节省时间和完整介绍分批读入数据的功能,这里以test数据集为例演示.其实就是使用pa
-
通过Pandas读取大文件的实例
当数据文件过大时,由于计算机内存有限,需要对大文件进行分块读取: import pandas as pd f = open('E:/学习相关/Python/数据样例/用户侧数据/test数据.csv') reader = pd.read_csv(f, sep=',', iterator=True) loop = True chunkSize = 100000 chunks = [] while loop: try: chunk = reader.get_chunk(chunkSize) chun
-
利用pandas读取中文数据集的方法
直接利用numpy读取非数字型的数据集时需要先进行转换,而且python3在处理中文数据方面确实比较蛋疼.最近在学习周志华老师的那本西瓜书,需要没事和一堆西瓜反复较劲,之前进行联系的时候都是利用批量替换先清理一遍数据,不过这样实在是太麻烦了,今天偶然发现可以使用pandas来实现读取中文数据集的功能. 首先分享一下数据集: 编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.7
-
python简单读取大文件的方法
本文实例讲述了python简单读取大文件的方法.分享给大家供大家参考,具体如下: Python读取大文件(GB级别)采用的办法很简单: with open(...) as f: for line in f: <do something with line> 例如: with open(filepath,'r') as infile: for line in infile: print line 一切都交给python解释器处理,读取效率很高,且占用资源少. stackoverflow参考链接:
-
php使用file函数、fseek函数读取大文件效率对比分析
php读取大文件可以使用file函数和fseek函数,但是二者之间效率可能存在差异,本文章向大家介绍php file函数与fseek函数实现大文件读取效率对比分析,需要的朋友可以参考一下. 1. 直接采用file函数来操作 由于 file函数是一次性将所有内容读入内存,而PHP为了防止一些写的比较糟糕的程序占用太多的内存而导致系统内存不足,使服务器出现宕机,所以默认情况下限制只能最大使用内存16M,这是通过php.ini里的 memory_limit = 16M 来进行设置,这个值如果设置-1,
-
C#使用FileStream循环读取大文件数据的方法示例
本文实例讲述了C#使用FileStream循环读取大文件数据的方法.分享给大家供大家参考,具体如下: 今天学习了FileStream的用法,用来读取文件流,教程上都是读取小文件,一次性读取,但是如果遇到大文件,那么我们就需要循环读取文件. 直接上代码. 引用命名空间 using System.IO; 下面就是循环读取大文件的代码 class Program { static void Main(string[] args) { //循环读取大文本文件 FileStream fsRead; //获
-
Java高效读取大文件实例分析
1.概述 本教程将演示如何用Java高效地读取大文件.Java--回归基础. 2.在内存中读取 读取文件行的标准方式是在内存中读取,Guava和ApacheCommonsIO都提供了如下所示快速读取文件行的方法: Files.readLines(new File(path), Charsets.UTF_8); FileUtils.readLines(new File(path)); 这种方法带来的问题是文件的所有行都被存放在内存中,当文件足够大时很快就会导致程序抛出OutOfMemoryErro
-
python pickle存储、读取大数据量列表、字典数据的方法
先给大家介绍下python pickle存储.读取大数据量列表.字典的数据 针对于数据量比较大的列表.字典,可以采用将其加工为数据包来调用,减小文件大小 #列表 #存储 list1 = [123,'xiaopingguo',54,[90,78]] list_file = open('list1.pickle','wb') pickle.dump(list1,list_file) list_file.close() #读取 list_file = open('list1.pickle','rb')
-
简单了解Python读取大文件代码实例
这篇文章主要介绍了简单了解Python读取大文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 通常对于大文件读取及处理,不可能直接加载到内存中,因此进行分批次小量读取及处理 I.第一种读取方式 一行一行的读取,速度较慢 def read_line(path): with open(path, 'r', encoding='utf-8') as fout: line = fout.readline() while line: line
-
Pandas直接读取sql脚本的方法
之前有群友反应同事给了他一个几百MB的sql脚本,导入数据库再从数据库读取数据有点慢,想了解下有没有可以直接读取sql脚本到pandas的方法. 解析sql脚本文本文件替换成csv格式并加载 我考虑了一下sql脚本也就只是一个文本文件而已,而且只有几百MB,现代的机器足以把它一次性全部加载到内存中,使用python来处理也不会太慢. 我简单研究了一下sql脚本的导出格式,并根据格式写出了以下sql脚本的读取方法. 注意:该读取方法只针对SQLyog导出的mysql脚本测试,其他数据库可能代码需要