python:HDF和CSV存储优劣对比分析
小数据用csv,大数据用h5
结论1:几百KB以上的数据都用h5比较好
结论2:几KB的数据h5反而很慢
程序
import pandas as pd
import numpy as np
from wja.wja_tool import test_time as tt
from wja import wja_tool as tool
df = tool.generate_sampleDF(row, col)
tt().run()
df.to_csv('try.csv')
tt().end()
tt().run()
df.to_hdf('try.h5','df',mode='w')
tt().end()
tt().run()
df1 = pd.read_csv('try.csv')
tt().end()
tt().run()
df2 = pd.read_hdf('try.h5')
tt().end()
对比1:数据10*1
df = tool.generate_sampleDF(10,1)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:0.015 程序用时:0.9985 程序用时:0.009 程序用时:0.0369
对比2:数据100*10
df = tool.generate_sampleDF(100,10)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:0.017 程序用时:1.1016 程序用时:0.01 程序用时:0.013
对比3:数据1000*100
df = tool.generate_sampleDF(1000,100)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:0.2383 程序用时:1.0308 程序用时:0.0499 程序用时:0.016
对比4:数据10000*100
df = tool.generate_sampleDF(10000,100)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:2.0895 程序用时:1.0073 程序用时:0.4055 程序用时:0.0169
对比5:数据10000*1000
# csv保存 # hdf保存 # csv读取 # hdf读取 df = tool.generate_sampleDF(10000,1000)

# csv保存 # hdf保存 # csv读取 # hdf读取 程序用时:23.5693 程序用时:2.2057 程序用时:3.3697 程序用时:0.0619
补充知识:python:n个点m条边有权无向图
n个点:有个位置
m条边:两点之间存在m条边有权值
有权:每条边代表一个数值
无向:没有规定行进方向
规定:
1、两点之间的行进路线,最终权值为所经过的边的权值的最大值
2、两点之间走法不止一个,最终取最小值为最终走法
问:
两点之间的最终权值为多少
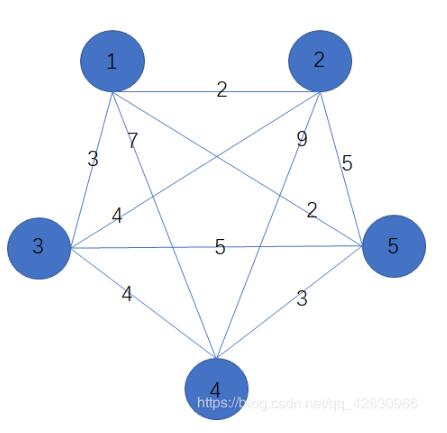
如上图,我们可以将其写为列表形式,前两位是从小到大的的两个点,最后一个代表权值,如
[1, 2, 2] 代表1和2之间的权值是2,以此类推
n,m = 5, 10
road = [[1, 2, 2], [1, 3, 3], [1, 4, 7], [1, 5, 2],
[2, 3, 4], [2, 4, 9], [2, 5, 5], [3, 4, 4],
[3, 5, 5], [4, 5, 3]]
def hold(list1, list2):
jiaoji = list(set(list1)&set(list2))
need = [i for i in set(list1+list2) if i not in jiaoji]
need.sort()
return need
def get(road):
option = {}
for i in range (m):
option[(road[i][0],road[i][1])] = [road[i][2]]
for i in range (m):
for j in range(i+1,m):
dot = hold(road[i][:2], road[j][:2])
if len(dot)==2:
if (dot[0],dot[1]) in option.keys():
option[(dot[0],dot[1])].append(max([road[i][2],road[j][2]]))
else:
option[(dot[0],dot[1])] = []
option[(dot[0],dot[1])].append(max([road[i][2],road[j][2]]))
road_new = []
for i in option.items():
road_new.append(list(i[0])+[min(i[1])])
if road==road_new:
print(road_new)
return road_new
return get(road_new)
输出结果
所有可能的走法如下,并且最后一位输出最短的权值路径。
例如 [2, 3, 3]:代表 从2走到3最短的权值路径是3,对应路径从图中可以到是2-1-3
例如 [3, 5, 3]:代表 从3走到5最短的权值路径是3,对应路径从图中可以到是3-1-5
[[1, 2, 2], [1, 3, 3], [1, 4, 3], [1, 5, 2], [2, 3, 3],
[2, 4, 3], [2, 5, 2], [3, 4, 3], [3, 5, 3], [4, 5, 3]]
以上这篇python:HDF和CSV存储优劣对比分析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python批量处理csv并保存过程解析
需求: 1.大量csv文件,以数字命名,如1.csv.2.cvs等: 2.逐个打开,对csv文件中的某一列进行格式修改: 3.将更改后的内容写入新的csv文件. 解决思路: 先读取需处理的csv文件名,去除文件夹下的无用文件,得到待处理文件地址名称和新文件保存的地址名称,分别读取每一个csv文件进行处理后写入新的文件. if __name__ == '__main__': filenames_in = '../Train_data/' # 输入文件的文件地址 filenames_out = '.
-
python读写csv文件方法详细总结
python提供了大量的库,可以非常方便的进行各种操作,现在把python中实现读写csv文件的方法使用程序的方式呈现出来. 在编写python程序的时候需要csv模块或者pandas模块,其中csv模块使不需要重新下载安装的,pandas模块需要按照对应的 python版本安装. 在python2环境下安装pandas的方式是: sudo pip install pandas 在python3环境下安装pandas的方式是: sudo pip3 install pandas 1.使用csv读写
-
使用pandas库对csv文件进行筛选保存
这个操作现在看来真没啥难的,但是我找相关的资料真的找了好久. 多数大佬都是直接pandas官网甩我脸上,然后举一个入门级的例子. https://pandas.pydata.org/docs/reference/index.html 首先导入pandas库 import pandas as pd 然后使用read_csv来打开指定的csv文件 df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8') 这个函数里面需要写入csv文件的路径,如果
-
pandas.read_csv参数详解(小结)
pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/pandas-docs/stable/io.html 参数: filepath_or_buffer : str,pathlib.str, pathlib.Path, py._path.local.LocalPath or any object with a read() method (such as a file
-
python:HDF和CSV存储优劣对比分析
小数据用csv,大数据用h5 结论1:几百KB以上的数据都用h5比较好 结论2:几KB的数据h5反而很慢 程序 import pandas as pd import numpy as np from wja.wja_tool import test_time as tt from wja import wja_tool as tool df = tool.generate_sampleDF(row, col) tt().run() df.to_csv('try.csv') tt().end()
-

Python取读csv文件做dbscan分析
目录 1.读取csv数据做dbscan分析 2.输出结果显示 3.计算效率 1.读取csv数据做dbscan分析 读取csv文件中相应的列,然后进行转化,处理为本算法需要的格式,然后进行dbscan运算,目前公开的代码也比较多,本文根据公开代码修改, 具体代码如下: from sklearn import datasets import numpy as np import random import matplotlib.pyplot as plt import time import cop
-
golang 定时任务方面time.Sleep和time.Tick的优劣对比分析
golang 写循环执行的定时任务,常见的有以下三种实现方式 1.time.Sleep方法: for { time.Sleep(time.Second) fmt.Println("我在定时执行任务") } 2.time.Tick函数: t1:=time.Tick(3*time.Second) for { select { case <-t1: fmt.Println("t1定时器") } } 3.其中Tick定时任务 也可以先使用time.Ticker函数获取
-
python向量化与for循环耗时对比分析
目录 向量化与for循环耗时对比 向量化数据的相比于for循环的优势 向量化与for循环耗时对比 深度学习中,可采用向量化替代for循环,优化耗时问题 对比例程如下,参考Andrew NG的课程笔记 import time import numpy as np a = np.random.rand(1000000) b = np.random.rand(1000000) tic = time.time() c = np.dot(a,b) toc = time.time() print(c) pr
-
python中in在list和dict中查找效率的对比分析
首先给一个简单的例子,测测list和dict查找的时间: import time query_lst = [-60000,-6000,-600,-60,-6,0,6,60,600,6000,60000] lst = [] dic = {} for i in range(100000000): lst.append(i) dic[i] = 1 start = time.time() for v in query_lst: if v in lst: continue end1 = time.time
-
Python读取csv文件做K-means分析详情
目录 1.运行环境及数据 2.基于时间序列的分析2D 2.1 2000行数据结果展示 2.2 6950行数据结果展示 2.3 300M,约105万行数据结果展示 3.经纬度高程三维坐标分类显示3D-空间点聚类 3.1 2000行数据结果显示 3.2 300M的CSV数据计算显示效果 1.运行环境及数据 Python3.7.PyCharm Community Edition 2021.1.1,win10系统. 使用的库:matplotlib.numpy.sklearn.pandas等 数据:CSV
-
python中lambda与def用法对比实例分析
本文实例对比分析了python中lambda与def的用法.分享给大家供大家参考.具体分析如下: 1.lambda用来创建匿名函数,不同于def(def创建的函数都是有名字的). 2.lambda不会将结果赋给一个标识符,而def会将函数结果赋给一个标识符. 3.lambda是一个表达式,而def是一个语句 示例程序: >>> f1 = lambda x,y,z: x*2+y+z # lambda带有多个参数 >>> print f1(3,2,1) 9 >>
-
Python判断值是否在list或set中的性能对比分析
本文实例对比分析了Python判断值是否在list或set中的执行性能.分享给大家供大家参考,具体如下: 判断值是否在set集合中的速度明显要比list快的多, 因为查找set用到了hash,时间在O(1)级别. 假设listA有100w个元素,setA=set(listA)即setA为listA转换之后的集合. 以下做个简单的对比: for i in xrange(0, 5000000): if i in listA: pass for i in xrange(0, 5000000): if
-
Python自动化运维_文件内容差异对比分析
模块:difflib 安装:Python版本大于等于2.3系统自带 功能:对比文本之间的差异,而且支持输出可读性比较强的HTML文档,与Linux中的diff命令比较相似. 两个字符串的差异对比: #import difflib #text1=''' #hello world. #how are you. #nice to meet you. #''' #text1_lines=text1.splitlines() # 以行进行分割,便于进行对比 #text2=''' #Hello World.
-
Go/Python/Erlang编程语言对比分析及示例代码
本文主要是介绍Go,从语言对比分析的角度切入.之所以选择与Python.Erlang对比,是因为做为高级语言,它们语言特性上有较大的相似性,不过最主要的原因是这几个我比较熟悉. Go的很多语言特性借鉴与它的三个祖先:C,Pascal和CSP.Go的语法.数据类型.控制流等继承于C,Go的包.面对对象等思想来源于Pascal分支,而Go最大的语言特色,基于管道通信的协程并发模型,则借鉴于CSP分支. Go/Python/Erlang语言特性对比 如<编程语言与范式>一文所说,不管语言如何层出不穷