Python实现抓取城市的PM2.5浓度和排名
主机环境:(Python2.7.9 / Win8_64 / bs4)
利用BeautifulSoup4来抓取 www.pm25.com 上的PM2.5数据,之所以抓取这个网站,是因为上面有城市PM2.5浓度排名(其实真正的原因是,它是百度搜PM2.5出来的第一个网站!)
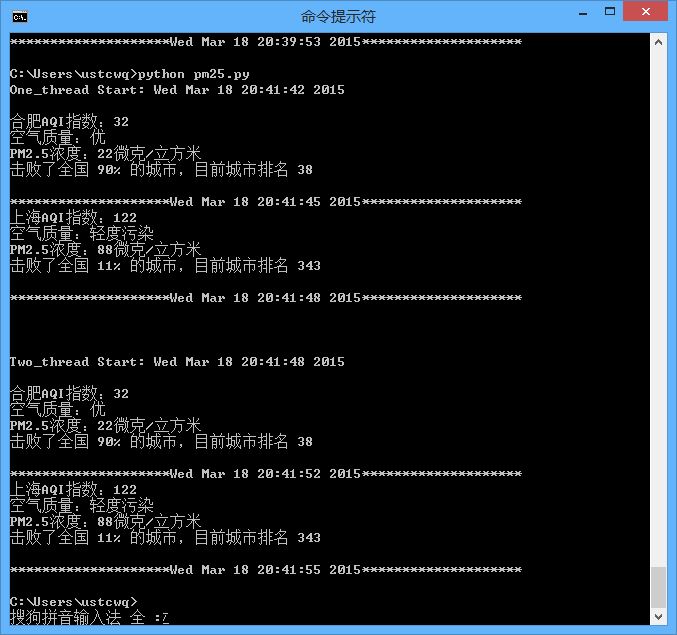
程序里只对比了两个城市,所以多线程的速度提升并不是很明显,大家可以弄10个城市并开10个线程试试。
最后吐槽一下:上海的空气质量怎么这么差!!!
PM25.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# by ustcwq
import urllib2
import threading
from time import ctime
from bs4 import BeautifulSoup
def getPM25(cityname):
site = 'http://www.pm25.com/' + cityname + '.html'
html = urllib2.urlopen(site)
soup = BeautifulSoup(html)
city = soup.find(class_ = 'bi_loaction_city') # 城市名称
aqi = soup.find("a",{"class","bi_aqiarea_num"}) # AQI指数
quality = soup.select(".bi_aqiarea_right span") # 空气质量等级
result = soup.find("div",class_ ='bi_aqiarea_bottom') # 空气质量描述
print city.text + u'AQI指数:' + aqi.text + u'\n空气质量:' + quality[0].text + result.text
print '*'*20 + ctime() + '*'*20
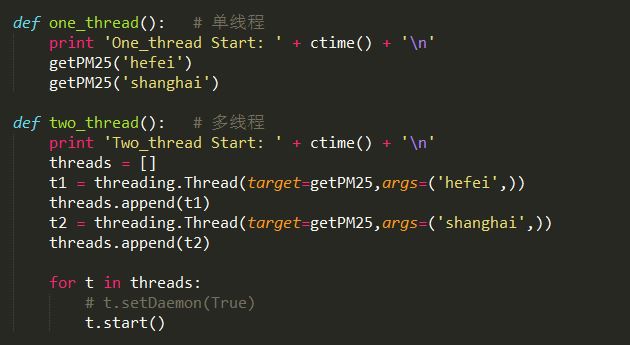
def one_thread(): # 单线程
print 'One_thread Start: ' + ctime() + '\n'
getPM25('hefei')
getPM25('shanghai')
def two_thread(): # 多线程
print 'Two_thread Start: ' + ctime() + '\n'
threads = []
t1 = threading.Thread(target=getPM25,args=('hefei',))
threads.append(t1)
t2 = threading.Thread(target=getPM25,args=('shanghai',))
threads.append(t2)
for t in threads:
# t.setDaemon(True)
t.start()
if __name__ == '__main__':
one_thread()
print '\n' * 2
two_thread()
以上就是本文所述的全部内容了,希望大家能够喜欢。
相关推荐
-
简单的抓取淘宝图片的Python爬虫
写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品. 从网页http://mm.taobao.com/json/request_top_list.htm?type=0&page=中提取taobao模特的照片. 复制代码 代码如下: # -*- coding: cp936 -*- import urllib2 import urllib mmurl="http://mm.taobao.com/json/request_top_list.htm?type
-
python抓取最新博客内容并生成Rss
osc的rss不是全文输出的,不开心,所以就有了python抓取osc最新博客生成Rss # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import urllib2 import datetime import time import PyRSS2Gen from email.Utils import formatdate import re import sys import os reload(sys) sys.setdefaul
-
python抓取百度首页的方法
本文实例讲述了python抓取百度首页的方法.分享给大家供大家参考.具体实现方法如下: import urllib def downURL(url,filename): try: fp=urllib.urlopen(url) except: print('download error') return 0 op=open(filename,'wb') while 1: s=fp.read() if not s: break op.write(s) fp.close() op.close() re
-
Python实现登录人人网并抓取新鲜事的方法
本文实例讲述了Python实现登录人人网并抓取新鲜事的方法.分享给大家供大家参考.具体如下: 这里演示了Python登录人人网并抓取新鲜事的方法(抓取后的排版不太美观~~) from sgmllib import SGMLParser import sys,urllib2,urllib,cookielib class spider(SGMLParser): def __init__(self,email,password): SGMLParser.__init__(self) self.h3=F
-
python实现爬取千万淘宝商品的方法
本文实例讲述了python实现爬取千万淘宝商品的方法.分享给大家供大家参考.具体实现方法如下: import time import leveldb from urllib.parse import quote_plus import re import json import itertools import sys import requests from queue import Queue from threading import Thread URL_BASE = 'http://s
-

用Python程序抓取网页的HTML信息的一个小实例
抓取网页数据的思路有好多种,一般有:直接代码请求http.模拟浏览器请求数据(通常需要登录验证).控制浏览器实现数据抓取等.这篇不考虑复杂情况,放一个读取简单网页数据的小例子: 目标数据 将ittf网站上这个页面上所有这些选手的超链接保存下来. 数据请求 真的很喜欢符合人类思维的库,比如requests,如果是要直接拿网页文本,一句话搞定: doc = requests.get(url).text 解析html获得数据 以beautifulsoup为例,包含获取标签.链接,以及根据html层次结
-
Python实现抓取百度搜索结果页的网站标题信息
比如,你想采集标题中包含"58同城"的SERP结果,并过滤包含有"北京"或"厦门"等结果数据. 该Python脚本主要是实现以上功能. 其中,使用BeautifulSoup来解析HTML,可以参考我的另外一篇文章:Windows8下安装BeautifulSoup 代码如下: 复制代码 代码如下: __author__ = '曾是土木人' # -*- coding: utf-8 -*- #采集SERP搜索结果标题 import urllib2 fr
-
Python使用淘宝API查询IP归属地功能分享
网上有很多方法能够过去到IP地址归属地的脚本,但是我发现淘宝IP地址库的信息更详细些,所以用shell写个脚本来处理日常工作中一些IP地址分析工作. 脚本首先是从http://ip.taobao.com/的数据接口获取IP地址的JSON格式的数据信息,在使用一个python脚本来把Unicode字符转换成UTF-8编码. Shell脚本内容: 复制代码 代码如下: #!/bin/bash ipInfo() { for i in `cat list` do TransCoding=
-
使用Python程序抓取新浪在国内的所有IP的教程
数据分析,特别是网站分析中需要对访问者的IP进行分析,分析IP中主要是区分来访者的省份+城市+行政区数据,考虑到目前纯真IP数据库并没有把这些数据做很好的区分,于是寻找了另外一个可行的方案(当然不是花钱买哈).解决方案就是抓取新浪的IP数据. 新浪的IP数据接口为: http://int.dpool.sina.com.cn/iplookup/iplookup.php?format=json&ip=123.124.2.85 返回的数据为: 复制代码 代码如下: {"ret"
-
Python实现抓取城市的PM2.5浓度和排名
主机环境:(Python2.7.9 / Win8_64 / bs4) 利用BeautifulSoup4来抓取 www.pm25.com 上的PM2.5数据,之所以抓取这个网站,是因为上面有城市PM2.5浓度排名(其实真正的原因是,它是百度搜PM2.5出来的第一个网站!) 程序里只对比了两个城市,所以多线程的速度提升并不是很明显,大家可以弄10个城市并开10个线程试试. 最后吐槽一下:上海的空气质量怎么这么差!!! PM25.py 复制代码 代码如下: #!/usr/bin/env python
-
Python正则抓取网易新闻的方法示例
本文实例讲述了Python正则抓取网易新闻的方法.分享给大家供大家参考,具体如下: 自己写了些关于抓取网易新闻的爬虫,发现其网页源代码与网页的评论根本就对不上,所以,采用了抓包工具得到了其评论的隐藏地址(每个浏览器都有自己的抓包工具,都可以用来分析网站) 如果仔细观察的话就会发现,有一个特殊的,那么这个就是自己想要的了 然后打开链接就可以找到相关的评论内容了.(下图为第一页内容) 接下来就是代码了(也照着大神的改改写写了). #coding=utf-8 import urllib2 import
-
Python正则抓取新闻标题和链接的方法示例
本文实例讲述了Python正则抓取新闻标题和链接的方法.分享给大家供大家参考,具体如下: #-*-coding:utf-8-*- import re from urllib import urlretrieve from urllib import urlopen #获取网页信息 doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站 #抓取新闻标题和链接 def extract_title(info):
-
python访问抓取网页常用命令总结
python访问抓取网页常用命令 简单的抓取网页: import urllib.request url="http://google.cn/" response=urllib.request.urlopen(url) #返回文件对象 page=response.read() 直接将URL保存为本地文件: import urllib.request url="http://google.cn/" response=urllib.request.urlopen(url)
-
Python实现抓取网页生成Excel文件的方法示例
本文实例讲述了Python实现抓取网页生成Excel文件的方法.分享给大家供大家参考,具体如下: Python抓网页,主要用到了PyQuery,这个跟jQuery用法一样,超级给力 示例代码如下: #-*- encoding:utf-8 -*- import sys import locale import string import traceback import datetime import urllib2 from pyquery import PyQuery as pq # 确定运行
-
Python实现抓取网页并且解析的实例
本文以实例形式讲述了Python实现抓取网页并解析的功能.主要解析问答与百度的首页.分享给大家供大家参考之用. 主要功能代码如下: #!/usr/bin/python #coding=utf-8 import sys import re import urllib2 from urllib import urlencode from urllib import quote import time maxline = 2000 wenda = re.compile("href=\"htt
-
python数据抓取分析的示例代码(python + mongodb)
本文介绍了Python数据抓取分析,分享给大家,具体如下: 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: headers = { ..... } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式
-
Python如何抓取天猫商品详细信息及交易记录
本文实例为大家分享了Python抓取天猫商品详细信息及交易记录的具体代码,供大家参考,具体内容如下 一.搭建Python环境 本帖使用的是Python 2.7 涉及到的模块:spynner, scrapy, bs4, pymmssql 二.要获取的天猫数据 三.数据抓取流程 四.源代码 #coding:utf-8 import spynner from scrapy.selector import Selector from bs4 import BeautifulSoup import ran
-
Python爬虫抓取代理IP并检验可用性的实例
经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太频繁了,所以被封IP了. 但是,还是可以去IP巴士试试的,条条大路通罗马嘛,不能吊死在一棵树上. 不废话,上代码. #!/usr/bin/env python # -*- coding:utf8 -*- import urllib2 import time
-
Python实现抓取HTML网页并以PDF文件形式保存的方法
本文实例讲述了Python实现抓取HTML网页并以PDF文件形式保存的方法.分享给大家供大家参考,具体如下: 一.前言 今天介绍将HTML网页抓取下来,然后以PDF保存,废话不多说直接进入教程. 今天的例子以廖雪峰老师的Python教程网站为例:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000 二.准备工作 1. PyPDF2的安装使用(用来合并PDF): PyPDF2版本:1.2