C语言各种符号的使用介绍下篇
目录
- 1、按位运算符
- 1.1 按位或( | )和按位与( & )
- 1.2 按位异或( ^ )
- 1.3 一个关于整型提升的问题
- 2、移位操作符
- 2.1 左移<< 右移>>操作符
- 2.2 习题练习
- 3、++和--的操作
- 3.1 基本操作
- 3.2 从汇编角度深入理解a++
1、按位运算符
1.1 按位或( | )和按位与( & )
上期我们讲到过逻辑或和逻辑与,他们得到的结果是真假值,但我们一定要区分清楚,按位运算符 "|" 和 "&" 与逻辑运算符 "||" "&&" 是完全两个概念。
按位,简明之意,按数值二进制位来进行运算,都是在数据补码的基础上进行。
按位或 "|" :两个数值的二进制补码对应位进行运算,对应位有 1 则为 1 ,否则为 0。
按位与 "&":两个数值的二进制补码对应位进行运算,对应位都为 1 则为 1, 否则为 0。
这里我们举例说明:
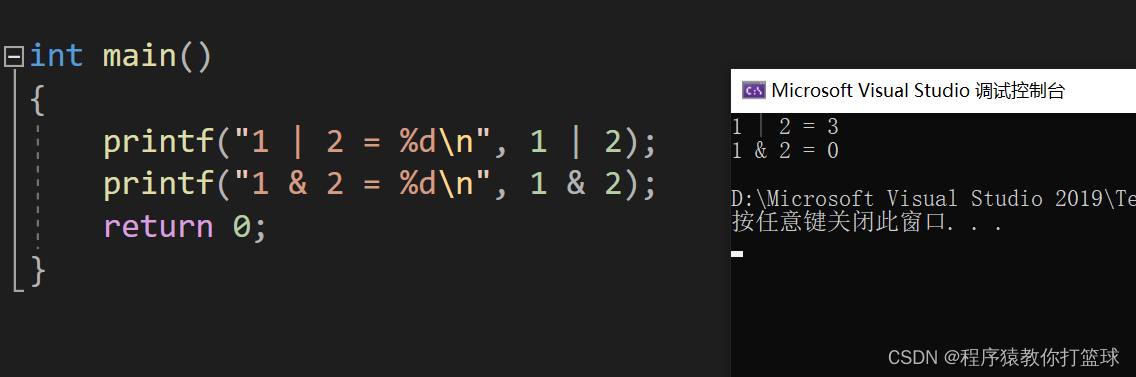
1 | 2 :
1 的二进制补码:0000 0000 ... 0000 0001
2 的二进制补码:0000 0000 ... 0000 0010
------按位或结果: 0000 0000... 0000 0011 -> 对应十进制:3
1 & 2:
1 的二进制补码:0000 0000 ... 0000 0001
2 的二进制补码:0000 0000 ... 0000 0010
------按位与结果: 0000 0000... 0000 0000 -> 对应十进制:0
其实有很多大学老师或者是书上都有可能把按位或,按位与,以及后面我们要讲的按位异或,他们会把每位二进制运算后的结果称为真或者假,其实这样的说法是不够严谨的,真假是逻辑判断,而按位运算得到的结果是数值,而且在C语言中0表示假,非0为真,所以我是不推荐这种说法。
1.2 按位异或( ^ )
按位或 "^" :两个数值的二进制补码对应位进行运算,相同为 0 , 不同为 1。
这里我们举例说明:
1 ^3:
1 的二进制补码:0000 0000 ... 0000 0001
3 的二进制补码:0000 0000 ... 0000 0011
---按位异或结果: 0000 0000... 0000 0010 -> 对应十进制:2
5 ^0:
5 的二进制补码:0000 0000 ... 0000 0101
0 的二进制补码:0000 0000 ... 0000 0000
---按位异或结果: 0000 0000... 0000 0101 -> 对应十进制:5
结论:任何数异或0都等于它本身
这里有一道笔试题:不创建临时变量,实现两个数的交换。
//很多小伙伴直接想出来的做法:
int main()
{
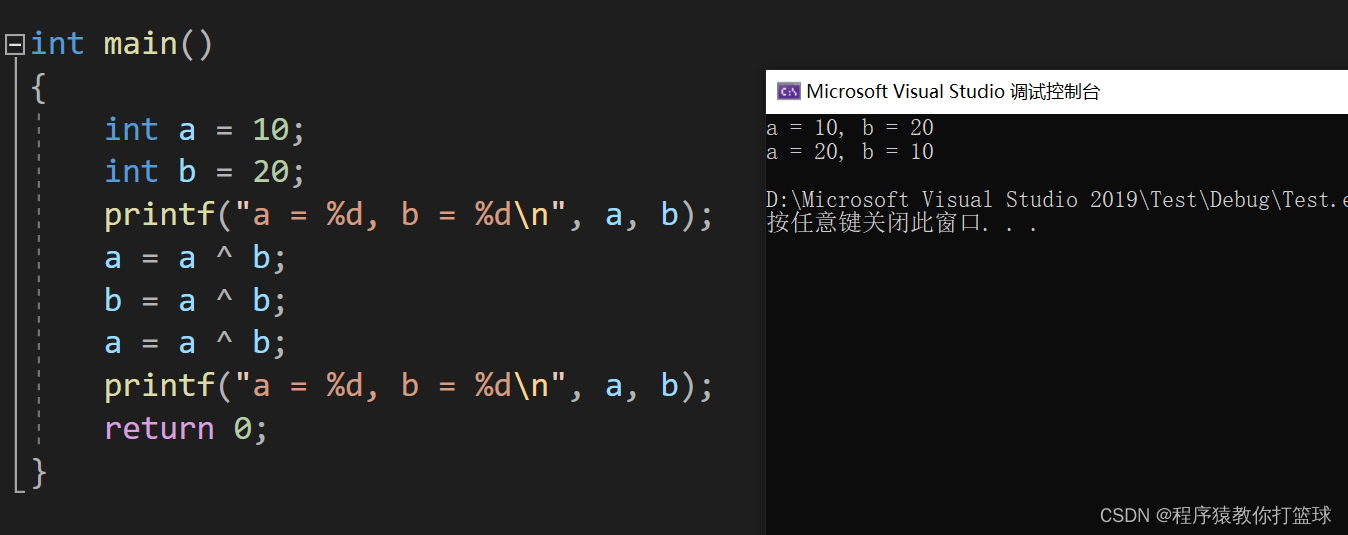
int a = 10;
int b = 20;
printf("a = %d, b = %d\n", a, b);
a = a + b;
b = a - b;
a = a - b;
printf("a = %d, b = %d\n", a, b);
return 0;
}
但是我们仔细研究下这段代码,他有没有什么隐藏的问题呢?
一个整型,占四个字节,也就是 32 个比特位,这里进行加法运算,就会产生进位,万一我们是两个很大的数相加呢?他们的和超过了整型最大存储范围,那么在计算机里面就会发生截断!为了避免发生这种现象,我们可以采取异或的方法来实现这道题:
最后还有一个很简单的按位取反操作符:~
用途:对一个数的二进制按位取反(包括它的符号位)
注意:以上的位运算符,他们的操作数必须是整数!
1.3 一个关于整型提升的问题
有这样一串代码,问:为什么一个char类型大小可以求出来是4字节?
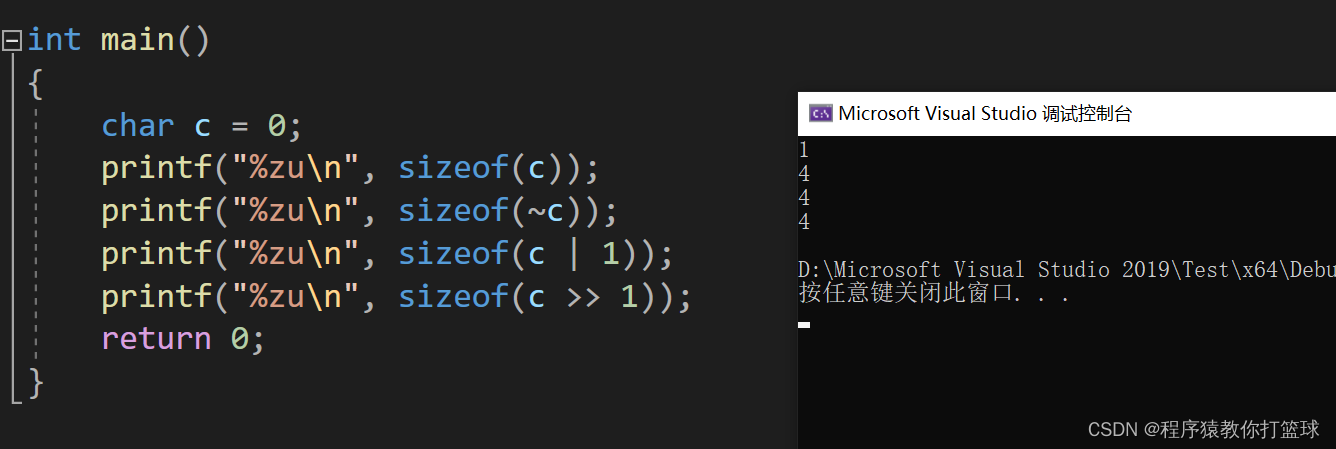
无论任何位运算符,都是要计算机进行计算的,而计算机中CPU具有运算能力,但计算的数据都是放在内存中的。所以,做任何运算,都必须将数据从内存拿到CPU的寄存器中。而寄存器默认的操作数宽度是32位,可是,char类型数据只有1个字节,也就是8位,不满足32位怎么办,这就需要整型提升了!(详细整型提升大家可以查阅资料哦)
如果是一个有符号数的话:高位补符号位
如果是一个无符号数的话:高位补0
2、移位操作符
2.1 左移<< 右移>>操作符
<< 左移运算符是一个双目运算符,功能是把左边的运算数的各个二进制位向左移动指定位数。
>> 右移运算符是一个双目运算符,功能是把右边的运算数的各个二进制位向右移动指定位数。
注意:
<< 左移:最低位丢弃,最高位补零
>> 右移:
- 无符号数:最低位丢弃,最高位补零 [逻辑右移]
- 有符号数:最低位丢弃,最高位补符号位 [算数右移]
以上在补码中进行运算
警告:移位运算符,请不要移动负数位,这是标准未定义的!
左移我们好说,主要是右移我们需要细讲一下:
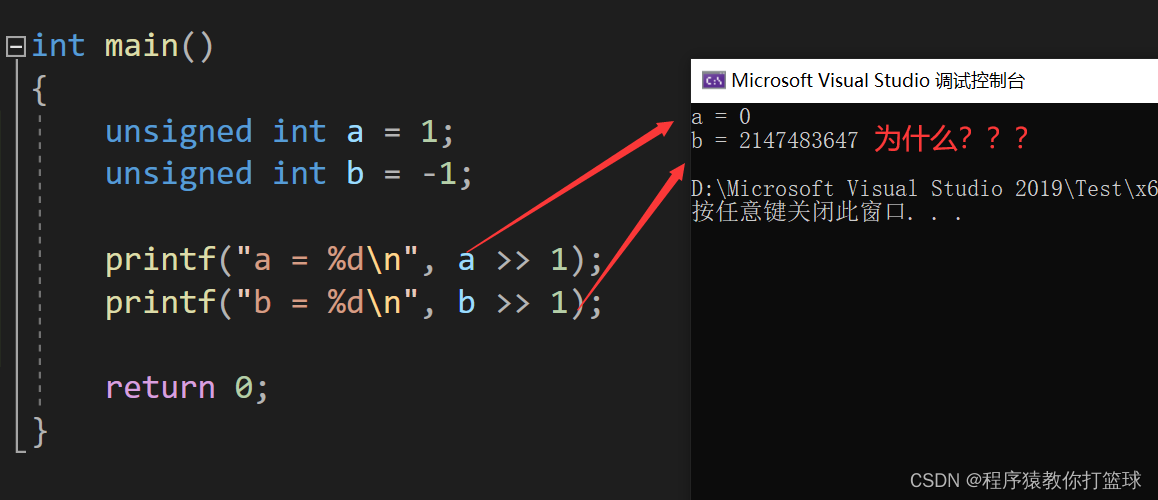
明显看到,这是在无符号数下进行右移,第一个小伙伴都不会感到惊讶, 可是第二个就有点不理解了,我们来解释下:
这里有一个问题,当 -1 准备放入变量 b 的时候我们需要看-1的类型吗?
答案是不需要!内存中放的都是二进制补码,本质上是把 -1 的补码放入变量 b 当中,第二,右移操作符属于计算,需要在CPU中进行,所以需要先把内存中 -1 的补码拿到CPU寄存器中运算,按照我们的规则,右移中,无符号数低位丢弃高位补零,所以 -1 右移完成之后就变成了 0111 1111 ... 1111 1111,接着我们以 %d 有符号整型打印,就会把他当作有符号数看待,最高位是 0 所以被认为是正数,转化成十进制也就是如上打印的值。
第二个我们来看下有符号数右移:
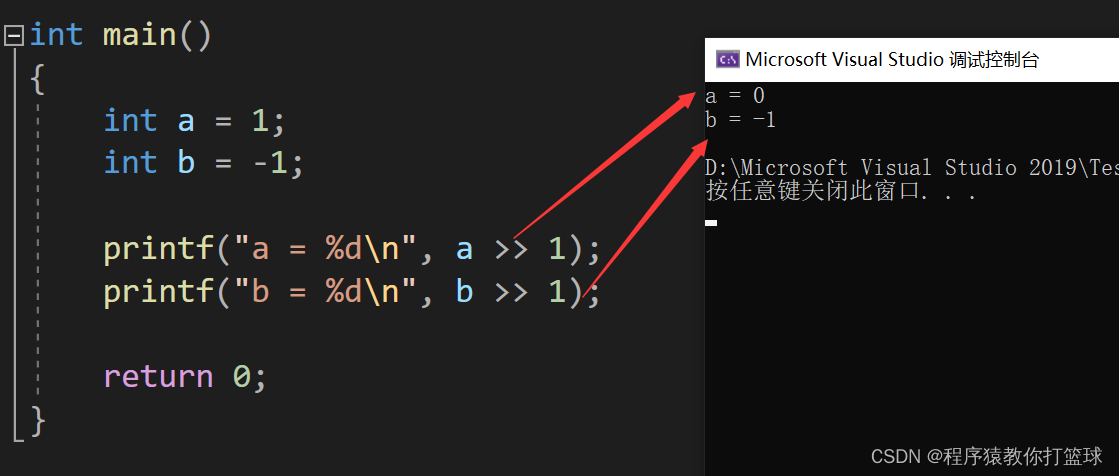
这个相信大家就很好理解了,第一个高位补符号位也就是补 0,低位丢弃,所以结果是 0,第二个高位补符号位也就是补 1,低位丢弃,值仍然不变,还是 -1。
注意:a>>1 并不会改变 a 变量的值,就好比如 a + 1。这样写才会改变:a = a >> 1;
2.2 习题练习
学完了上期的逻辑操作符,和本期的移位操作符,我们来练练手:
请你设计一个宏可以指定数据第几个比特位更改为 1 ,并设计一个函数将各个比特位打印出来。
//参考
#define SETBIT(a, num) ((a) |= (1 << (num - 1)) )
void PrintBit(int a)
{
int num = 31;
while (num >= 0)
{
if ((a & (1 << num)))
printf("1");
else
printf("0");
--num;
}
printf("\n");
}
int main()
{
int a = 0;
SETBIT(a, 5);
PrintBit(a);
return 0;
}
3、++和--的操作
3.1 基本操作
其实这节知识点理解起来是很简单的,只不过总有些学校喜欢出一些很拉跨的题目:
int i = 3; 问:(++i) + (++i) + (++i) 的值是多少?
我的建议是,看到这类题,直接空着,你也可以在下面添一句,“ 你礼貌吗?”
这种表达式,在任何编译器下算出来的结果是不一样的!
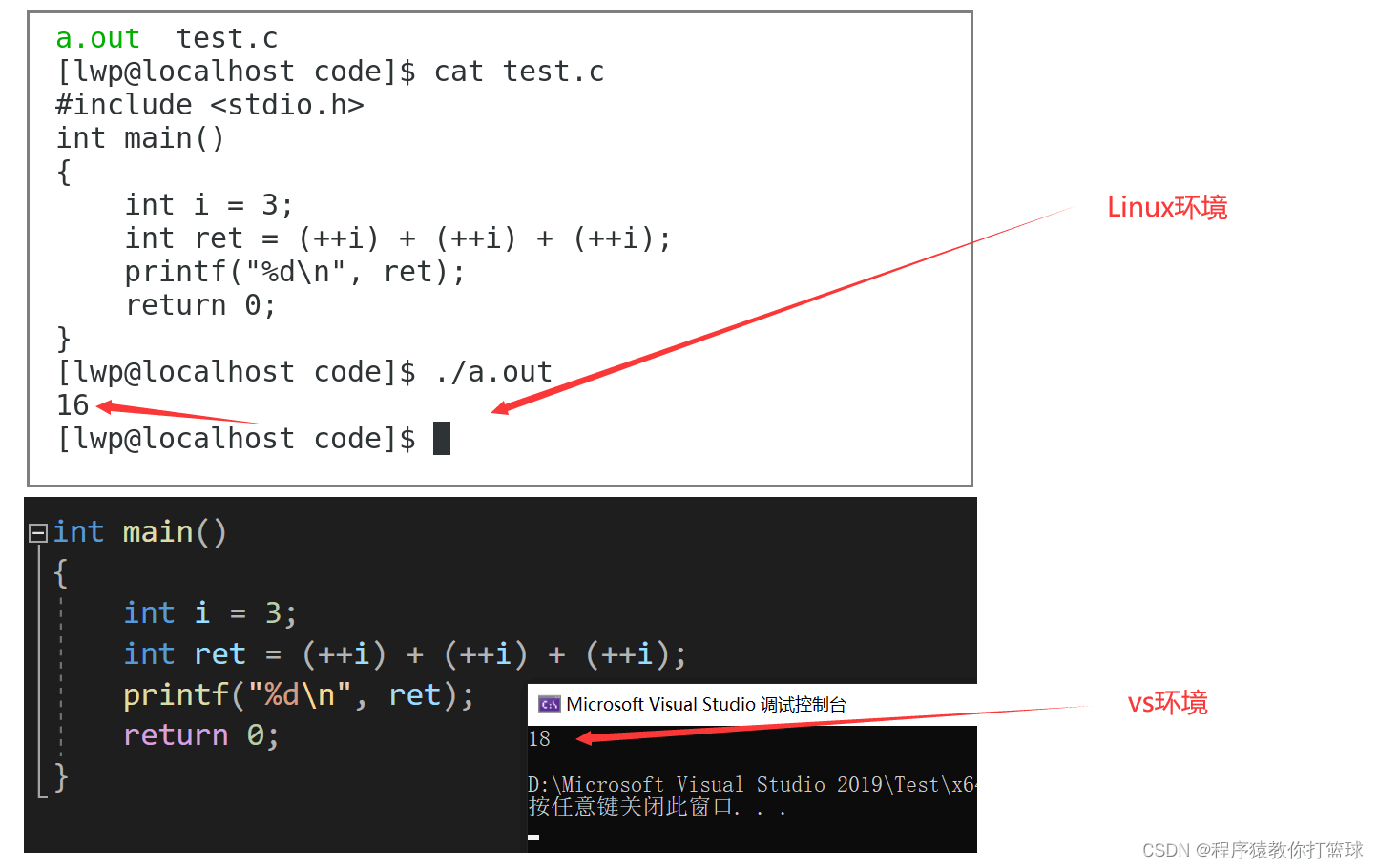
对于这种问题没必要去争论谁对谁错, 如果有人想跟你杠的话,那么你直接告诉他,你真的超级高水平。
好了,言归正传,我们来说一下 ++ 和 -- 的基本理解:
- 前置++ -- :先自增(减),再使用
- 后置++ -- : 先使用,再自增(减) 如果没有变量接收,那么直接自增。
例子:
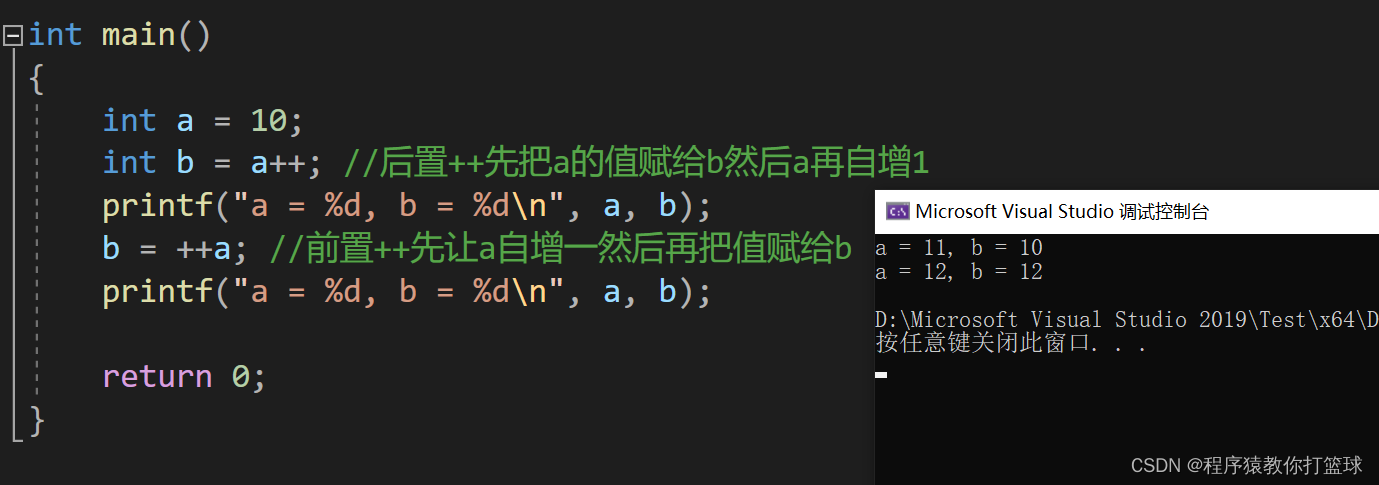
基本使用就是这么多,接下来我们从汇编角度来深度理解一下:
3.2 从汇编角度深入理解a++
既然我们知道,后置++ 是先使用后++,如果我们单纯的就 ++ 一下呢,他这个值被使用到了哪里去了呢?
int main()
{
int a = 0xDD;
int b = a++; //有b接收,那么a的先使用是将a的值(内容),放到b中
int c = 0xEE;
c++; //没有接收方,那么"先使用",如何理解?
return 0;
}
vs2019编译器反汇编:
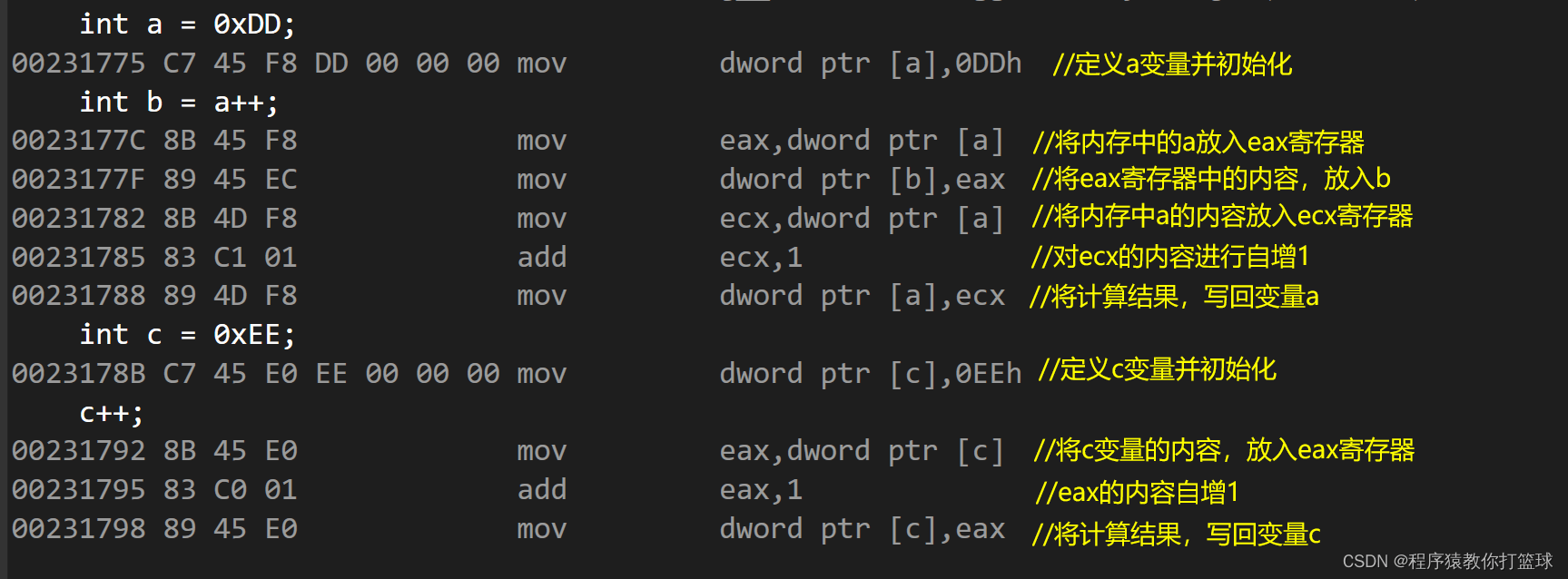
结论:后置++ 完整的含义是先使用,在自增,如果没有变量接收,那么直接自增。
注意:在不同的编译器可能处理过程不同,不过这是一个基本的研究过程,比单纯的理论学习更严谨。
到此这篇关于C语言各种符号的使用介绍下篇的文章就介绍到这了,更多相关C语言符号内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言中无符号数和有符号数之间的运算
C语言中有符号数和无符号数进行运算(包括逻辑运算和算术运算)默认会将有符号数看成无符号数进行运算,其中算术运算默认返回无符号数,逻辑运算当然是返回0或1了. unsigned int和int进行运算 直接看例子来说明问题吧 #include <iostream> using namespace std; int main() { int a = -1; unsigned int b = 16; if(a > b) cout<<"负数竟然大于正数了!\n";
-
C语言详细讲解注释符号的使用
目录 一.注释规则 二.注释中一个有趣的问题 三.教科书型注释 四.迷惑型的注释 五.忽悠型注释 六.搞笑型注释 七.漂亮的程序注释 八.小结 一.注释规则 编译器在编译过程中使用空格替换整个注释 字符串字面量中的 // 和 /*...*/ 不代表注释符号 /*......*/ 型注释不能被嵌套 下面看一下这样一段代码: #include <stdio.h> int main() { int/*...*/i; char* s = "abcdefgh //hijklmn";
-
详解C语言中的符号常量、变量与算术表达式
C语言中的符号常量 在结束讨论温度转换程序前,我们再来看一下符号常量.在程序中使用 300.20 等类似的"幻数"并不是一个好习惯,它们几乎无法向以后阅读该程序的人提供什么信息,而且使程序的修改变得更加困难.处理这种幻数的一种方法是赋予它们有意义的名字.#define 指令可以把符号名(或称为符号常量)定义为一个特定的字符串: #define 名字 替换文本 在该定义之后,程序中出现的所有在 #define 中定义的名字(既没有用引号引起来,也不是其它名字的一部分)都将用相应的替换文本
-
C语言中无符号与有符号及相加问题
C语言中无符号与有符号问题 unsigned char a[5] = { 12,36,96,128,182 }; a[]范围为0~256. 数组中数都有效. char a[5] = { 12,36,96,128,182 }; a[]范围为-128~127. 数组中128和182均无效. C语言中无符号数和有符号数相加问题 看个题: #include<stdio.h> int main() { unsigned int a=6; int b=-20; printf("%d\n"
-
举例讲解C语言链接器的符号解析机制
1. 符号分类 (1)全局符号:非静态全局变量,非静态函数 (2)外部符号:定义于其它模块,而被本模块引用的全局变量和函数 (3)本地符号:静态变量(包括全局和局部),静态函数 对于静态局部变量,编译器会为其生成唯一的名字.如x.fun1,x.fun2.本地符号对链接器来说是不可见的. 2. 符号决议 当编译器遇到一个不是本模块定义的符号时,会假设该函数由其它模块定义,并生成一个链接器符号表条目,交由链接器处理.如果链接器在它的任何输入模块都没有找到该符号,会给出一个类似undefined re
-
C语言特殊符号的补充理解
续接符 反斜杠"",他有两种最常见的功能,一就是续航功能,二就是我们提到反斜杠就会很敏感的转义字符. if("1==a&&2==b&&3==c) { printf("hello\n"); } 有以上的代码我们可以等价于 if("1==a&&\ 2==b&&\ 3==c) { printf("hello\n"); } 这里反斜线就起到了一个连接上下两行的代码,在咱看
-
C语言中弱符号与弱引用的实际应用
最近在学习<程序员的自我修养--链接.装载与库>时,get到了一个新的知识点:弱符号与弱引用.书中简短的介绍,让我了解到弱符号的含义以及使用方式.了解我的朋友,应该知道我喜欢将知识点与我们实际工作结合起来,在工作中利用起来,正所谓学以善用.根据我的理解,觉得利用弱符号的特性可以帮组我们在工作中编写出更加稳定,可复用,可组合的优秀代码.在此向大家分享. 符号重定义错误 在编码过程中,我们经常遇到符号重定义的错误.编译器会报如下错误: multiple definition of `xxx'; 这
-
C语言详细解析有符号数与无符号数的表示
目录 一.计算机中的符号位 二.有符号数的表示法 三.无符号数的表示法 四.signed 和 unsigned 五.小结 一.计算机中的符号位 数据类型的最高位用于标识数据的符号 最高位为1,表明这个数为负数 最高位为0,表明这个数为正数 下面看一段代码,用于判断数据的符号: #include <stdio.h> int main() { char c = -5; short s = 6; int i = -7; printf("%d\n", ( (c & 0x80
-
C语言各种符号的使用介绍上篇
目录 1.注释符号 1.1 注释的基本注意事项 1.2 如何写出好的注释 2.接续符和转移符 2.1 续行功能 2.2 转义字符 3.单引号和双引号 3.1 基本概念 3.2 特殊情况 4.逻辑操作符 4.1 && (逻辑与) 4.2 || (逻辑或) 4.3 逻辑与和逻辑或的笔试题 1.注释符号 1.1 注释的基本注意事项 为了更好的演示我们下面的代码会在 Linux 平台下演示( \ 为续行符): 这段代码,哪一行是有问题的呢? 这里可能有小伙伴就有疑问了,为什么只有这一行出了问题呢?
-
C语言各种符号的使用介绍下篇
目录 1.按位运算符 1.1 按位或( | )和按位与( & ) 1.2 按位异或( ^ ) 1.3 一个关于整型提升的问题 2.移位操作符 2.1 左移<< 右移>>操作符 2.2 习题练习 3.++和--的操作 3.1 基本操作 3.2 从汇编角度深入理解a++ 1.按位运算符 1.1 按位或( | )和按位与( & ) 上期我们讲到过逻辑或和逻辑与,他们得到的结果是真假值,但我们一定要区分清楚,按位运算符 "|" 和 "&
-
C语言零基础彻底掌握预处理下篇
目录 1.条件编译 1.1 条件编译如何使用 1.2 用 #if 模拟 #ifdef 1.3 为何要有条件编译 2.文件包含 2.1 #include 究竟干了什么 2.2 防止头文件重复包含的条件编译是如何做到的 3.选学内容 3.1 #error 预处理 3.2 #line 预处理 3.3 #pragma 预处理 3.3.1 #pragma message 3.3.2 #pragma once 3.3.3 #pragma warning 3.3.4 #pragma pack 3.4 # 和
-
C语言超详细文件操作基础下篇
目录 一.文件的顺序读写 1.格式化的输出函数(fprintf) 2.格式化的输入函数(fscanf) 3.二进制读写 1.二进制输出函数(fwrite) 2.二进制输入函数 3.scanf,fscanf,sscanf.printf,fprintf,sprintf的区别 二.文件的随机读写 1.fseek函数 2.ftell函数 3.rewind函数 三.被错误使用的feof 总结 一.文件的顺序读写 兄弟们,上一章只介绍到了如何把单个的字符或者字符串如何写到文件里或者从文件中读取,文件的顺序读
-
C语言由浅入深讲解文件的操作下篇
目录 文件的顺序读写 字符输入输出fgetc和fputc 文本行输入输出函数fgets和fputs 格式化输入输出函数fscanf和fprintf 二进制输入输出函数fread和fwrite 文件的随机读写 fseek ftell fwind 文本文件和二进制文件 文件结束的判定 feof 文件缓冲区 第一篇讲了文件的基本概念,和文件如何打开和关闭.第二篇主要介绍文件的顺序读写和随机读写.外加文件缓冲区的知识点. 文件的顺序读写 字符输入输出fgetc和fputc fgetc:字符输入函数,也就
-
C语言设计模式之命令模式介绍
目录 介绍: 传统方式: 命令模式: 总结 介绍: 命令模式是一种行为模式,它可以使代码解耦,便于维护: 假设我们现在要设计一个命令解析的模块: 传统方式: void func1(void) { printf("func1\r\n"); } void func2(void) { printf("func2\r\n"); } void func3(void) { printf("func3\r\n"); } void prase_cmd(cha
-
C语言二叉树的遍历示例介绍
在本算法中先利用先序遍历创建了树,利用了递归的算法使得算法简单,操作容易,本来无printf("%c的左/右子树:", ch);的语句,但由于计算机需要输入空格字符来判断左右子树,为了减少人为输入的失误,特地加入这条语句,以此保证准确率. #include<stdio.h> #include<stdlib.h> #define OK 1 #define ERROR 0 #define OVERFLOW 3 typedef int Status; typedef
-
C语言之循环语句详细介绍
目录 前言 while语句 do...while语句 for语句 结语 前言 C语言中的循环结构是程序中的一个基本结构. 循环结构可以使我们写很少的语句,让计算机反复执行某一过程. C语言提供了while语句,do......while语句和for语句,可以组成各种不同形式的循环结构. while语句 while语句又称当型循环控制语句 while(表达式) 语句 表达式式循环条件 ,语句是循环体 当表达式的值为真(非0)时,执行循环体语句,否则终止循环.其特点是先判断,再执行. 例如:计算1+
-
C语言实现二叉树层次遍历介绍
目录 什么是层次遍历? 那我们如何来实现这个算法呢? 主体代码: 总结 什么是层次遍历? 对于一颗二叉树来说,从根节点开始,按从上到下.从左到右的顺序访问每一个结点. 注:每一个结点有且访问一次. 那我们如何来实现这个算法呢? 实现原理: 对于二叉树来说,它是一个递归的定义,我们要实现层次遍历必然要满足从上到下.从左到右这个要求,从根结点出发,我们可以将所有意义上的根结点都存储在队列之中,那我们可以使用队列先进先出的特点来实现要求的遍历. 这里我们需要引用队列来实现. 主体代码: BiTree
-
C语言对冒泡排序进行升级介绍
目录 一.补充一下关于void*指针的知识,易于我们对下列函数实现的理解 二.实现排序函数中的核心,比较函数 三.实现排序函数 四.转换函数的实现 总结 简单的冒牌排序只能对一中数组的类型进行排序,现在我们用冒泡排序为基础来改造出一个可以对任意数组排序的排序函数! 后面附有实现的源码! 首先我们以qsort函数为例慢慢分析,然后确定我们的排序函数如何增强,第一步我们从它的参数下手,它一共4个参数. 1.第一个参数类型是void*,qsort函数可以用来对任意类型的数组排序,用void *型指针可