Golang并发编程之main goroutine的创建与调度详解
目录
- 0. 简介
- 1. 创建main goroutine
- 2. 调度main goroutine
0. 简介
上一篇博客我们分析了调度器的初始化,这篇博客我们正式进入main函数及为其创建的goroutine的过程分析。
1. 创建main goroutine
接上文,在runtime/asm_amd64.s文件的runtime·rt0_go中,在执行完runtime.schedinit函数进行调度器的初始化后,就开始创建main goroutine了。
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry // mainPC是runtime.main
PUSHQ AX // 将runtime.main函数地址入栈,作为参数
CALL runtime·newproc(SB) // 创建main goroutine,入参就是runtime.main
POPQ AX
以上代码创建了一个新的协程(在Go中,go func()之类的相当于调用runtime.newproc),这个协程就是main goroutine,那我们就看看runtime·newproc函数做了什么。
// Create a new g running fn.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
func newproc(fn *funcval) {
gp := getg() // 获取正在运行的g,初始化时是m0.g0
pc := getcallerpc() // 返回的是调用newproc函数时由call指令压栈的函数的返回地址,即上面汇编语言的第5行`POPQ AX`这条指令的地址
systemstack(func() { // systemstack函数的作用是切换到系统栈来执行其参数函数,也就是`g0`栈,这里当然就是m0.g0,所以基本不需要做什么
newg := newproc1(fn, gp, pc)
_p_ := getg().m.p.ptr()
runqput(_p_, newg, true)
if mainStarted {
wakep()
}
})
}
所以以上代码的重点就是调用newproc1函数进行协程的创建。
// Create a new g in state _Grunnable, starting at fn. callerpc is the
// address of the go statement that created this. The caller is responsible
// for adding the new g to the scheduler.
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
_g_ := getg() // _g_ = g0,即m0.g0
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
acquirem() // disable preemption because it can be holding p in a local var
_p_ := _g_.m.p.ptr()
newg := gfget(_p_) // 从本地的已经废弃的g列表中获取一个g先,此时才刚初始化,所以肯定返回nil
if newg == nil {
newg = malg(_StackMin) // new一个g的结构体对象,然后在堆上分配2k的栈大小,并设置stack和stackguard0/1
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
// 调整栈顶指针
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
...
}
上述代码从堆上分配了一个g的结构体,并且在堆上为其分配了一个2k大小的栈,并设置了好了newg的stack等相关参数。此时,newg的状态如图所示:
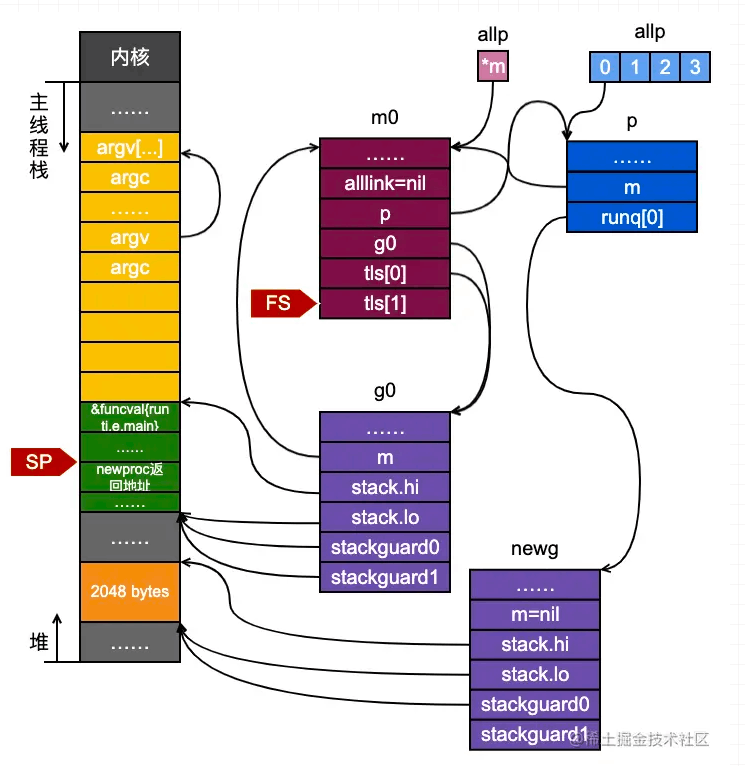
接着我们继续分析newproc1函数:
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp // 设置newg的栈顶
newg.stktopsp = sp
// newg.sched.pc表示当newg运行起来时的运行起始位置,下面一段是类似于代码注入,就好像每个go func()
// 函数都是由goexit函数引起的一样,以便后面当newg结束后,
// 完成newg的回收(当然这里main goroutine结束后进程就结束了,不会被回收)。
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn) // 调整sched成员和newg的栈
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
} else {
// Only user goroutines inherit pprof labels.
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
}
以上代码对newg的sched成员进行初始化,其中newg.sched.sp表示其被调度起来后应该使用的栈顶,newg.sched.pc表示其被调度起来从这个地址开始运行,但是这个值被设置成了goexit函数的下一条指令,所以我们看看,在gostartcallfn函数中,到底做了什么才能实现此功能:
// adjust Gobuf as if it executed a call to fn
// and then stopped before the first instruction in fn.
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn)
} else {
fn = unsafe.Pointer(abi.FuncPCABIInternal(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
// sys_x86.go
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then stopped before the first instruction in fn.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp
sp -= goarch.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc // 插入goexit的第二条指令,返回时可以调用
buf.sp = sp
buf.pc = uintptr(fn) // 此时才是真正地设置pc
buf.ctxt = ctxt
}
以上操作的目的就是:
- 调整
newg的栈空间,把goexit函数的第二条指令的地址入栈,伪造成goexit函数调用了fn,从而使fn执行完成后执行ret指令时返回到goexit继续执行完成最后的清理工作; - 重新设置newg.buf.pc 为需要执行的函数的地址,即fn,此场景为runtime.main函数的地址。
接下来会设置newg的状态为runnable;最后别忘了newproc函数中还有几行:
newg := newproc1(fn, gp, pc)
_p_ := getg().m.p.ptr()
runqput(_p_, newg, true)
if mainStarted {
wakep()
}
在创建完newg后,将其放到此线程的g0(这里是m0.g0)所在的runq队列,并且优先插入到队列的前端(runqput第三个参数为true),做完这些后,我们可以得出以下的关系:

2. 调度main goroutine
上一节我们分析了main goroutine的创建过程,这一节我们讨论一下,调度器如何把main goroutine调度到CPU上去运行。让我们继续回到runtime/asm_amd64.s中,在完成runtime.newproc创建完main goroutine之后,正式执行runtime·mstart来执行,而runtime·mstart最终会调用go写的runtime·mstart0函数。
// start this M
CALL runtime·mstart(SB)CALL runtime·abort(SB) // mstart should never return
RET
TEXT runtime·mstart(SB),NOSPLIT|TOPFRAME,$0
CALL runtime·mstart0(SB)
RET // not reached
runtime·mstart0函数如下:
func mstart0() {
_g_ := getg() // _g_ = &g0
osStack := _g_.stack.lo == 0
if osStack { // g0的stack.lo已经初始化,所以不会走以下逻辑
// Initialize stack bounds from system stack.
// Cgo may have left stack size in stack.hi.
// minit may update the stack bounds.
//
// Note: these bounds may not be very accurate.
// We set hi to &size, but there are things above
// it. The 1024 is supposed to compensate this,
// but is somewhat arbitrary.
size := _g_.stack.hi
if size == 0 {
size = 8192 * sys.StackGuardMultiplier
}
_g_.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
_g_.stack.lo = _g_.stack.hi - size + 1024
}
// Initialize stack guard so that we can start calling regular
// Go code.
_g_.stackguard0 = _g_.stack.lo + _StackGuard
// This is the g0, so we can also call go:systemstack
// functions, which check stackguard1.
_g_.stackguard1 = _g_.stackguard0
mstart1()
// Exit this thread.
if mStackIsSystemAllocated() {
// Windows, Solaris, illumos, Darwin, AIX and Plan 9 always system-allocate
// the stack, but put it in _g_.stack before mstart,
// so the logic above hasn't set osStack yet.
osStack = true
}
mexit(osStack)
}
以上代码设置了一些栈信息之后,调用runtime.mstart1函数:
func mstart1() {
_g_ := getg() // _g_ = &g0
if _g_ != _g_.m.g0 { // _g_ = &g0
throw("bad runtime·mstart")
}
// Set up m.g0.sched as a label returning to just
// after the mstart1 call in mstart0 above, for use by goexit0 and mcall.
// We're never coming back to mstart1 after we call schedule,
// so other calls can reuse the current frame.
// And goexit0 does a gogo that needs to return from mstart1
// and let mstart0 exit the thread.
_g_.sched.g = guintptr(unsafe.Pointer(_g_))
_g_.sched.pc = getcallerpc() // getcallerpc()获取mstart1执行完的返回地址
_g_.sched.sp = getcallersp() // getcallersp()获取调用mstart1时的栈顶地址
asminit()
minit() // 信号相关初始化
// Install signal handlers; after minit so that minit can
// prepare the thread to be able to handle the signals.
if _g_.m == &m0 {
mstartm0()
}
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
schedule()
}
可以看到mstart1函数保存额调度相关的信息,特别是保存了正在运行的g0的下一条指令和栈顶地址, 这些调度信息对于goroutine而言是很重要的。
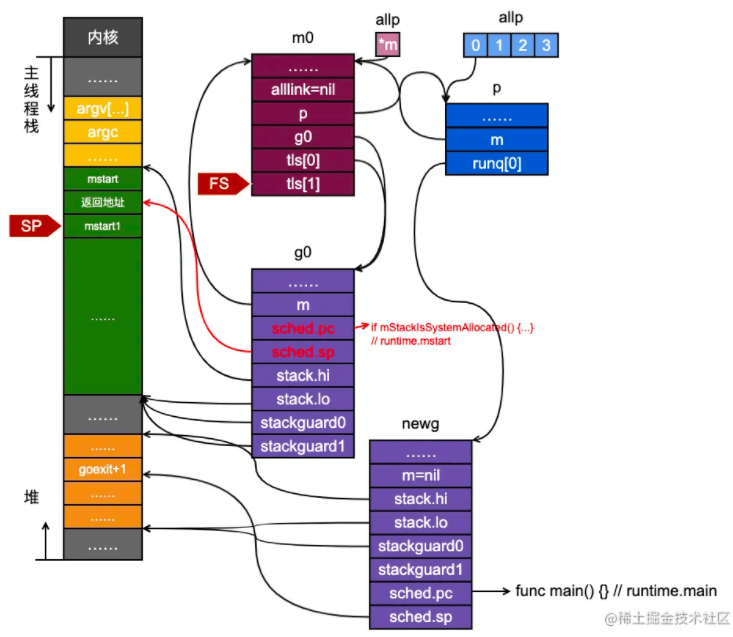
接下来就是golang调度系统的核心函数runtime.schedule了:
func schedule() {
_g_ := getg() // _g_ 是每个工作线程的m的m0,在初始化的场景就是m0.g0
...
var gp *g
var inheritTime bool
...
if gp == nil {
// 为了保证调度的公平性,每进行61次调度就需要优先从全局队列中获取goroutine
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil { // 从p本地的队列中获取goroutine
gp, inheritTime = runqget(_g_.m.p.ptr())
// We can see gp != nil here even if the M is spinning,
// if checkTimers added a local goroutine via goready.
}
if gp == nil { // 如果以上两者都没有,那么就需要从其他p哪里窃取goroutine
gp, inheritTime = findrunnable() // blocks until work is available
}
...
execute(gp, inheritTime)
}
以上我们节选了一些和调度相关的代码,意图简化我们的理解,调度中获取goroutine的规则是:
- 每调度61次就需要从全局队列中获取
goroutine; - 其次优先从本P所在队列中获取
goroutine; - 如果还没有获取到,则从其他P的运行队列中窃取
goroutine;
最后调用runtime.excute函数运行代码:
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// Assign gp.m before entering _Grunning so running Gs have an
// M.
_g_.m.curg = gp
gp.m = _g_.m
casgstatus(gp, _Grunnable, _Grunning) // 设置gp的状态
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
...
gogo(&gp.sched)
}
在完成gp运行前的准备工作后,excute函数调用gogo函数完成从g0到gp的转换:
- 让出CPU的执行权;
- 栈的切换;
gogo函数是用汇编语言编写的精悍的一段代码,这里就不详细分析了,其主要做了两件事:
- 把
gp.sched的成员恢复到CPU的寄存器完成状态以及栈的切换; - 跳转到
gp.sched.pc所指的指令地址(runtime.main)处执行。
func main() {
g := getg() // _g_ = main_goroutine
// Racectx of m0->g0 is used only as the parent of the main goroutine.
// It must not be used for anything else.
g.m.g0.racectx = 0
// golang栈的最大值
// Max stack size is 1 GB on 64-bit, 250 MB on 32-bit.
// Using decimal instead of binary GB and MB because
// they look nicer in the stack overflow failure message.
if goarch.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}
// An upper limit for max stack size. Used to avoid random crashes
// after calling SetMaxStack and trying to allocate a stack that is too big,
// since stackalloc works with 32-bit sizes.
maxstackceiling = 2 * maxstacksize
// Allow newproc to start new Ms.
mainStarted = true
// 需要切换到g0栈去执行newm
// 创建监控线程,该线程独立于调度器,无需与P关联
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
systemstack(func() {
newm(sysmon, nil, -1)
})
}
// Lock the main goroutine onto this, the main OS thread,
// during initialization. Most programs won't care, but a few
// do require certain calls to be made by the main thread.
// Those can arrange for main.main to run in the main thread
// by calling runtime.LockOSThread during initialization
// to preserve the lock.
lockOSThread()
if g.m != &m0 {
throw("runtime.main not on m0")
}
// Record when the world started.
// Must be before doInit for tracing init.
runtimeInitTime = nanotime()
if runtimeInitTime == 0 {
throw("nanotime returning zero")
}
if debug.inittrace != 0 {
inittrace.id = getg().goid
inittrace.active = true
}
// runtime包的init
doInit(&runtime_inittask) // Must be before defer.
// Defer unlock so that runtime.Goexit during init does the unlock too.
needUnlock := true
defer func() {
if needUnlock {
unlockOSThread()
}
}()
gcenable()
main_init_done = make(chan bool)
if iscgo {
if _cgo_thread_start == nil {
throw("_cgo_thread_start missing")
}
if GOOS != "windows" {
if _cgo_setenv == nil {
throw("_cgo_setenv missing")
}
if _cgo_unsetenv == nil {
throw("_cgo_unsetenv missing")
}
}
if _cgo_notify_runtime_init_done == nil {
throw("_cgo_notify_runtime_init_done missing")
}
// Start the template thread in case we enter Go from
// a C-created thread and need to create a new thread.
startTemplateThread()
cgocall(_cgo_notify_runtime_init_done, nil)
}
doInit(&main_inittask) // main包的init,会递归调用import的包的初始化函数
// Disable init tracing after main init done to avoid overhead
// of collecting statistics in malloc and newproc
inittrace.active = false
close(main_init_done)
needUnlock = false
unlockOSThread()
if isarchive || islibrary {
// A program compiled with -buildmode=c-archive or c-shared
// has a main, but it is not executed.
return
}
fn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime
fn() // 执行main函数
if raceenabled {
racefini()
}
// Make racy client program work: if panicking on
// another goroutine at the same time as main returns,
// let the other goroutine finish printing the panic trace.
// Once it does, it will exit. See issues 3934 and 20018.
if atomic.Load(&runningPanicDefers) != 0 {
// Running deferred functions should not take long.
for c := 0; c < 1000; c++ {
if atomic.Load(&runningPanicDefers) == 0 {
break
}
Gosched()
}
}
if atomic.Load(&panicking) != 0 {
gopark(nil, nil, waitReasonPanicWait, traceEvGoStop, 1)
}
exit(0)
for {
var x *int32
*x = 0
}
}
runtime.main函数的主要工作是:
- 启动一个
sysmon系统监控线程,该线程负责程序的gc、抢占调度等; - 执行
runtime包和所有包的初始化; - 执行
main.main函数; - 最后调用
exit系统调用退出进程,之前提到的注入goexit程序对main goroutine不起作用,是为了其他线程的回收而做的。
以上就是Golang并发编程之main goroutine的创建与调度详解的详细内容,更多关于Golang main goroutine的资料请关注我们其它相关文章!
相关推荐
-

Go语言中的并发goroutine底层原理
目录 一.基本概念 ①并发.并行区分 ②从用户态线程,内核态线程阐述go与java并发的优劣 ②高并发为什么是Go语言强项? ③Go语言实现高并发底层GMP模型原理解析 二.上代码学会Go语言并发 ①.开启一个简单的线程 ②.动态的关闭线程 一.基本概念 ①并发.并行区分 1.概念 并发:同一时间段内一个对象执行多个任务,充分利用时间 并行:同一时刻,多个对象执行多个任务 2.图解 类似于超市柜台结账,并行是多个柜台结多个队列,在计算机中是多核cpu处理多个go语言开启的线程,并发是一个柜台结账
-
深入Go goroutine理解
Go语言最大的特色就是从语言层面支持并发(Goroutine),Goroutine是Go中最基本的执行单元.事实上每一个Go程序至少有一个Goroutine:主Goroutine.当程序启动时,它会自动创建. 为了更好理解Goroutine,现讲一下线程和协程的概念 线程(Thread):有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元.一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成.另外,线程是进程中的一个实体,是被系统独立调
-
Golang 语言控制并发 Goroutine的方法
goroutine 是 Go语言中的轻量级线程实现,由 Go 运行时(runtime)管理.Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU. 01介绍 Golang 语言的优势之一是天生支持并发,我们在 Golang 语言开发中,通常使用的并发控制方式主要有 Channel,WaitGroup 和 Context,本文我们主要介绍一下 Golang 语言中并发控制的这三种方式怎么使用?关于它们各自的详细介绍在之前的文章已经介绍过,感兴趣的读者朋友们可以按需翻阅. 02
-
Go并发的方法之goroutine模型与调度策略
目录 单进程操作系统 多线程/多进程操作系统 1:N模型 M:N模型 goroutine goroutine早期调度器 GMP 调度器设计策略 复用线程 并行 抢占 全局队列 学习刘丹冰<8小时转职golang工程师>,本节都是原理 单进程操作系统 早期的单进程操作系统,可以理解为只有一个时间轴,CPU顺序执行每一个进程/线程,这种顺序执行的方式,CPU同一时间智能处理一个指令,一个任务一个任务去处理 这样就会导致进程阻塞的话,CPU就会卡在当前进程,一直在等待,CPU就会浪费 多线程/多进程
-
Golang并发编程之main goroutine的创建与调度详解
目录 0. 简介 1. 创建main goroutine 2. 调度main goroutine 0. 简介 上一篇博客我们分析了调度器的初始化,这篇博客我们正式进入main函数及为其创建的goroutine的过程分析. 1. 创建main goroutine 接上文,在runtime/asm_amd64.s文件的runtime·rt0_go中,在执行完runtime.schedinit函数进行调度器的初始化后,就开始创建main goroutine了. // create a new goro
-
golang利用不到20行代码实现路由调度详解
前言 本文主要介绍了关于golang实现路由调度的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 项目地址 github (本地下载) 本项目依赖 使用标准库实现,无额外依赖 为什么需要路由调度层 golang http标准库只能精确匹配请求的URI,然后执行handler.现在一般web项目都至少有个Controller层,以struct实现,根据不同的请求路径派发到不同的方法中去. 路由调度器定义 由于golang暂时还不可以动态创建对象(比如java的Class.
-
Java并发编程之Semaphore(信号量)详解及实例
Java并发编程之Semaphore(信号量)详解及实例 概述 通常情况下,可能有多个线程同时访问数目很少的资源,如客户端建立了若干个线程同时访问同一数据库,这势必会造成服务端资源被耗尽的地步,那么怎样能够有效的来控制不可预知的接入量呢?及在同一时刻只能获得指定数目的数据库连接,在JDK1.5 java.util.concurrent 包中引入了Semaphore(信号量),信号量是在简单上锁的基础上实现的,相当于能令线程安全执行,并初始化为可用资源个数的计数器,通常用于限制可以访问某些资源(物
-
浅谈Java并发编程之Lock锁和条件变量
简单使用Lock锁 Java 5中引入了新的锁机制--java.util.concurrent.locks中的显式的互斥锁:Lock接口,它提供了比synchronized更加广泛的锁定操作.Lock接口有3个实现它的类:ReentrantLock.ReetrantReadWriteLock.ReadLock和ReetrantReadWriteLock.WriteLock,即重入锁.读锁和写锁.lock必须被显式地创建.锁定和释放,为了可以使用更多的功能,一般用ReentrantLock为其实例
-
Java并发编程之Semaphore的使用简介
简介 Semaphore是用来限制访问特定资源的并发线程的数量,相对于内置锁synchronized和重入锁ReentrantLock的互斥性来说,Semaphore可以允许多个线程同时访问共享资源. Semaphored的使用 构造方法 Semaphore(int permits):创建Semaphore,并指定许可证的数量.(公平策略为非公平) Semaphore(int permits, boolean fair):创建Semaphore,并指定许可证的数量和公平策略. 核心方法 acqu
-
Java并发编程之Executors类详解
一.Executors的理解 Executors类属于java.util.concurrent包: 线程池的创建分为两种方式:ThreadPoolExecutor 和 Executors: Executors(静态Executor工厂)用于创建线程池: 工厂和工具方法Executor , ExecutorService , ScheduledExecutorService , ThreadFactory和Callable在此包中定义的类: jdk1.8API中的解释如下: 二.Executors
-
Java并发编程之Executor接口的使用
一.Executor接口的理解 Executor属于java.util.concurrent包下: Executor是任务执行机制的核心接口: 二.Executor接口的类图结构 由类图结构可知: ThreadPoolExecutor 继承了AbstractExecutorService接口: AbstractExecutorService接口实现了ExecutorService接口: ExecutorService继承了Executor接口: 因此以下部分主要讲解ThreadPoolExecu
-
Java并发编程之ReentrantLock实现原理及源码剖析
目录 一.ReentrantLock简介 二.ReentrantLock使用 三.ReentrantLock源码分析 1.非公平锁源码分析 2.公平锁源码分析 前面<Java并发编程之JUC并发核心AQS同步队列原理剖析>介绍了AQS的同步等待队列的实现原理及源码分析,这节我们将介绍一下基于AQS实现的ReentranLock的应用.特性.实现原理及源码分析. 一.ReentrantLock简介 ReentrantLock位于Java的juc包里面,从JDK1.5开始出现,是基于AQS同步队列
-
Java并发编程之Condition源码分析(推荐)
Condition介绍 上篇文章讲了ReentrantLock的加锁和释放锁的使用,这篇文章是对ReentrantLock的补充.ReentrantLock#newCondition()可以创建Condition,在ReentrantLock加锁过程中可以利用Condition阻塞当前线程并临时释放锁,待另外线程获取到锁并在逻辑后通知阻塞线程"激活".Condition常用在基于异步通信的同步机制实现中,比如dubbo中的请求和获取应答结果的实现. 常用方法 Condition中主要的
-
深入分析Java并发编程之CAS
在Java并发编程的世界里,synchronized 和 Lock 是控制多线程并发环境下对共享资源同步访问的两大手段.其中 Lock 是 JDK 层面的锁机制,是轻量级锁,底层使用大量的自旋+CAS操作实现的. 学习并发推荐<Java并发编程的艺术> 那什么是CAS呢?CAS,compare and swap,即比较并交换,什么是比较并交换呢?在Lock锁的理念中,采用的是一种乐观锁的形式,即多线程去修改共享资源时,不是在修改之前就加锁,而是乐观的认为没有别的线程和自己争锁,就是通过CAS的