netty pipeline中的inbound和outbound事件传播分析
目录
- 传播inbound事件
- 两种写法
- DefaultChannelPipeline.fireChannelRead(msg)
- AbstractChannelHandlerContext.invokeChannelRead(head, msg)
- AbstractChannelHandlerContext.invokeChannelRead(m)
- HeadContext的channelRead方法
- AbstractChannelHandlerContext.fireChannelRead(msg)
- AbstractChannelHandlerContext.findContextInbound()
- AbstractChannelHandlerContext.fireChannelRead(msg)
- AbstractChannelHandlerContext.invokeChannelRead(final AbstractChannelHandlerContext next, Object msg)
- AbstractChannelHandlerContext.invokeChannelRead(Object msg)
- tailConext的channelRead方法
- onUnhandledInboundMessage(msg)
- 传播outBound事件
- 两种写法
- AbstractChannel.write(Object msg)
- DefaultChannelPipeline.write(msg)
- AbstractChannelHandlerContext.write(Object msg)
- AbstractChannelHandlerContext.write(final Object msg, final ChannelPromise promise)
- AbstractChannelHandlerContext.write(Object msg, boolean flush, ChannelPromise promise)
- AbstractChannelHandlerContext.findContextOutbound()
- AbstractChannelHandlerContext.invokeWrite(Object msg, ChannelPromise promise)
- AbstractChannelHandlerContext.invokeWrite0(Object msg, ChannelPromise promise)
- ChannelOutboundHandlerAdapter.write
- AbstractChannelHandlerContext.write(Object msg, boolean flush, ChannelPromise promise)
- HeadContext.write
- inbound事件和outbound事件的传输流程图
传播inbound事件
有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelRead事件, 就是对方发来数据流的所触发的事件, 己方要对这些数据进行处理, 这一小节, 以激活channelRead为例讲解有关inbound事件的处理流程。
在业务代码中, 我们自己的handler往往会通过重写channelRead方法来处理对方发来的数据, 那么对方发来的数据是如何走到channelRead方法中了呢, 也是我们这一小节要剖析的内容。
在业务代码中, 传递channelRead事件方式是通过fireChannelRead方法进行传播的。
两种写法
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//写法1:
ctx.fireChannelRead(msg);
//写法2
ctx.pipeline().fireChannelRead(msg);
}
这里重写了channelRead方法, 并且方法体内继续通过fireChannelRead方法进行传播channelRead事件, 那么这两种写法有什么异同?
我们先以写法2为例, 将这种写法进行剖析。
这里首先获取当前context的pipeline对象, 然后通过pipeline对象调用自身的fireChannelRead方法进行传播, 因为默认创建的DefaultChannelpipeline。
DefaultChannelPipeline.fireChannelRead(msg)
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
这里首先调用的是AbstractChannelHandlerContext类的静态方法invokeChannelRead, 参数传入head节点和事件的消息
AbstractChannelHandlerContext.invokeChannelRead(head, msg)
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
这里的m通常就是我们传入的msg, 而next, 目前是head节点, 然后再判断是否为当前eventLoop线程, 如果不是则将方法包装成task交给eventLoop线程处理
AbstractChannelHandlerContext.invokeChannelRead(m)
private void invokeChannelRead(Object msg) {
if (invokeHandler()) {
try {
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
} else {
fireChannelRead(msg);
}
}
首先通过invokeHandler()判断当前handler是否已添加, 如果添加, 则执行当前handler的chanelRead方法, 其实这里就明白了, 通过fireChannelRead方法传递事件的过程中, 其实就是找到相关handler执行其channelRead方法, 由于我们在这里的handler就是head节点, 所以我们跟到HeadContext的channelRead方法中
HeadContext的channelRead方法
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//向下传递channelRead事件
ctx.fireChannelRead(msg);
}
在这里我们看到, 这里通过fireChannelRead方法继续往下传递channelRead事件, 而这种调用方式, 就是我们刚才分析用户代码的第一种调用方式
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//写法1:
ctx.fireChannelRead(msg);
//写法2
ctx.pipeline().fireChannelRead(msg);
}
这里直接通过context对象调用fireChannelRead方法, 那么和使用pipeline调用有什么区别的, 我会回到HeadConetx的channelRead方法, 我们来剖析ctx.fireChannelRead(msg)这句, 大家就会对这个问题有答案了, 跟到ctx的fireChannelRead方法中, 这里会走到AbstractChannelHandlerContext类中的fireChannelRead方法中
AbstractChannelHandlerContext.fireChannelRead(msg)
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
这里我们看到, invokeChannelRead方法中传入了一个findContextInbound()参数, 而这findContextInbound方法其实就是找到当前Context的下一个节点
AbstractChannelHandlerContext.findContextInbound()
private AbstractChannelHandlerContext findContextInbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.next;
} while (!ctx.inbound);
return ctx;
}
这里的逻辑也比较简单, 是通过一个doWhile循环, 找到当前handlerContext的下一个节点, 这里要注意循环的终止条件, while (!ctx.inbound)表示下一个context标志的事件不是inbound的事件, 则循环继续往下找, 言外之意就是要找到下一个标注inbound事件的节点
有关事件的标注, 之前已经进行了分析, 如果是用户定义的handler, 是通过handler继承的接口而定的, 如果tail或者head, 那么是在初始化的时候就已经定义好, 这里不再赘述
回到AbstractChannelHandlerContext.fireChannelRead(msg)
AbstractChannelHandlerContext.fireChannelRead(msg)
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
找到下一个节点后, 继续调用invokeChannelRead方法, 传入下一个和消息对象
AbstractChannelHandlerContext.invokeChannelRead(final AbstractChannelHandlerContext next, Object msg)
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
这里的逻辑我们又不陌生了, 因为我们传入的是当前context的下一个节点, 所以这里会调用下一个节点invokeChannelRead方法, 因我们刚才剖析的是head节点, 所以下一个节点有可能是用户添加的handler的包装类HandlerConext的对象
AbstractChannelHandlerContext.invokeChannelRead(Object msg)
private void invokeChannelRead(Object msg) {
if (invokeHandler()) {
try {
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
//发生异常的时候在这里捕获异常
notifyHandlerException(t);
}
} else {
fireChannelRead(msg);
}
}
又是我们熟悉的逻辑, 调用了自身handler的channelRead方法, 如果是用户自定义的handler, 则会走到用户定义的channelRead()方法中去, 所以这里就解释了为什么通过传递channelRead事件, 最终会走到用户重写的channelRead方法中去
同样, 也解释了该小节最初提到过的两种写法的区别
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//写法1:
ctx.fireChannelRead(msg);
//写法2
ctx.pipeline().fireChannelRead(msg);
}
- 写法1是通过当前节点往下传播事件
- 写法2是通过头节点往下传递事件
- 所以, 在
handler中如果要在channelRead方法中传递channelRead事件, 一定要采用写法1的方式向下传递, 或者交给其父类处理, 如果采用2的写法则每次事件传输到这里都会继续从head节点传输, 从而陷入死循环或者发生异常 - 还有一点需要注意, 如果用户代码中
channelRead方法, 如果没有显示的调用ctx.fireChannelRead(msg)那么事件则不会再往下传播, 则事件会在这里终止, 所以如果我们写业务代码的时候要考虑有关资源释放的相关操作
如果ctx.fireChannelRead(msg)则事件会继续往下传播, 如果每一个handler都向下传播事件, 当然, 根据我们之前的分析channelRead事件只会在标识为inbound事件的HandlerConetext中传播, 传播到最后, 则最终会调用到tail节点的channelRead方法
tailConext的channelRead方法
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
onUnhandledInboundMessage(msg);
}
onUnhandledInboundMessage(msg)
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug(
"Discarded inbound message {} that reached at the tail of the pipeline. " +
"Please check your pipeline configuration.", msg);
} finally {
//释放资源
ReferenceCountUtil.release(msg);
}
}
这里做了释放资源的相关的操作
到这里,对于inbound事件的传输流程以及channelRead方法的执行流程已经分析完毕。
传播outBound事件
有关于outBound事件, 和inbound正好相反,以自己为基准, 流向对方的事件, 比如最常见的wirte事件
在业务代码中, , 有可能使用wirte方法往写数据
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.channel().write("test data");
}
当然, 直接调用write方法是不能往对方channel中写入数据的, 因为这种方式只能写入到缓冲区, 还要调用flush方法才能将缓冲区数据刷到channel中, 或者直接调用writeAndFlush方法, 有关逻辑, 我们会在后面章节中详细讲解, 这里只是以wirte方法为例为了演示outbound事件的传播的流程
两种写法
public void channelActive(ChannelHandlerContext ctx) throws Exception {
//写法1
ctx.channel().write("test data");
//写法2
ctx.write("test data");
}
这两种写法有什么区别, 首先分析第一种写法
//这里获取ctx所绑定的channel
ctx.channel().write("test data");
AbstractChannel.write(Object msg)
public ChannelFuture write(Object msg) {
//这里pipeline是DefaultChannelPipeline
return pipeline.write(msg);
}
继续跟踪DefaultChannelPipeline.write(msg)
DefaultChannelPipeline.write(msg)
public final ChannelFuture write(Object msg) {
//从tail节点开始(从最后的节点往前写)
return tail.write(msg);
}
这里调用tail节点write方法, 这里我们应该能分析到, outbound事件, 是通过tail节点开始往上传播的。
其实tail节点并没有重写write方法, 最终会调用其父类AbstractChannelHandlerContext.write方法
AbstractChannelHandlerContext.write(Object msg)
public ChannelFuture write(Object msg) {
return write(msg, newPromise());
}
这里有个newPromise()这个方法, 这里是创建一个Promise对象, 有关Promise的相关知识会在以后章节进行分析,继续分析write
AbstractChannelHandlerContext.write(final Object msg, final ChannelPromise promise)
public ChannelFuture write(final Object msg, final ChannelPromise promise) {
/**
* 省略
* */
write(msg, false, promise);
return promise;
}
AbstractChannelHandlerContext.write(Object msg, boolean flush, ChannelPromise promise)
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
//没有调flush
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
这里跟我们之前分析过channelRead方法有点类似, 但是事件传输的方向有所不同, 这里findContextOutbound()是获取上一个标注outbound事件的HandlerContext
AbstractChannelHandlerContext.findContextOutbound()
private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
这里的逻辑跟之前的findContextInbound()方法有点像, 只是过程是反过来的
在这里, 会找到当前context的上一个节点, 如果标注的事件不是outbound事件, 则继续往上找, 意思就是找到上一个标注outbound事件的节点
回到AbstractChannelHandlerContext.write方法
AbstractChannelHandlerContext next = findContextOutbound();
这里将找到节点赋值到next属性中,因为我们之前分析的write事件是从tail节点传播的, 所以上一个节点就有可能是用户自定的handler所属的context
然后判断是否为当前eventLoop线程, 如果是不是, 则封装成task异步执行, 如果不是, 则继续判断是否调用了flush方法, 因为我们这里没有调用, 所以会执行到next.invokeWrite(m, promise)
AbstractChannelHandlerContext.invokeWrite(Object msg, ChannelPromise promise)
private void invokeWrite(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
} else {
write(msg, promise);
}
}
这里会判断当前handler的状态是否是添加状态, 这里返回的是true, 将会走到invokeWrite0(msg, promise)这一步
AbstractChannelHandlerContext.invokeWrite0(Object msg, ChannelPromise promise)
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
//调用当前handler的wirte()方法
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
这里的逻辑也似曾相识, 调用了当前节点包装的handler的write方法, 如果用户没有重写write方法, 则会交给其父类处理
ChannelOutboundHandlerAdapter.write
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ctx.write(msg, promise);
}
这里调用了当前ctx的write方法, 这种写法和我们小节开始的写法是相同的, 我们回顾一下
public void channelActive(ChannelHandlerContext ctx) throws Exception {
//写法1
ctx.channel().write("test data");
//写法2
ctx.write("test data");
}
我们跟到其write方法中, 这里走到的是AbstractChannelHandlerContext类的write方法
AbstractChannelHandlerContext.write(Object msg, boolean flush, ChannelPromise promise)
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
//没有调flush
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
又是我们所熟悉逻辑, 找到当前节点的上一个标注事件为outbound事件的节点, 继续执行invokeWrite方法, 根据之前的剖析, 我们知道最终会执行到上一个handler的write方法中。
走到这里已经不难理解, ctx.channel().write("test data")其实是从tail节点开始传播写事件, 而ctx.write("test data")是从自身开始传播写事件。
所以, 在handler中如果重写了write方法要传递write事件, 一定采用ctx.write("test data")这种方式或者交给其父类处理处理, 而不能采用ctx.channel().write("test data")这种方式, 因为会造成每次事件传输到这里都会从tail节点重新传输, 导致不可预知的错误。
如果用代码中没有重写handler的write方法, 则事件会一直往上传输, 当传输完所有的outbound节点之后, 最后会走到head节点的wirte方法中。
HeadContext.write
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
我们看到write事件最终会流向这里, 通过unsafe对象进行最终的写操作
inbound事件和outbound事件的传输流程图
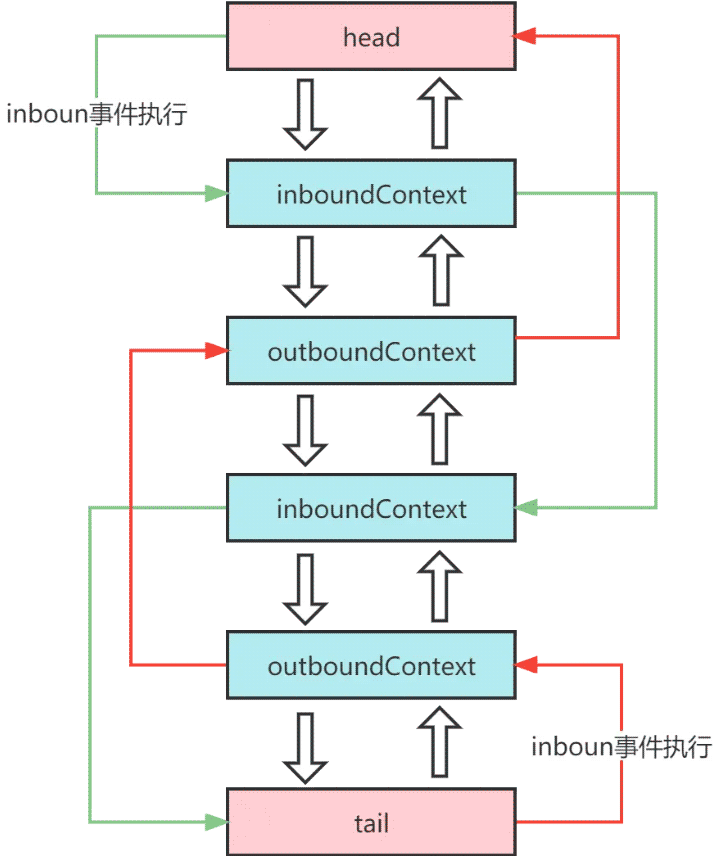
以上就是netty中pipeline的inbound和outbound事件传播分析的详细内容,更多关于netty pipeline事件传播的资料请关注我们其它相关文章!
相关推荐
-
Netty分布式pipeline管道传播事件的逻辑总结分析
目录 问题分析 首先完成了handler的添加, 但是并没有马上执行回调 回到callHandlerCallbackLater方法中 章节总结 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 问题分析 首先看两个问题: 1.在客户端接入的时候, NioMessageUnsafe的read方法中pipeline.fireChannelRead(readBuf.get(i))为什么会调用到ServerBootstrap的内部类ServerBootstrapAccep
-

Netty分布式pipeline管道Handler的删除逻辑操作
目录 删除handler操作 我们跟到getContextPrDie这个方法中 首先要断言删除的节点不能是tail和head 回到remove(ctx)方法 上一小节我们学习了添加handler的逻辑操作, 这一小节我们学习删除handler的相关逻辑 删除handler操作 如果用户在业务逻辑中进行ctx.pipeline().remove(this)这样的写法, 或者ch.pipeline().remove(new SimpleHandler())这样的写法, 则就是对handler进行删除
-
Netty分布式pipeline传播inbound事件源码分析
前一小结回顾:pipeline管道Handler删除 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelRead事件, 就是对方发来数据流的所触发的事件, 己方要对这些数据进行处理, 这一小节, 以激活channelRead为例讲解有关inbound事件的处理流程 在业务代码中, 我们自己的handler往往会通过重写channelRead方法来处理对方发来的数据, 那么对方发来的数据是如何走到chann
-
netty中pipeline异常事件分析
目录 异常处理的场景 AbstractChannelHandlerContext.invokeChannelRead AbstractChannelHandlerContext.notifyHandlerException(Throwable cause) AbstractChannelHandlerContext.invokeExceptionCaught(final Throwable cause) 两种写法 DefualtChannelPipeline.fireExceptionCaugh
-
netty服务端处理请求联合pipeline分析
目录 两个问题 NioMessageUnsafe.read() ServerBootstrap.init(Channel channel) ChannelInitializer的继承关系 PendingHandlerAddedTask构造方法 PendingHandlerCallback构造方法 回到callHandlerCallbackLater方法 AbstractChannel.register0(ChannelPromise promise) pipeline.invokeHandler
-
Netty分布式pipeline管道传播outBound事件源码解析
目录 outbound事件传输流程 这里我们同样给出两种写法 跟到其write方法中: 跟到findContextOutbound中 回到write方法: 继续跟invokeWrite0 我们跟到HeadContext的write方法中 了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难 outbound事件传输流程 在我们业务代码中, 有可能使用wirte方法往写数据: public void channelActive(ChannelHandlerC
-
Netty分布式pipeline管道异常传播事件源码解析
目录 传播异常事件 简单的异常处理的场景 我们跟到invokeChannelRead这个方法 我还是通过两种写法来进行剖析 跟进invokeExceptionCaught方法 跟到invokeExceptionCaught方法中 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 传播异常事件 简单的异常处理的场景 @Override public void channelRead(ChannelHandlerContext ctx, Object msg
-
netty pipeline中的inbound和outbound事件传播分析
目录 传播inbound事件 两种写法 DefaultChannelPipeline.fireChannelRead(msg) AbstractChannelHandlerContext.invokeChannelRead(head, msg) AbstractChannelHandlerContext.invokeChannelRead(m) HeadContext的channelRead方法 AbstractChannelHandlerContext.fireChannelRead(msg)
-
JavaScript中使用stopPropagation函数停止事件传播例子
JS中的事件默认是冒泡方式,逐层往上传播,可以通过stopPropagation()函数停止事件在DOM层次中的传播.如以下例子: HTML代码: <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>stopPropagation()使用 - 琼台博客</title> </head> <body> <button&
-
AngularJS中directive指令使用之事件绑定与指令交互用法示例
本文实例讲述了AngularJS中directive指令使用之事件绑定与指令交互用法.分享给大家供大家参考,具体如下: AngularJS中模板的使用,事件绑定以及指令与指令之间的交互 <!doctype html> <html ng-app="myapp"> <head> <meta charset="utf-8"/> </head> <body ng-controller="Shield
-
IOS 中UIImageView响应点击事件
IOS 中UIImageView响应点击事件 有时候会遇到点击一张图片,然后让这张图片触发一个事件,或者是跳转视图,想到的第一个方法就是用UIButton,将Button的背景图片属性设置为该图片,效果达到了,但不是最好的方法,直接触发方法 定义Image的对象 UIImageView *imgView =[[UIImageView alloc] initWithFrame:CGRectMake(0, 0,320,100)]; imgView.backgroundColor = [UIColor
-
jquery中取消和绑定hover事件的实现代码
在网页设计中,我们经常使用jquery去响应鼠标的hover事件,和mouseover和mouseout事件有相同的效果,但是这其中其中如何使用bind去绑定hover方法呢?如何用unbind取消绑定的事件呢? 一.如何绑定hover事件 先看以下代码,假设我们给a标签绑定一个click和hover事件: $(document).ready(function(){ $('a').bind({ hover: function(e) { // Hover event handler alert("
-
angularjs中回车键触发某一事件的方法
要求:在输入框中输入值以后,按回车键触发某一事件的执行 html: <input id="input" name="input" ng-model="querykdUser.page.pageSize" ng-keyup="myKeyup($event)" class="form-control" style="width:60px;"> js: $scope.myKeyup
-
简单讲解Android开发中触摸和点击事件的相关编程方法
在Android上,不止一个途径来侦听用户和应用程序之间交互的事件.对于用户界面里的事件,侦听方法就是从与用户交互的特定视图对象截获这些事件.视图类提供了相应的手段. 在各种用来组建布局的视图类里面,你可能会注意到一些公共的回调方法看起来对用户界面事件有用.这些方法在该对象的相关动作发生时被Android框架调用.比如,当一个视图(如一个按钮)被触摸时,该对象上的onTouchEvent()方法会被调用.不过,为了侦听这个事件,你必须扩展这个类并重写该方法.很明显,扩展每个你想使用的视图对象(只
-
Python中pygame的mouse鼠标事件用法实例
本文实例讲述了Python中pygame的mouse鼠标事件用法.分享给大家供大家参考,具体如下: pygame.mouse提供了一些方法获取鼠标设备当前的状态 ''' pygame.mouse.get_pressed - get the state of the mouse buttons get the state of the mouse buttons pygame.mouse.get_pos - get the mouse cursor position get the mouse c
-
深入理解在JS中通过四种设置事件处理程序的方法
所有的JavaScript事件处理程序的作用域是在其定义时的作用域而非调用时的作用域中执行,并且它们能存取那个作用域中的任何一个本地变量.但是HTML标签属性注册处理程序就是一个例外.看下面四种方式: 第一种方式(HTML标签属性): <input type="button" id="btn1" value="测试" onclick="alert(this.id);" /> 上面的代码是通过设置HTML标签属性为给
-
js中class的点击事件没有效果的解决方法
如下所示: $(".xx").clcik(function(){····}); 本来不用js生成类,是有点击效果的一但js里写,就没有点击效果了,如下: 做如下修改即可,监听document 以上就是小编为大家带来的js中class的点击事件没有效果的解决方法全部内容了,希望大家多多支持我们~