基于MongoDB数据库索引构建情况全面分析
前面的话
本文将详细介绍MongoDB数据库索引构建情况分析
概述
创建索引可以加快索引相关的查询,但是会增加磁盘空间的消耗,降低写入性能。这时,就需要评判当前索引的构建情况是否合理。有4种方法可以使用
1、mongostat工具
2、profile集合介绍
3、日志
4、explain分析
mongostat
mongostat是mongodb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。如果发现数据库突然变慢或者有其他问题的话,首先就要考虑采用mongostat来查看mongo的状态
mongostat是查看mongodb运行状态的程序,使用方式如下
mongostat -h ip:port
【字段说明】
insert/s : 每秒插入数据库的对象数量,如果是slave,则数值前有*,则表示复制集操作 query/s : 每秒的查询操作次数 update/s : 每秒的更新操作次数 delete/s : 每秒的删除操作次数 getmore/s: 每秒查询cursor(游标)时的getmore操作数 command: 每秒执行的命令数,在主从系统中会显示两个值(例如 3|0),分别代表 本地|复制 命令 dirty: 脏数据字节的缓存百分比 used:正在使用中的缓存百分比 flushes:checkpoint的触发次数在一个轮询间隔期间。一般都是0,间断性会是1, 通过计算两个1之间的间隔时间,可以大致了解多长时间flush一次。flush开销是很大的,如果频繁的flush,可能就要找找原因了 vsize: 虚拟内存使用量,单位MB res: 物理内存使用量,单位MB。 res会慢慢的上升,如果res经常突然下降,要查看下是否有别的程序狂吃内存 qr: 客户端等待从MongoDB实例读数据的队列长度 qw:客户端等待从MongoDB实例写入数据的队列长度 ar: 执行读操作的活跃客户端数量 aw: 执行写操作的活客户端数量。如果ar或aw数值很大,那么就是DB被堵住了,DB的处理速度不及请求速度。查看是否有开销很大的慢查询。如果查询一切正常,确实是负载很大,就需要加机器了 netIn:MongoDB实例的网络进流量 netOut:MongoDB实例的网络出流量 conn: 打开连接的总数,是qr,qw,ar,aw的总和 time:当前时间
【实例】
插入100000条数据,并打开mongostat查询mongodb运行状态
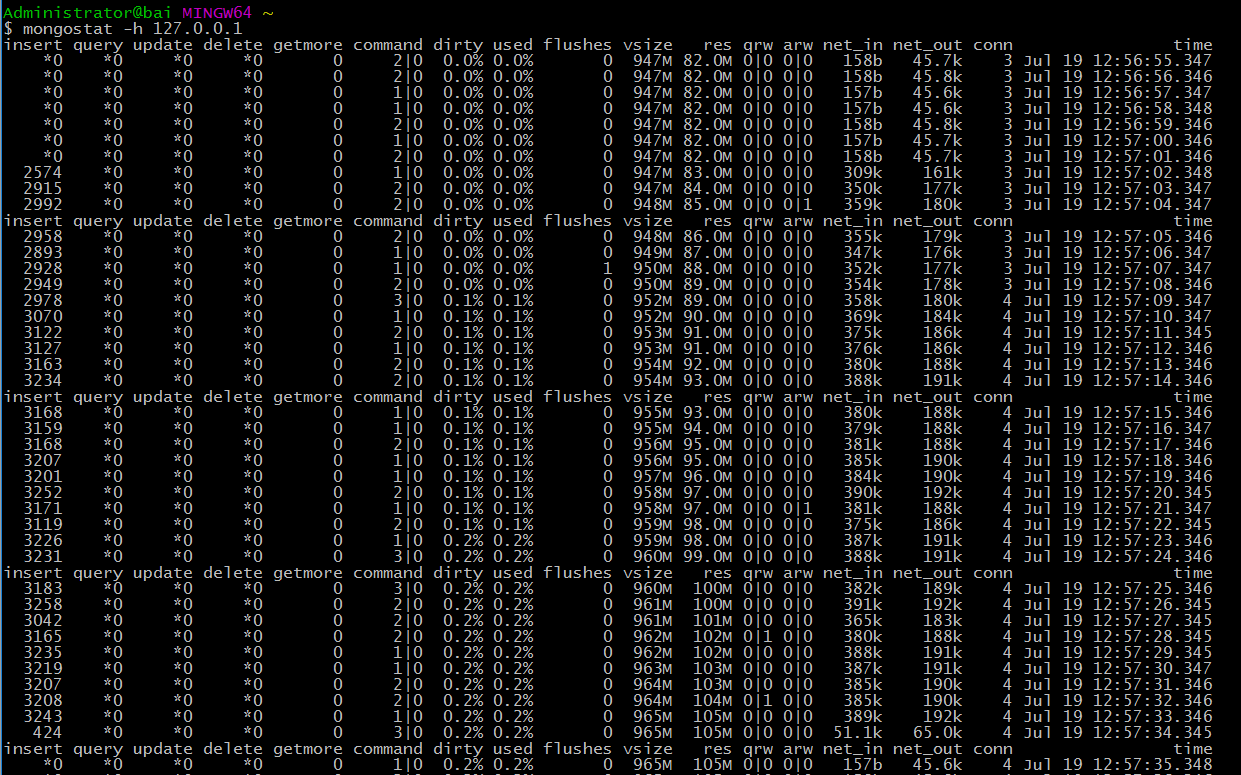
由下图看出,插入值insert值在插入数据时大量增加,在插入完毕后变成0。flush两个1之间的间隔时间很长,说明性能还不错;res在慢慢上升,没有出现突然下降的情况,说明没有其他的程序大量占用内容的情况;qrw及arw数据很小,说明数据库读写状态正常,负载较小。总体而言,mongodb数据库运行状态良好
profile
mongodb可以通过profile来监控数据,进行优化
【级别】
首先,要查看当前是否开启profile功能
使用下面的命令会返回level等级,值为0|1|2,0代表关闭,即不记录任何操作;1代表记录慢命令(默认值为100ms),即记录运行时间超过100ms的操作;2代表全部,即记录任何操作
db.getProfilingLevel()
使用下面的命令可以设置level等级
db.setProfilingLevel()
如下图所示,默认地,profile关闭。使用setProfilingLevel()方法以50ms慢命令的方式开启profile

【状态】
操作被记录到system.profile集合中
通过db.system.profile.find() 查看当前的监控日志


op:操作类型 ns:命名空间 query:查询字符串 responseLength:返回长度 ts:时间 mills:执行耗时
【使用】
在系统中开启profile之后,如果profile记录的数据非常大,会比较明显的降低系统的性能。因此,profile的使用场景一般是新系统上线之前的测试阶段,以及刚上线时的观察阶段,查看数据库的设计及应用程序的使用是否正常。如果profile记录了大量的字段,需要调整系统附在、调整索引等,减小它的大小
日志
在配置日志文件时,可以使用verbose参数来配置日志详细程度,参数值从'v'到'vvvvv','v'越多,详细度越高
日志会记录mongodb的运行状态,包括连接时间、当前正在进行的操作等
explain
MongoDB 提供了一个 explain 命令让我们获知系统如何处理查询请求。利用 explain 命令,可以很好地观察系统如何使用索引来加快检索,同时可以针对性优化索引
explain有三种模式,分别是:queryPlanner、executionStats、allPlansExecution。现实开发中,常用的是executionStats模式
首先,插入10万条数据

在time字段上建立索引
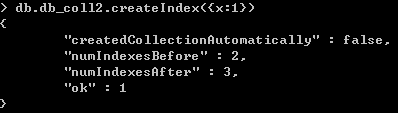
接着,寻找time范围在100和200之间的文档,并使用explain()
结果分为queryPlanner、executionStats和serverInfo三个部分。接下来,将分别对这三个部分的结果进行详细分析
【queryPlanner】

queryPlanner.plannerVersion: 版本
queryPlanner.namespace: 查询的表
queryPlanner.indexFilterSet: 针对该query是否有indexfilter
queryPlanner.parsedQuery: 查询条件
queryPlanner.winningPlan: 查询优化器针对该query所返回的最优执行计划的详细内容
queryPlanner.winningPlan.stage: 最优执行计划的stage
queryPlanner.winningPlan.inputStage: 用来描述子stage,并且为其父stage提供文档和索引关键字。
queryPlanner.winningPlan.inputstage.stage,此处是IXSCAN,表示进行的是index scanning
queryPlanner.winningPlan.inputstage.keyPattern: 索引键值对
queryPlanner.winningPlan.inputstage.indexName:索引名称
queryPlanner.winningPlan.inputstage.isMultiKey: 是否是Multikey,此处返回是false,如果索引建立在array上,此处将是true
queryPlanner.winningPlan.inputstage.direction:查询顺序,此处是forward,如果用了.sort({time:-1})将显示backward
queryPlanner.winningPlan.inputstage.indexBounds: 所扫描的索引范围
queryPlanner.rejectedPlans:其他执行计划
【executionStats】

executionStats.executionSuccess: 是否成功
executionStats.nReturned: 查询返回条目个数
executionStats.totalKeysExamined: 索引扫描条目个数
executionStats.totalDocsExamined: 文档扫描条目个数
executionStats.executionStages.stage: 扫描类型
executionStats.executionTimeMillis: 整体查询时间
executionStats.executionStages.executionTimeMillisEstimate: 根据索引检索文档获得数据的时间
executionStats.executionStages.inputStage.executionTimeMillisEstimate: 扫描索引所用时间
【serverInfo】

serverInfo.host: 主机名
serverInfo.port: 端口
serverInfo.version: 版本
serverInfo.gitVersion: git版本
【性能分析】
1、执行时间
executionTimeMillis值越小越好
2、条目数量
最理想的状态是: nReturned=totalKeysExamined=totalDocsExamined
3、stage类型
stage的类型列举如下:
COLLSCAN:全表扫描 IXSCAN:索引扫描 FETCH:根据索引去检索指定document SHARD_MERGE:将各个分片返回数据进行merge SORT:表明在内存中进行了排序 LIMIT:使用limit限制返回数 SKIP:使用skip进行跳过 IDHACK:针对_id进行查询 SHARDING_FILTER:通过mongos对分片数据进行查询 COUNT:利用db.coll.explain().count()之类进行count运算 COUNTSCAN:count不使用Index进行count时的stage返回 COUNT_SCAN:count使用了Index进行count时的stage返回 SUBPLA:未使用到索引的$or查询的stage返回 TEXT:使用全文索引进行查询时候的stage返回 PROJECTION:限定返回字段时候stage的返回
不希望看到包含如下的stage:
COLLSCAN(全表扫描) SORT(使用sort但是无index) 不合理的SKIP SUBPLA(未用到index的$or) COUNTSCAN(不使用index进行count)
以上这篇基于MongoDB数据库索引构建情况全面分析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
mongodb的安装使用和pymongo基本使用教程
(1) mongodb的安装 下载tgz解压后,需要添加相应的环境变量才能在终端直接启动mongod. mongodb数据存储在/data/db中,需要手动创建目录树,同时mongod执行的时候如果权限不够(不能往/data/db写东西),需要改一下权限. vim ~/.bashrc export PATH="~/download/mongodb-linux-x86_64-ubuntu/bin:$PATH" mkdir -p /data/db ls -l / 查看data目录的权限,发
-

Windows下MongoDb简单配置教程
如何在Windows下对MongoDb进行简单的配置,本文为大家解答. 以管理员的启动cmd 进入安装目录下 输入:mongod --auth --port 3406 --dbpath=库地址 --logpath= 全地址 --install --serviceName "自定义名称" 注:库地址可只指定到文件夹,LOG地址需指定到具体文件 --auth 启用权根控制 --port 指定端口 --ip 指定IP不指定则为本地 -- serviceName windows服务名称 上述完
-
基于MongoDB数据库的数据类型和$type操作符详解
前面的话 本文将详细介绍MongoDB数据库的数据类型和$type操作符 类型 数字 备注 Double 1 双精度浮点数 - 此类型用于存储浮点值 String 2 字符串 - 这是用于存储数据的最常用的数据类型.MongoDB中的字符串必须为UTF-8 Object 3 对象 - 此数据类型用于嵌入式文档 Array 4 数组 - 此类型用于将数组或列表或多个值存储到一个键中 Binary data 5 二进制数据 - 此数据类型用于存储二进制数据 Undefined 6 已废弃 Objec
-
Mongodb实战之全文搜索功能
前言 众所周知在传统的关系型数据库中,我们通常将数据结构化,通过一系列表关联.聚合来查询我们所需的结果.而在非结构化的数据中,缺少这种预定义的结构,因而如何快速查询定位到我们所需要的结果,不是一件容易的事. Mongodb作为一种NoSQL数据库,非常适合存储和管理非结构化数据,例如互联网上的各种文本数据.假如我们用Mongodb存储了很多博客文章,那么如何快速找到所有关于"nodejs"这个主题的文章呢?Mongodb内建的全文搜索可以帮助我们完成这个功能.下面话不多说了,来一起看看
-
利用node.js+mongodb如何搭建一个简单登录注册的功能详解
前言 最近突然对数据库和后台感兴趣了,就开始了漫长的学习之路,想想自己只是一个前端,只会java斯科瑞普,所以就开始看nodejs,看着看着突然发现mongodb和nodejs更配哦!,遂就开了我的mongodb之路.下面话不多说了,来一起看看详细的介绍吧. mongodb简介 就超简洁的说一下,mongo就是一个nosql的数据库,不使用sql的语法,当然其实也是大同小异的,增删改查还是差不多的,但是在概念上mongo还是跟mysql有相当大的区别的;比如在mongo中没有表的概念,而是一个集
-
Ubuntu16.04手动安装MongoDB的详细教程
我最近在研究MongoDB的路上,那么今天也算个学习笔记吧!今天用Ubuntu16.04手动安装MongoDB,分享给大家 注意事项: 仔细按步骤阅读操作 注意别写错字 牢记上面两点 一.用自带的火狐浏览器下载Ubuntu 16.04 Linux 64-bit x64 1.地址:http://www.mongodb.org/downloads 2.选择linux选项卡,再在下拉框中选中Ubuntu 16.04 Linux 64-bit x64 3.点击Download按钮(浏览器弹出的下载单选框
-
Mongodb实现的关联表查询功能【population方法】
本文实例讲述了Mongodb实现的关联表查询功能.分享给大家供大家参考,具体如下: Population MongoDB是非关联数据库.但是有时候我们还是想引用其它的文档.这就是population的用武之地. Population是从其它文档替换文档中的特定路径.我们可以迁移一个单一的文件,多个文件,普通对象,多个普通的对象,或从查询中返回的所有对象 populate 方法 populate 方法可以用在 document 上. model 上或者是 query 对象上,这意味着你几乎可以在任
-
MongoDB 管道的介绍及操作符实例
MongoDB 管道的介绍及操作符实例 一 介绍 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数. MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理.管道操作是可以重复的. 表达式:处理输入文档并输出.表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档. 这里我们介绍一下聚合框架中常用的几个操作: $project:修改输入文档的结构.可以用来重命名.增加或删除域,也可以用于创建计算结果以及嵌套文档. $m
-
基于MongoDB数据库索引构建情况全面分析
前面的话 本文将详细介绍MongoDB数据库索引构建情况分析 概述 创建索引可以加快索引相关的查询,但是会增加磁盘空间的消耗,降低写入性能.这时,就需要评判当前索引的构建情况是否合理.有4种方法可以使用 1.mongostat工具 2.profile集合介绍 3.日志 4.explain分析 mongostat mongostat是mongodb自带的状态检测工具,在命令行下使用.它会间隔固定时间获取mongodb的当前运行状态,并输出.如果发现数据库突然变慢或者有其他问题的话,首先就要考虑采用
-
MongoDB数据库索引用法详解
一.索引详讲 索引是什么,索引就好比一本书的目录,当我们想找某一章节的时候,通过书籍的目录可以很快的找到,所以适当的加入索引可以提高我们查询的数据的速度. 准备工作,向MongoDB中插入20000条记录,没条记录都有number和name > for(var i = 0 ; i<200000 ;i++){ ... db.books.insert({number:i,name:"book"+i}) ... } WriteResult({ "nInserted&qu
-
mongoDB数据库索引快速入门指南
目录 MongoDB 索引 1. 开始与准备数据 2. 创建索引前 3. 创建索引 createIndex 4. 创建索引后 6.唯一索引与符合索引 ①唯一索引 ②复合索引 MongoDB 索引 索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录. 这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的. 索引是特殊的数据结构,索引存储在一个易于遍历读取的数
-
基于MySQL数据库复制Master-Slave架构的分析
为了应用系统的可伸缩性,往往需要对数据库进行scale out设计,scale out设计也就是通过增加数据库处理节点来提高系统整体的处理能力,即增加数据库服务器的数量来分担压力.通过这种方式系统的伸缩性增强了,成本也降低了,但是系统的架构复杂了,维护困难了.难免出现系统的宕机或故障.因此,理论上来说,系统的安全性(可能数据丢失)降低了,可用性也降低了.那么要提高数据安全性,以及系统的高可用性,很简单的办法就是所有软硬件都避免单点隐患,所有数据都保存多份.从技术上来说,就可以通过数据库复制技术实
-
数据库索引的知识点整理小结,你所需要了解的都在这儿了
数据库索引,相信大家都不陌生吧. 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息.作为辅助查询的工具,合理的设计索引能很大程度上减轻db的查询压力,db我们都知道,是项目最核心也是最薄弱的地方,如果压力太大很容易产生故障,造成难以预计的影响.所以,不管是日常开发还是面试,索引这一块知识体系都是必须掌握的. 当然,虽说是必须掌握,但索引的知识点很多,很多初学者经常会遗漏,这也是我为什么想写这篇知识点总结的原因,既是给读者的分享,也是给自己一次全面的复习,
-
基于B-树和B+树的使用:数据搜索和数据库索引的详细介绍
B-树 1 .B-树定义 B-树是一种平衡的多路查找树,它在文件系统中很有用. 定义:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树:⑴树中每个结点至多有m 棵子树:⑵若根结点不是叶子结点,则至少有两棵子树: ⑶除根结点之外的所有非终端结点至少有[m/2] 棵子树:⑷所有的非终端结点中包含以下信息数据: (n,A0,K1,A1,K2,-,Kn,An)其中:Ki(i=1,2,-,n)为关键码,且Ki<Ki+1, Ai 为指向子树根结点的指针(i=0,1,-,n),且指针Ai-1 所指子
-
基于NodeJS+MongoDB+AngularJS+Bootstrap开发书店案例分析
这章的目的是为了把前面所学习的内容整合一下,这个示例完成一个简单图书管理模块,因为中间需要使用到Bootstrap这里先介绍Bootstrap. 示例名称:天狗书店 功能:完成前后端分离的图书管理功能,总结前端学习过的内容. 技术:NodeJS.Express.Monk.MongoDB.AngularJS.BootStrap.跨域 效果: 一.Bootstrap Bootstrap是一个UI框架,它支持响应式布局,在PC端与移动端都表现不错. Bootstrap是Twitter推出的一款简洁.直
-
MongoDB学习笔记(六) MongoDB索引用法和效率分析
MongoDB中的索引其实类似于关系型数据库,都是为了提高查询和排序的效率的,并且实现原理也基本一致.由于集合中的键(字段)可以是普通数据类型,也可以是子文档.MongoDB可以在各种类型的键上创建索引.下面分别讲解各种类型的索引的创建,查询,以及索引的维护等. 一.创建索引 1. 默认索引 MongoDB有个默认的"_id"的键,他相当于"主键"的角色.集合创建后系统会自动创建一个索引在"_id"键上,它是默认索引,索引名叫"_id_
-
MySQL中有哪些情况下数据库索引会失效详析
前言 要想分析MySQL查询语句中的相关信息,如是全表查询还是部分查询,就要用到explain. 索引的优点 大大减少了服务器需要扫描的数据量 可以帮助服务器避免排序或减少使用临时表排序 索引可以随机I/O变为顺序I/O 索引的缺点 需要占用磁盘空间,因此冗余低效的索引将占用大量的磁盘空间 降低DML性能,对于数据的任意增删改都需要调整对应的索引,甚至出现索引分裂 索引会产生相应的碎片,产生维护开销 一.explain 用法:explain +查询语句. id:查询语句的序列号,上面图片中只有一