用.NET Core写爬虫爬取电影天堂
自从上一个项目从.NET迁移到.NET core之后,磕磕碰碰磨蹭了一个月才正式上线到新版本。
然后最近又开了个新坑,搞了个爬虫用来爬dy2018电影天堂上面的电影资源。这里也借机简单介绍一下如何基于.NET Core写一个爬虫。
PS:如有偏错,敬请指明…
PPS:该去电影院还是多去电影院,毕竟美人良时可无价。
准备工作(.NET Core准备)
首先,肯定是先安装.NET Core咯。下载及安装教程在这里: http://www.jb51.net/article/87907.htm http://www.jb51.net/article/88735.htm。无论你是Windows、linux还是mac,统统可以玩。
我这里的环境是:Windows10 + VS2015 community updata3 + .NET Core 1.1.0 SDK + .NET Core 1.0.1 tools Preview 2.
理论上,只需要安装一下 .NET Core 1.1.0 SDK 即可开发.NET Core程序,至于用什么工具写代码都无关紧要了。
安装好以上工具之后,在VS2015的新建项目就可以看到.NET Core的模板了。如下图:
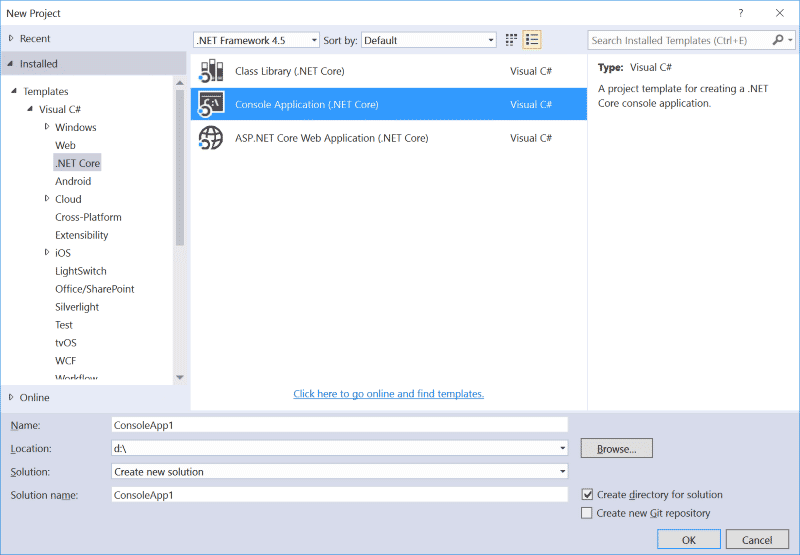
为了简单起见,我们创建的时候,直接选择VS .NET Core tools自带的模板。
一个爬虫的自我修养 分析网页
写爬虫之前,我们首先要先去了解一下即将要爬取的网页数据组成。
具体到网页的话,便是分析我们要抓取的数据在HTML里面是用什么标签抑或有什么样的标记,然后使用这个标记把数据从HTML中提取出来。在我这里的话,用的更多的是HTML标签的ID和CSS属性。
以本文章想要爬取的dy2018.com为例,简单描述一下这个过程。dy2018.com主页如下图:
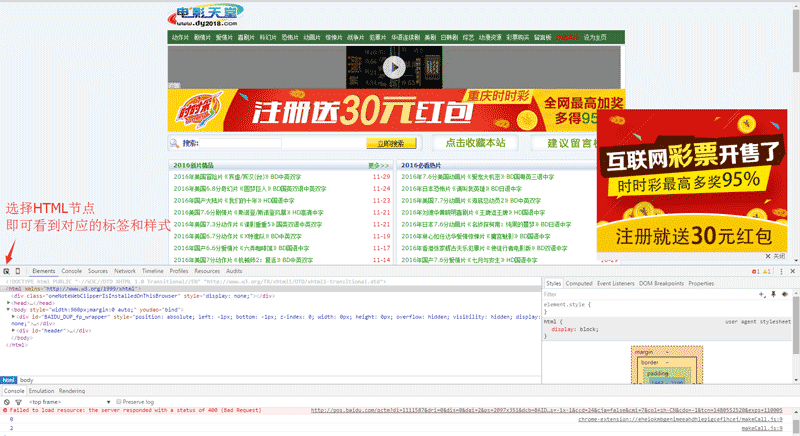
在chrome里面,按F12进入开发者模式,接着如下图使用鼠标选择对应页面数据,然后去分析页面HTML组成。
接着我们开始分析页面数据:
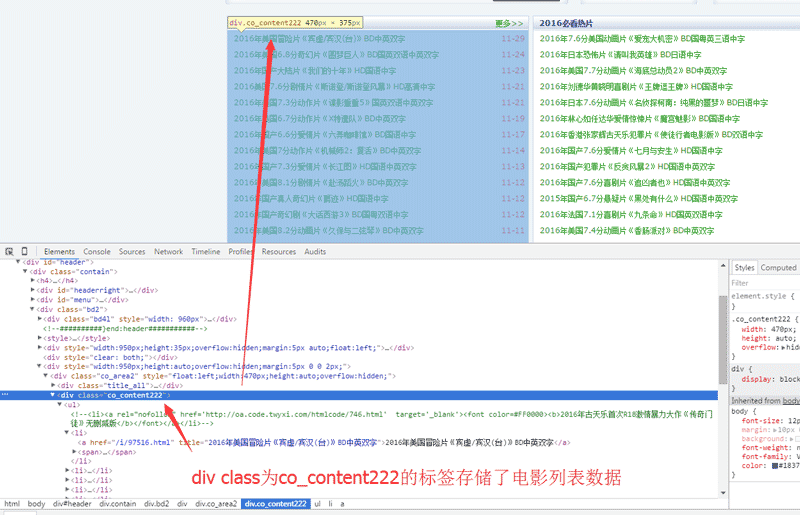
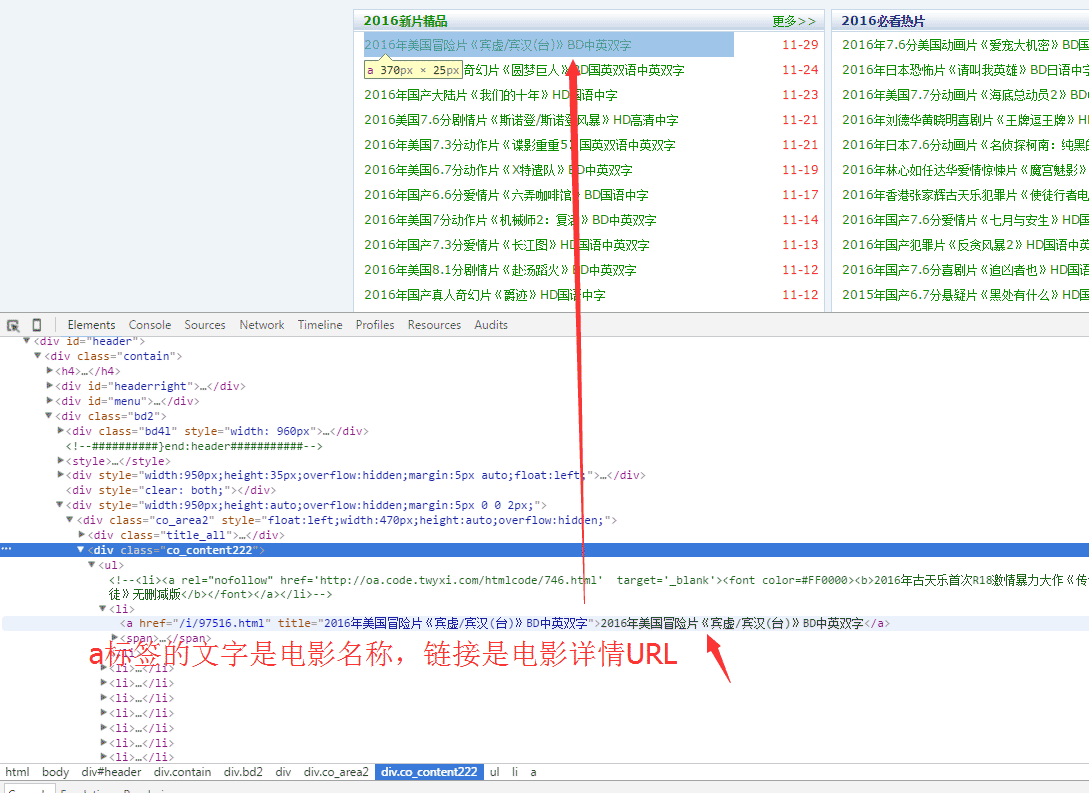
经过简单分析HTML,我们得到以下结论:
www.dy2018.com首页的电影数据存储在一个class为co_content222的div标签里面
电影详情链接为a标签,标签显示文本就是电影名称,URL即详情URL
那么总结下来,我们的工作就是:找到class='co_content222' 的div标签,从里面提取所有的a标签数据。
开始写代码…
之前在写做项目的时候用到过AngleSharp库,一个基于.NET(C#)开发的专门为解析xHTML源码的DLL组件。
AngleSharp主页在这里: https://anglesharp.github.io/ ,
详细介绍:http://www.jb51.net/article/99082.htm
Nuget地址: Nuget AngleSharp 安装命令:Install-Package AngleSharp
获取电影列表数据
private static HtmlParser htmlParser = new HtmlParser();
private ConcurrentDictionary<string, MovieInfo> _cdMovieInfo = new ConcurrentDictionary<string, MovieInfo>();
privatevoidAddToHotMovieList()
{
//此操作不阻塞当前其他操作,所以使用Task
// _cdMovieInfo 为线程安全字典,存储了当期所有的电影数据
Task.Factory.StartNew(()=>
{
try
{
//通过URL获取HTML
var htmlDoc = HTTPHelper.GetHTMLByURL("http://www.dy2018.com/");
//HTML 解析成 IDocument
var dom = htmlParser.Parse(htmlDoc);
//从dom中提取所有class='co_content222'的div标签
//QuerySelectorAll方法接受 选择器语法
var lstDivInfo = dom.QuerySelectorAll("div.co_content222");
if (lstDivInfo != null)
{
//前三个DIV为新电影
foreach (var divInfo in lstDivInfo.Take(3))
{
//获取div中所有的a标签且a标签中含有"/i/"的
//Contains("/i/") 条件的过滤是因为在测试中发现这一块div中的a标签有可能是广告链接
divInfo.QuerySelectorAll("a").Where(a =>
a.GetAttribute("href").Contains("/i/"))
.ToList().ForEach(
a =>
{
//拼接成完整链接
var onlineURL = "http://www.dy2018.com" + a.GetAttribute("href");
//看一下是否已经存在于现有数据中
if (!_cdMovieInfo.ContainsKey(onlineURL))
{
//获取电影的详细信息
MovieInfo movieInfo = FillMovieInfoFormWeb(a, onlineURL);
//下载链接不为空才添加到现有数据
if (movieInfo.XunLeiDownLoadURLList != null
&& movieInfo.XunLeiDownLoadURLList.Count != 0)
{
_cdMovieInfo.TryAdd
(movieInfo.Dy2018OnlineUrl,movieInfo);
}
}
});
}
}
}
catch(Exception ex)
{
}
});
}
获取电影详细信息
privateMovieInfoFillMovieInfoFormWeb(AngleSharp.Dom.IElement a,
string onlineURL)
{
var movieHTML = HTTPHelper.GetHTMLByURL(onlineURL);
var movieDoc = htmlParser.Parse(movieHTML);
//http://www.dy2018.com/i/97462.html 分析过程见上,不再赘述
//电影的详细介绍 在id为Zoom的标签中
var zoom = movieDoc.GetElementById("Zoom");
//下载链接在 bgcolor='#fdfddf'的td中,有可能有多个链接
var lstDownLoadURL = movieDoc.QuerySelectorAll("[bgcolor='#fdfddf']");
//发布时间 在class='updatetime'的span标签中
var updatetime = movieDoc.QuerySelector("span.updatetime");
var pubDate = DateTime.Now;
if(updatetime!=null && !string.IsNullOrEmpty(updatetime.InnerHtml))
{
//内容带有“发布时间:”字样,
//replace成""之后再去转换,转换失败不影响流程
DateTime.TryParse(updatetime.InnerHtml.Replace("发布时间:",
""), out pubDate);
}
var movieInfo = new MovieInfo()
{
//InnerHtml中可能还包含font标签,做多一个Replace
MovieName = a.InnerHtml.Replace("<font color=\"#0c9000\">","")
.Replace("<font color=\" #0c9000\">","")
.Replace("</font>", ""),
Dy2018OnlineUrl = onlineURL,
MovieIntro = zoom != null ? WebUtility.HtmlEncode(zoom.InnerHtml) : "暂无介绍...",
//可能没有简介,虽然好像不怎么可能
XunLeiDownLoadURLList = lstDownLoadURL != null ?
lstDownLoadURL.Select(d => d.FirstElementChild.InnerHtml).ToList() : null,
//可能没有下载链接
PubDate = pubDate,
};
return movieInfo;
}
HTTPHelper
这边有个小坑,dy2018网页编码格式是GB2312,.NET Core默认不支持GB2312,使用Encoding.GetEncoding(“GB2312”)的时候会抛出异常。
解决方案是手动安装System.Text.Encoding.CodePages包(Install-Package System.Text.Encoding.CodePages),
然后在Starup.cs的Configure方法中加入Encoding.RegisterProvider(CodePagesEncodingProvider.Instance),接着就可以正常使用Encoding.GetEncoding(“GB2312”)了。
using System;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
namespace Dy2018Crawler
{
public class HTTPHelper
{
public static HttpClient Client { get; } = new HttpClient();
publicstaticstringGetHTMLByURL(stringurl)
{
try
{
System.Net.WebRequest wRequest = System.Net.WebRequest.Create(url);
wRequest.ContentType = "text/html; charset=gb2312";
wRequest.Method = "get";
wRequest.UseDefaultCredentials = true;
// Get the response instance.
var task = wRequest.GetResponseAsync();
System.Net.WebResponse wResp = task.Result;
System.IO.Stream respStream = wResp.GetResponseStream();
//dy2018这个网站编码方式是GB2312,
using (System.IO.StreamReader reader =
new System.IO.StreamReader(respStream,
Encoding.GetEncoding("GB2312")))
{
return reader.ReadToEnd();
}
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
return string.Empty;
}
}
}
}
定时任务的实现
定时任务我这里使用的是 Pomelo.AspNetCore.TimedJob 。
Pomelo.AspNetCore.TimedJob是一个.NET Core实现的定时任务job库,支持毫秒级定时任务、从数据库读取定时配置、同步异步定时任务等功能。
由.NET Core社区大神兼前微软MVP AmamiyaYuuko (入职微软之后就卸任MVP…)开发维护,不过好像没有开源,回头问下看看能不能开源掉。
nuget上有各种版本,按需自取。地址: https://www.nuget.org/packages/Pomelo.AspNetCore.TimedJob/1.1.0-rtm-10026
作者自己的介绍文章: Timed Job - Pomelo扩展包系列
Startup.cs相关代码
我这边使用的话,首先肯定是先安装对应的包:Install-Package Pomelo.AspNetCore.TimedJob -Pre
然后在Startup.cs的ConfigureServices函数里面添加Service,在Configure函数里面Use一下。
// This method gets called by the runtime. Use this method to add services to the container.
publicvoidConfigureServices(IServiceCollection services)
{
// Add framework services.
services.AddMvc();
//Add TimedJob services
services.AddTimedJob();
}
publicvoidConfigure(IApplicationBuilder app,
IHostingEnvironment env, ILoggerFactory loggerFactory)
{
//使用TimedJob
app.UseTimedJob();
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseBrowserLink();
}
else
{
app.UseExceptionHandler("/Home/Error");
}
app.UseStaticFiles();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "default",
template: "{controller=Home}/{action=Index}/{id?}");
});
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
}
Job相关代码
接着新建一个类,明明为XXXJob.cs,引用命名空间using Pomelo.AspNetCore.TimedJob,XXXJob继承于Job,添加以下代码。
public class AutoGetMovieListJob:Job
{
// Begin 起始时间;Interval执行时间间隔,单位是毫秒,建议使用以下格式,此处为3小时;
//SkipWhileExecuting是否等待上一个执行完成,true为等待;
[Invoke(Begin = "2016-11-29 22:10", Interval = 1000 * 3600*3, SkipWhileExecuting =true)]
publicvoidRun()
{
//Job要执行的逻辑代码
//LogHelper.Info("Start crawling");
//AddToLatestMovieList(100);
//AddToHotMovieList();
//LogHelper.Info("Finish crawling");
}
}
项目发布相关 新增runtimes节点
使用VS2015新建的模板工程,project.json配置默认是没有runtimes节点的.
我们想要发布到非Windows平台的时候,需要手动配置一下此节点以便生成。
"runtimes": {
"win7-x64": {},
"win7-x86": {},
"osx.10.10-x64": {},
"osx.10.11-x64": {},
"ubuntu.14.04-x64": {}
}
删除/注释scripts节点
生成时会调用node.js脚本构建前端代码,这个不能确保每个环境都有bower存在…注释完事。
//"scripts": {
// "prepublish": [ "bower install", "dotnet bundle" ],
// "postpublish": [ "dotnet publish-iis --publish-folder %publish:OutputPath% --framework %publish:FullTargetFramework%" ]
//},
删除/注释dependencies节点里面的type
"dependencies": {
"Microsoft.NETCore.App": {
"version": "1.1.0"
//"type": "platform"
},
project.json的相关配置说明可以看下这个官方文档: Project.json-file ,
或者张善友老师的文章 .NET Core系列 : 2 、project.json 这葫芦里卖的什么药
开发编译发布
//还原各种包文件 dotnet restore; //发布到C:\code\website\Dy2018Crawler文件夹 dotnet publish -r ubuntu.14.04-x64 -c Release -o "C:\code\website\Dy2018Crawler";
最后,照旧开源……以上代码都在下面找到:
Gayhub地址: https://github.com/liguobao/Dy2018Crawler
PS:回头写个爬片大家滋持不啊…
相关推荐
-

.NET Core Windows环境安装配置教程
1.安装.NET Core SDK 在windows下开发.NET Core最好使用Visual Studio工具.下载地址与安装: VS2015最新版本:Visual Studio 2015 Update 3* VS环境下的.Net Core:.NET Core 1.0 for Visual Studio 对应下载的文件DotNetCore.1.0.0-VS2015Tools.Preview2.exe .Net Core安装过程(安装过程比较慢,亲们耐心等待): (安装慢,等待中--.) (O
-
win10下ASP.NET Core部署环境搭建步骤
随着ASP.NET Core 1.0 rtm的发布,网上有许多相关.net core 相关文章,今刚好有时间也在win10环境上搭建下 ASP.NET Core的部署环境,把过程记录下给大家. 1. 开发运行环境 1> Visual Studio 2015 Update 3* 2> .NET Core 1.0 for Visual Studio (包括asp.net core 模板,其中如果机器上没有.net core sdk会默认安装)地址https://go.microsoft.com/f
-
简单谈谈.NET Core跨平台开发
对于.NET开源计划想必关注的人已经跃跃欲试了,但是真正将其用于开发的目前来说不多.毕竟截至本文发布时.NET Core才发布到1.0RC2版本.正式版预计还有一段时间.况且大多数人都是持观望态度,就算开发仍然用的还是.NET Framework.另外不得不说的一点就是.NET开源的进度很惊人但是社区建设还有待提升,很多配套的东西还不齐全.Java在语言层级上可能落后.NET但是Java的社区力量是.NET远不及的. 一.安装SDK .NET Core发布版:https://www.micros
-
Visual Studio 2015和 .NET Core安装教程
安装 Visual Studio 和 .NET Core 1.安装 Visual Studio Community 2015,选择 Community 下载并执行默认安装,Visual Studio 2015 安装程序首页 2.安装.NET Core + Visual Studio 工具,windows系统的可以从这里下载 创建 Web 应用程序 1.起始页 点击 新建项目(或 文件→新建→项目) 2.选择 左侧 .NET Core (如果没有安装.NET Core + Visual Studi
-
用.NET Core写爬虫爬取电影天堂
自从上一个项目从.NET迁移到.NET core之后,磕磕碰碰磨蹭了一个月才正式上线到新版本. 然后最近又开了个新坑,搞了个爬虫用来爬dy2018电影天堂上面的电影资源.这里也借机简单介绍一下如何基于.NET Core写一个爬虫. PS:如有偏错,敬请指明- PPS:该去电影院还是多去电影院,毕竟美人良时可无价. 准备工作(.NET Core准备) 首先,肯定是先安装.NET Core咯.下载及安装教程在这里: http://www.jb51.net/article/87907.htm http
-
使用Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. 先来简单介绍一下,网络爬虫的基本实现原理吧.一个爬虫首先要给它一个起点,所以需要精心选取一些URL作为起点,然后我们的爬虫从这些起点出发,抓取并解析所抓取到的页面,将所需要的信息提取出来,同时获得的新的URL插入到队列中作为下一次爬取的起点.这样不断地循环,一直到获得你想得到的所有的信息爬虫的任务
-
Python爬虫爬取电影票房数据及图表展示操作示例
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作.分享给大家供大家参考,具体如下: 爬虫电影历史票房排行榜 http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0 Python爬取历史电影票房纪录 解析Json数据 横向条形图展示 面向对象思想 导入相关库 import requests import re from matplotlib import pyplot as plt from matplotlib import font
-
python使用requests模块实现爬取电影天堂最新电影信息
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到.可以说,Requests 完全满足如今网络的需求.本文重点给大家介绍python使用requests模块实现爬取电影天堂最新电影信息,具体内容如下所示: 在抓取网络数据的时候,有时会用正则对结构化的数据进行提取,比如 href="https://www.1234.com"等.python的re模块的findall()函数会返回一个所有匹配到的内容的列表,在将数据存入数据库时,列表数据
-
node+experss实现爬取电影天堂爬虫
上周写了一个node+experss的爬虫小入门.今天继续来学习一下,写一个爬虫2.0版本. 这次我们不再爬博客园了,咋玩点新的,爬爬电影天堂.因为每个周末都会在电影天堂下载一部电影来看看. talk is cheap,show me the code! 抓取页面分析 我们的目标: 1.抓取电影天堂首页,获取左侧最新电影的169条链接 2.抓取169部新电影的迅雷下载链接,并且并发异步抓取. 具体分析如下: 1.我们不需要抓取迅雷的所有东西,只需要下载最新发布的电影即可,比如下面的左侧栏.一共有
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
Python爬虫爬取爱奇艺电影片库首页的实例代码
上篇文章给大家介绍了Python爬取爱奇艺电影信息代码实例 感兴趣的朋友点击查看下. 今天给大家介绍Python爬虫爬取爱奇艺电影片库首页,下面是实例代码,参考下: import time import traceback import requests from lxml import etree import re from bs4 import BeautifulSoup from lxml.html.diff import end_tag import json import pymys
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能