写一个Python脚本下载哔哩哔哩舞蹈区的所有视频
一、抓取列表
首先点开舞蹈区先选择宅舞列表。
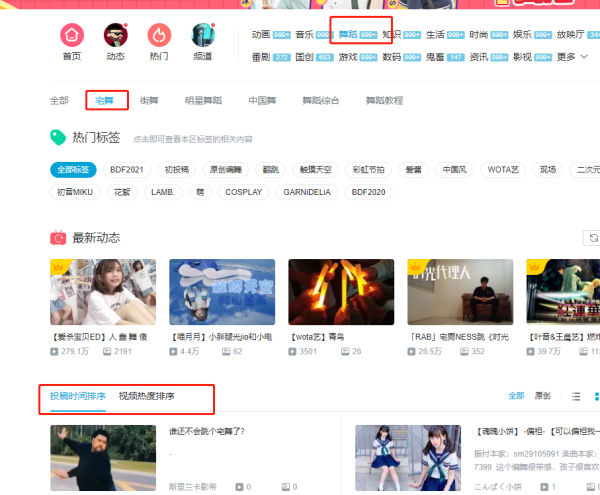
然后打开 F12 的控制面板,可以找到一条 https://api.bilibili.com/x/web-interface/newlist?rid=20&type=0&pn=1&ps=20&jsonp=jsonp&callback=jsonCallback_bili_57905715749828263 的 url,其中 rid 是 B 站的小分类,pn 是页数。
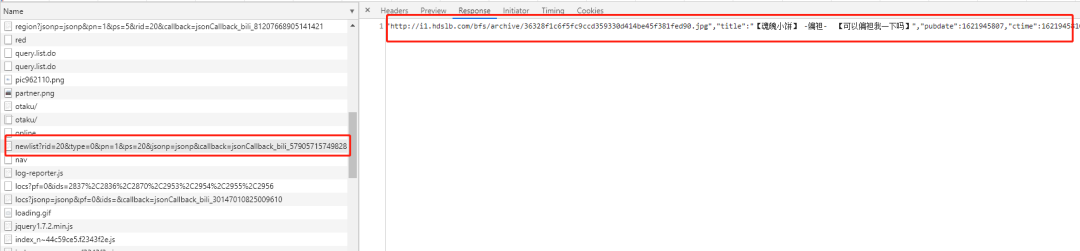
小编试着在浏览器将地址打开居然报了 404,可是在控制面板中这个地址的返回值明明就是视频列表。试着去掉 callback 的参数,意外的得到了想要的结果。

众所周知 bid 是一个 B 站视频的唯一 ID,想要获取 bid 可以从上面 url 的返回值中提取 aid,然后将 aid 转换为 bid。
Str = 'fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF' # 准备的一串指定字符串
Dict = {}
# 将字符串的每一个字符放入字典一一对应 , 如 f对应0 Z对应1 一次类推。
for i in range(58):
Dict[Str[i]] = i
s = [11, 10, 3, 8, 4, 6, 2, 9, 5, 7] # 必要的解密列表
xor = 177451812
add = 100618342136696320 # 这串数字最后要被减去或加上
def algorithm_enc(av):
ret = av
av = int(av)
av = (av ^ xor) + add
# 将BV号的格式(BV + 10个字符) 转化成列表方便后面的操作
r = list('BV ')
for i in range(10):
r[s[i]] = Str[av // 58 ** i % 58]
return ''.join(r)
def find_bid(p):
bids = []
r = requests.get(
'https://api.bilibili.com/x/web-interface/newlist?&rid=20&type=0&pn={}&ps=50&jsonp=jsonp'.format(p))
data = json.loads(r.text)
archives = data['data']['archives']
for item in archives:
aid = item['aid']
bid = algorithm_enc(aid)
bids.append(bid)
return bids
二、获取视频的 CID
想要下载 1080 的视频,光有 bid 是不够的,还需要 登录后 Cookie 中的 SESSDATA 值和 cid 。
首先登录 B 站将 Cookie 中的 SESSDATA 复制到对象头中。用地址为 https://api.bilibili.com/x/player/pagelist?bvid= url 返回 cid。
def get_cid(bid):
url = 'https://api.bilibili.com/x/player/pagelist?bvid=' + bid
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Cookie': 'SESSDATA=182cd036%2C1636985829%2C3b393%2A51',
'Host': 'api.bilibili.com'
}
html = requests.get(url, headers=headers).json()
infos = []
data = html['data']
cid_list = data
for item in cid_list:
cid = item['cid']
title = item['part']
infos.append({'bid': bid, 'cid': cid, 'title': title})
return infos
三、下载视频
下载视频的 https://api.bilibili.com/x/player/playurl 来自于每次视频播放完之后的推荐列表。

最后使用 urllib.request.urlretrieve 函数下载视频。
def get_video_list(aid, cid, quality):
url_api = 'https://api.bilibili.com/x/player/playurl?cid={}&bvid={}&qn={}'.format(cid, aid, quality)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Cookie': 'SESSDATA=182cd036%2C1636985829%2C3b393%2A51',
'Host': 'api.bilibili.com'
}
html = requests.get(url_api, headers=headers).json()
video_list = []
for i in html['data']['durl']:
video_list.append(i['url'])
return video_list
def schedule_cmd(blocknum, blocksize, totalsize):
percent = 100.0 * blocknum * blocksize/ totalsize
s = ('#' * round(percent)).ljust(100, '-')
sys.stdout.write('%.2f%%' % percent + '[' + s + ']' + '\r')
sys.stdout.flush()
def download(video_list, title, bid):
for i in video_list:
opener = urllib.request.build_opener()
opener.addheaders = [
('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'),
('Accept', '*/*'),
('Accept-Language', 'en-US,en;q=0.5'),
('Accept-Encoding', 'gzip, deflate, br'),
('Range', 'bytes=0-'),
('Referer', 'https://www.bilibili.com/video/'+bid),
('Origin', 'https://www.bilibili.com'),
('Connection', 'keep-alive'),
]
filename=os.path.join('D:\\video', r'{}_{}.mp4'.format(bid,title))
try:
urllib.request.install_opener(opener)
urllib.request.urlretrieve(url=i, filename=filename, reporthook=schedule_cmd)
except:
print(bid + "下载异常,文件:" + filename)
到此这篇关于写一个Python脚本下载哔哩哔哩舞蹈区的所有视频的文章就介绍到这了,更多相关python下载哔哩哔哩视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python基于tkinter制作m3u8视频下载工具
这是我为了学习tkinter用python 写的一个下载m3u8视频的小程序,程序使用了多线程下载,下载后自动合并成一个视频文件,方便播放. 目前的众多视频都是m3u8的播放类型,只要知道视频的m3u8地址,就可以完美下载整个视频. m3u8地址获取 打开浏览器,点开你要获取地址的视频 重要的来了,右键>>审查元素或者按F12也可以 根据开发或测试的实际环境选择相应的设备,选择iphone6 plus 选择好了以后,刷新页面,点击漏斗,选择media,一定刷新之后再点击,没出来的话切换几下选项
-
教你用Python下载抖音无水印视频
一.获取抖音视频连接 得到如下信息: "5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.douyin.com/eDFd28P/ 复制此链接,打开Dou音搜索,直接观看视频!" 通过正则取到信息中的地址: share_url='5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.douyin.com/eDFd28P/
-
python b站视频下载的五种版本
项目地址: https://github.com/Henryhaohao/Bilibili_video_download 介绍 对于单P视频:直接传入B站av号或者视频链接地址(eg: 49842011或者https://www.bilibili.com/video/av49842011) 对于多P视频: 1.下载全集:直接传入B站av号或者视频链接地址(eg: 49842011或者https://www.bilibili.com/video/av49842011) 2.下载其中一集:传入那一集
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的
-
教你如何使用Python下载B站视频的详细教程
前言 众所周知,网页版的B站无法下载视频,然本人喜欢经常在B站学习,奈何没有网时,无法观看视频资源,手机下载后屏幕太小又不想看,遂写此程序以解决此问题 步骤 话不多说,进入正题 1.在电脑上下载python的开发环境,点一下,观看具体步骤 2.下载pycharm开发工具,点一下观看具体步骤 3.同时按键盘上的win键与r键,在弹出的对话框中输入cmd 点击确定进入cmd命令行,在里面输入pip install you-get,之后按键盘enter键,进行you-get的下载,下载完后退出cmd
-
Python通过m3u8文件下载合并ts视频的操作
前段时间,接到一个需求,要求下载某一个网站的视频,然后自己从网上查阅了相关的资料,在这里做一个总结. 1. m3u8文件 m3u8是苹果公司推出一种视频播放标准,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求,是现在比较流行的一种加载方式.目前,很多新闻视频网站都是采用这种模式去加载视频. M3U8文件是指UTF-8编码格式的M3U文件.M3U文件是记录了一个索引纯文本
-
用python制作个视频下载器
前言 某个夜深人静的夜晚,夜微凉风微扬,月光照进我的书房~ 当我打开文件夹以回顾往事之余,惊现许多看似杂乱的无聊代码.我拍腿正坐,一个想法油然而生:"生活已然很无聊,不如再无聊些叭". 于是,我决定开一个专题,便称之为kimol君的无聊小发明. 妙-啊~~~ 众所周知,视频是一个学习新姿势知识的良好媒介.那么,如何利用爬虫更加方便快捷地下载视频呢?本文将从数据包分析到代码实现来进行一个相对完整的讲解. 一.爬虫分析 本次选取的目标视频网站为某度旗下的好看视频: https://haok
-
利用python 下载bilibili视频
运行效果: 完整代码 # !/usr/bin/python # -*- coding:utf-8 -*- # time: 2019/07/21--20:12 __author__ = 'Henry' ''' 项目: B站动漫番剧(bangumi)下载 版本2: 无加密API版,但是需要加入登录后cookie中的SESSDATA字段,才可下载720p及以上视频 API: 1.获取cid的api为 https://api.bilibili.com/x/web-interface/view?aid=4
-
python gui开发——制作抖音无水印视频下载工具(附源码)
hello,大家好啊,失踪人口回归了 [捂脸]!本次使用tkinter撰写一篇 抖音无水印视频下载,目的很纯粹,就是为了设置 微信状态视频.本篇博文中,我会写下我的代码撰写思路以及想写设计流程,代码放在了第四节,工具打包好放在了 蓝奏云,慢慢看,后面有链接. 一.准备工作 本次要用到以下依赖库:re json os random tkinter threading requests pillow 其中后两个需要安装后使用 二.预览 0.复制抖音分享短链接 1.启动 2.运行 3.结果 (小姐姐挺
-
写一个Python脚本下载哔哩哔哩舞蹈区的所有视频
一.抓取列表 首先点开舞蹈区先选择宅舞列表. 然后打开 F12 的控制面板,可以找到一条 https://api.bilibili.com/x/web-interface/newlist?rid=20&type=0&pn=1&ps=20&jsonp=jsonp&callback=jsonCallback_bili_57905715749828263 的 url,其中 rid 是 B 站的小分类,pn 是页数. 小编试着在浏览器将地址打开居然报了 404,可是在控制面
-
写一个Python脚本自动爬取Bilibili小视频
我身边的很多小伙伴们在朋友圈里面晒着出去游玩的照片,简直了,人多的不要不要的,长城被堵到水泄不通,老实人想想啊,既然人这么多,哪都不去也是件好事,没事还可以刷刷 B 站 23333 .这时候老实人也有了一个大胆地想法,能不能让这些在旅游景点排队的小伙伴们更快地打发时间呢?考虑到视频的娱乐性和大众观看量,我决定对 B 站新推出的小视频功能下手,于是我跑到B站去找API接口,果不起然,B站在小视频功能处提供了 API 接口,小伙伴们有福了哟! B 站小视频网址在这里哦: http://vc.bili
-
利用python为运维人员写一个监控脚本
前言: 一直想写一个监控方面的脚本,然后想到了运维这方面的,后来就写了个脚本,下面话不多说了,来一起看看详细的介绍吧. 准备: psutil模块(基本使用方法可以参考这篇文章:http://www.jb51.net/article/65044.htm) 正文: import os import time import re import smtplib from email.mime.text import MIMEText from email.header import Header imp
-
Windows下写一个文件备份脚本(专用备份的)
今天一个意外,我写的大半个月的日记加密文件受损,无法恢复.于是决定写一个专用备份的脚本文件. 主要思想就是在当前目录backup下根据当天的日期创建一个文件夹,然后将文件复制到该文件夹下. 脚本文件如下: 复制代码 代码如下: echo off echo ********开始备份日志文件******** set ymd=%date:~0,4%%date:~5,2%%date:~8,2% set backup-dir=backupnotebook-%ymd% echo 备份目录:%backup-d
-
如何使用七牛Python SDK写一个同步脚本及使用教程
七牛云存储的 Python 语言版本 SDK(本文以下称 Python-SDK)是对七牛云存储API协议的一层封装,以提供一套对于 Python 开发者而言简单易用的开发工具.Python 开发者在对接 Python-SDK 时无需理解七牛云存储 API 协议的细节,原则上也不需要对 HTTP 协议和原理做非常深入的了解,但如果拥有基础的 HTTP 知识,对于出错场景的处理可以更加高效. 最近刚搭了个markdown静态博客,想把图片放到云存储中. 经过调研觉得七牛可以满足我个人的需求,就选它了
-
手写一个python迭代器过程详解
分析 我们都知道一个可迭代对象可以通过iter()可以返回一个迭代器. 如果想要一个对象称为可迭代对象,即可以使用for,那么必须实现__iter __()方法. 在一个类的实例对象想要变成迭代器,就必须实现__iter__()和__next__()方法. 调用iter()时,在对象内部默认调用__iter__(),即__iter__()的返回值应该是一个迭代器. for的每次循环中或者next()时,都是自动调用迭代器的__next__()方法,并有一个返回值. 实现 class Classm
-
写一个shell脚本实现视频处理
目录 需求 视频处理 ffmpeg 裁剪 格式转换 配置参数 sed命令 读取时间切片csv 转换视频格式 上传七牛 end 需求 去年同事准备做个公司内部的大讲堂网站,将一些内部培训的视频汇总,提供给公司同事观看,网站搭建相对来说比较简单,直接用Ant.design Pro+Eggjs实现.但是为了体验更好一些,我们准备将视频,根据内容进行切割,方便用户快速找到自己感兴趣的内容,同时转成m3u8上传cdn,优化视频播放和缓冲的速度. 这就涉及到了视频切割和格式转换,传统的做法是通过视频剪辑软件
-
使用Python脚本对Linux服务器进行监控的教程
目前 Linux 下有一些使用 Python 语言编写的 Linux 系统监控工具 比如 inotify-sync(文件系统安全监控软件).glances(资源监控工具)在实际工作中,Linux 系统管理员可以根据自己使用的服务器的具体情况编写一下简单实用的脚本实现对 Linux 服务器的监控. 本文介绍一下使用 Python 脚本实现对 Linux 服务器 CPU 内存 网络的监控脚本的编写. Python 版本说明 Python 是由 Guido van Rossum 开发的.可免费获得的.
-
Python脚本实现下载合并SAE日志
由于一些原因,需要SAE上站点的日志文件,从SAE上只能按天下载,下载下来手动处理比较蛋疼,尤其是数量很大的时候.还好SAE提供了API可以批量获得日志文件下载地址,刚刚写了python脚本自动下载和合并这些文件 调用API获得下载地址 文档位置在这里 设置自己的应用和下载参数 请求中需要设置的变量如下 复制代码 代码如下: api_url = 'http://dloadcenter.sae.sina.com.cn/interapi.php?' appname = 'xxxxx' from_da
-
用shell写一个mysql数据备份脚本
思路 其实很简单 写一个shell脚本通过mysql的mysqldump,将数据导出成对应的sql文件:使用linux的crontab定时运行对应脚本,将sql,文件保存到对应的目录下:可想而知,随着数据量的增加和备份的频率都会导致备份服务器的硬盘资源使用率也会直线攀升:为了解决这个问题,我们就需要,定时清理备份内容:而我还是简单的使用了个shell脚本,通过crontab定时去清理: 注意 这里有几个问题需要注意的: 通过mysqldump来导出对应的库表的sql,这样必然会造成mysql服务