pytorch交叉熵损失函数的weight参数的使用
首先
必须将权重也转为Tensor的cuda格式;
然后
将该class_weight作为交叉熵函数对应参数的输入值。
class_weight = torch.FloatTensor([0.13859937, 0.5821059, 0.63871904, 2.30220396, 7.1588294, 0]).cuda()
补充:关于pytorch的CrossEntropyLoss的weight参数
首先这个weight参数比想象中的要考虑的多
你可以试试下面代码
import torch import torch.nn as nn inputs = torch.FloatTensor([0,1,0,0,0,1]) outputs = torch.LongTensor([0,1]) inputs = inputs.view((1,3,2)) outputs = outputs.view((1,2)) weight_CE = torch.FloatTensor([1,1,1]) ce = nn.CrossEntropyLoss(ignore_index=255,weight=weight_CE) loss = ce(inputs,outputs) print(loss)
tensor(1.4803)
这里的手动计算是:
loss1 = 0 + ln(e0 + e0 + e0) = 1.098
loss2 = 0 + ln(e1 + e0 + e1) = 1.86
求平均 = (loss1 *1 + loss2 *1)/ 2 = 1.4803
加权呢?
import torch import torch.nn as nn inputs = torch.FloatTensor([0,1,0,0,0,1]) outputs = torch.LongTensor([0,1]) inputs = inputs.view((1,3,2)) outputs = outputs.view((1,2)) weight_CE = torch.FloatTensor([1,2,3]) ce = nn.CrossEntropyLoss(ignore_index=255,weight=weight_CE) loss = ce(inputs,outputs) print(loss)
tensor(1.6075)
手算发现,并不是单纯的那权重相乘:
loss1 = 0 + ln(e0 + e0 + e0) = 1.098
loss2 = 0 + ln(e1 + e0 + e1) = 1.86
求平均 = (loss1 * 1 + loss2 * 2)/ 2 = 2.4113
而是
loss1 = 0 + ln(e0 + e0 + e0) = 1.098
loss2 = 0 + ln(e1 + e0 + e1) = 1.86
求平均 = (loss1 *1 + loss2 *2) / 3 = 1.6075
发现了么,加权后,除以的是权重的和,不是数目的和。
我们再验证一遍:
import torch import torch.nn as nn inputs = torch.FloatTensor([0,1,2,0,0,0,0,0,0,1,0,0.5]) outputs = torch.LongTensor([0,1,2,2]) inputs = inputs.view((1,3,4)) outputs = outputs.view((1,4)) weight_CE = torch.FloatTensor([1,2,3]) ce = nn.CrossEntropyLoss(weight=weight_CE) # ce = nn.CrossEntropyLoss(ignore_index=255) loss = ce(inputs,outputs) print(loss)
tensor(1.5472)
手算:
loss1 = 0 + ln(e0 + e0 + e0) = 1.098
loss2 = 0 + ln(e1 + e0 + e1) = 1.86
loss3 = 0 + ln(e2 + e0 + e0) = 2.2395
loss4 = -0.5 + ln(e0.5 + e0 + e0) = 0.7943
求平均 = (loss1 * 1 + loss2 * 2+loss3 * 3+loss4 * 3) / 9 = 1.5472
可能有人对loss的CE计算过程有疑问,我这里细致写写交叉熵的计算过程,就拿最后一个例子的loss4的计算说明
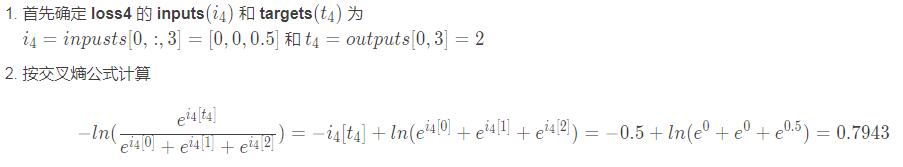
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果.这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文. 测试代码(一维) import torch import torch.nn as nn import math criterion = nn.CrossEntropyLoss() output = torch.randn(1, 5, requires_grad=True) label = tor
-
PyTorch的SoftMax交叉熵损失和梯度用法
在PyTorch中可以方便的验证SoftMax交叉熵损失和对输入梯度的计算 关于softmax_cross_entropy求导的过程,可以参考HERE 示例: # -*- coding: utf-8 -*- import torch import torch.autograd as autograd from torch.autograd import Variable import torch.nn.functional as F import torch.nn as nn import nu
-
pytorch查看模型weight与grad方式
在用pdb debug的时候,有时候需要看一下特定layer的权重以及相应的梯度信息,如何查看呢? 1. 首先把你的模型打印出来,像这样 2. 然后观察到model下面有module的key,module下面有features的key, features下面有(0)的key,这样就可以直接打印出weight了,在pdb debug界面输入p model.module.features[0].weight,就可以看到weight,输入 p model.module.features[0].weig
-
解决pytorch 交叉熵损失输出为负数的问题
网络训练中,loss曲线非常奇怪 交叉熵怎么会有负数. 经过排查,交叉熵不是有个负对数吗,当网络输出的概率是0-1时,正数.可当网络输出大于1的数,就有可能变成负数. 所以加上一行就行了 out1 = F.softmax(out1, dim=1) 补充知识:在pytorch框架下,训练model过程中,loss=nan问题时该怎么解决? 当我在UCF-101数据集训练alexnet时,epoch设为100,跑到三十多个epoch时,出现了loss=nan问题,当时是一脸懵逼,在查阅资料后,我通过
-
pytorch中的weight-initilzation用法
pytorch中的权值初始化 官方论坛对weight-initilzation的讨论 torch.nn.Module.apply(fn) torch.nn.Module.apply(fn) # 递归的调用weights_init函数,遍历nn.Module的submodule作为参数 # 常用来对模型的参数进行初始化 # fn是对参数进行初始化的函数的句柄,fn以nn.Module或者自己定义的nn.Module的子类作为参数 # fn (Module -> None) – function t
-
pytorch 网络参数 weight bias 初始化详解
权重初始化对于训练神经网络至关重要,好的初始化权重可以有效的避免梯度消失等问题的发生. 在pytorch的使用过程中有几种权重初始化的方法供大家参考. 注意:第一种方法不推荐.尽量使用后两种方法. # not recommend def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) elif classname.
-

pytorch交叉熵损失函数的weight参数的使用
首先 必须将权重也转为Tensor的cuda格式: 然后 将该class_weight作为交叉熵函数对应参数的输入值. class_weight = torch.FloatTensor([0.13859937, 0.5821059, 0.63871904, 2.30220396, 7.1588294, 0]).cuda() 补充:关于pytorch的CrossEntropyLoss的weight参数 首先这个weight参数比想象中的要考虑的多 你可以试试下面代码 import torch im
-
Python机器学习pytorch交叉熵损失函数的深刻理解
目录 1.交叉熵损失函数的推导 2. 交叉熵损失函数的直观理解 3. 交叉熵损失函数的其它形式 4.总结 说起交叉熵损失函数「Cross Entropy Loss」,脑海中立马浮现出它的公式: 我们已经对这个交叉熵函数非常熟悉,大多数情况下都是直接拿来使用就好.但是它是怎么来的?为什么它能表征真实样本标签和预测概率之间的差值?上面的交叉熵函数是否有其它变种? 1.交叉熵损失函数的推导 我们知道,在二分类问题模型:例如逻辑回归「Logistic Regression」.神经网络「Neural Ne
-
基于KL散度、JS散度以及交叉熵的对比
在看论文<Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection>时,文中提到了这三种方法来比较时间序列中不同区域概率分布的差异. KL散度.JS散度和交叉熵 三者都是用来衡量两个概率分布之间的差异性的指标.不同之处在于它们的数学表达. 对于概率分布P(x)和Q(x) 1)KL散度(Kullback–Leibler divergence) 又称KL距离,相对熵. 当P(x)和Q(x)的相似度越高
-
pytorch 实现二分类交叉熵逆样本频率权重
通常,由于类别不均衡,需要使用weighted cross entropy loss平衡. def inverse_freq(label): """ 输入label [N,1,H,W],1是channel数目 """ den = label.sum() # 0 _,_,h,w= label.shape num = h*w alpha = den/num # 0 return torch.tensor([alpha, 1-alpha]).cuda(
-
PyTorch计算损失函数对模型参数的Hessian矩阵示例
目录 前言 模型定义 求解Hessian矩阵 前言 在实现Per-FedAvg的代码时,遇到如下问题: 可以发现,我们需要求损失函数对模型参数的Hessian矩阵. 模型定义 我们定义一个比较简单的模型: class ANN(nn.Module): def __init__(self): super(ANN, self).__init__() self.sigmoid = nn.Sigmoid() self.fc1 = nn.Linear(3, 4) self.fc2 = nn.Linear(4
-
关于pytorch中网络loss传播和参数更新的理解
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇. TensorFlow: 228--->266 Keras: 42--->56 Pytorch: 87--->252 在使用pytorch中,自己有一些思考,如下: 1. loss计算和反向传播 import torch.nn as nn
-
对pytorch的函数中的group参数的作用介绍
1.当设置group=1时: conv = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=1, groups=1) conv.weight.data.size() 返回: torch.Size([6, 6, 1, 1]) 另一个例子: conv = nn.Conv2d(in_channels=6, out_channels=3, kernel_size=1, groups=1) conv.weight.data.size() 返回: t