我对PyTorch dataloader里的shuffle=True的理解
对shuffle=True的理解:
之前不了解shuffle的实际效果,假设有数据a,b,c,d,不知道batch_size=2后打乱,具体是如下哪一种情况:
1.先按顺序取batch,对batch内打乱,即先取a,b,a,b进行打乱;
2.先打乱,再取batch。
证明是第二种
shuffle (bool, optional): set to ``True`` to have the data reshuffled
at every epoch (default: ``False``).
if shuffle:
sampler = RandomSampler(dataset) #此时得到的是索引
补充:简单测试一下pytorch dataloader里的shuffle=True是如何工作的
看代码吧~
import sys
import torch
import random
import argparse
import numpy as np
import pandas as pd
import torch.nn as nn
from torch.nn import functional as F
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
from torch.utils.data import TensorDataset, DataLoader, Dataset
class DealDataset(Dataset):
def __init__(self):
xy = np.loadtxt(open('./iris.csv','rb'), delimiter=',', dtype=np.float32)
#data = pd.read_csv("iris.csv",header=None)
#xy = data.values
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dealDataset = DealDataset()
train_loader2 = DataLoader(dataset=dealDataset,
batch_size=2,
shuffle=True)
#print(dealDataset.x_data)
for i, data in enumerate(train_loader2):
inputs, labels = data
#inputs, labels = Variable(inputs), Variable(labels)
print(inputs)
#print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())
简易数据集

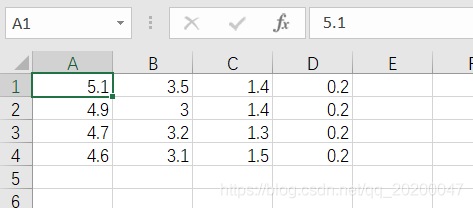
shuffle之后的结果,每次都是随机打乱,然后分成大小为n的若干个mini-batch.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
简述python&pytorch 随机种子的实现
随机数广泛应用在科学研究, 但是计算机无法产生真正的随机数, 一般成为伪随机数. 它的产生过程: 给定一个随机种子(一个正整数), 根据随机算法和种子产生随机序列. 给定相同的随机种子, 计算机产生的随机数列是一样的(这也许是伪随机的原因). 随机种子是什么? 随机种子是针对随机方法而言的. 随机方法:常见的随机方法有 生成随机数,以及其他的像 随机排序 之类的,后者本质上也是基于生成随机数来实现的.在深度学习中,比较常用的随机方法的应用有:网络的随机初始化,训练集的随机打乱等. 随机种子的取值
-

python PyTorch参数初始化和Finetune
前言 这篇文章算是论坛PyTorch Forums关于参数初始化和finetune的总结,也是我在写代码中用的算是"最佳实践"吧.最后希望大家没事多逛逛论坛,有很多高质量的回答. 参数初始化 参数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了data,grad等借口,这就意味着我们可以直接对这些参数进行操作赋值了.这就是PyTorch简洁高效所在. 所以我们可以进行如下操作进行初始化,当然其实有其他的方法,但是这种方法
-
Python深度学习之使用Pytorch搭建ShuffleNetv2
一.model.py 1.1 Channel Shuffle def channel_shuffle(x: Tensor, groups: int) -> Tensor: batch_size, num_channels, height, width = x.size() channels_per_group = num_channels // groups # reshape # [batch_size, num_channels, height, width] -> [batch_size
-
python、PyTorch图像读取与numpy转换实例
Tensor转为numpy np.array(Tensor) numpy转换为Tensor torch.Tensor(numpy.darray) PIL.Image.Image转换成numpy np.array(PIL.Image.Image) numpy 转换成PIL.Image.Image Image.fromarray(numpy.ndarray) 首先需要保证numpy.ndarray 转换成np.uint8型 numpy.astype(np.uint8),像素值[0,255]. 同时灰
-
pytorch 带batch的tensor类型图像显示操作
项目场景 pytorch训练时我们一般把数据集放到数据加载器里,然后分批拿出来训练.训练前我们一般还要看一下训练数据长啥样,也就是训练数据集可视化. 那么如何显示dataloader里面带batch的tensor类型的图像呢? 显示图像 绘图最常用的库就是matplotlib: pip install matplotlib 显示图像会用到matplotlib.pyplot.imshow方法.查阅官方文档可知,该方法接收的图像的通道数要放到后面: 数据加载器中数据的维度是[B, C, H, W],
-
python PyTorch预训练示例
前言 最近使用PyTorch感觉妙不可言,有种当初使用Keras的快感,而且速度还不慢.各种设计直接简洁,方便研究,比tensorflow的臃肿好多了.今天让我们来谈谈PyTorch的预训练,主要是自己写代码的经验以及论坛PyTorch Forums上的一些回答的总结整理. 直接加载预训练模型 如果我们使用的模型和原模型完全一样,那么我们可以直接加载别人训练好的模型: my_resnet = MyResNet(*args, **kwargs) my_resnet.load_state_dict(
-
python 如何查看pytorch版本
看代码吧~ import torch print(torch.__version__) 补充:pytorch不同版本安装以及版本查看 一:基于conda安装 conda create --name pytorch_learn python=3.6.7#创建一个名为pytorch_learn的环境 source activate pytorch_learn #进入环境 conda install pytorch=0.3.1 cuda80 -c soumith #安装pytorch0.3.1+ cu
-
浅谈pytorch、cuda、python的版本对齐问题
在使用深度学习模型训练的过程中,工具的准备也算是一个良好的开端吧.熟话说完事开头难,磨刀不误砍柴工,先把前期的问题搞通了,能为后期节省不少精力. 以pytorch工具为例: pytorch版本为1.0.1,自带python版本为3.6.2 服务器上GPU的CUDA_VERSION=9000 注意:由于GPU上的CUDA_VERSION为9000,所以至少要安装cuda版本>=9.0,虽然cuda=7.0~8.0也能跑,但是一开始可能会遇到各种各样的问题,本人cuda版本为10.0,安装cuda的
-
Pytorch使用shuffle打乱数据的操作
这个东西算是我被这个shuffle坑了的一个总结吧! 首先我得告诉你一件事,那就是pytorch中的tensor,如果直接使用random.shuffle打乱数据,或者使用下面的方式,自己定义直接写. def Shuffle(self, x, y,random=None, int=int): if random is None: random = self.random for i in range(len(x)): j = int(random() * (i + 1)) if j<=len(x
-
Python深度学习之Pytorch初步使用
一.Tensor Tensor(张量是一个统称,其中包括很多类型): 0阶张量:标量.常数.0-D Tensor:1阶张量:向量.1-D Tensor:2阶张量:矩阵.2-D Tensor:-- 二.Pytorch如何创建张量 2.1 创建张量 import torch t = torch.Tensor([1, 2, 3]) print(t) 2.2 tensor与ndarray的关系 两者之间可以相互转化 import torch import numpy as np t1 = np.arra
-
基于python及pytorch中乘法的使用详解
numpy中的乘法 A = np.array([[1, 2, 3], [2, 3, 4]]) B = np.array([[1, 0, 1], [2, 1, -1]]) C = np.array([[1, 0], [0, 1], [-1, 0]]) A * B : # 对应位置相乘 np.array([[ 1, 0, 3], [ 4, 3, -4]]) A.dot(B) : # 矩阵乘法 ValueError: shapes (2,3) and (2,3) not aligned: 3 (dim