Python数据分析之pandas比较操作
一、比较运算符和比较方法
比较运算符用于判断是否相等和比较大小,Python中的比较运算符有==、!=、<、>、<=、>=六个,Pandas中也一样。
在Pandas中,DataFrame和Series还支持6个比较方法,详见下表。
| 方法 | 英文全称 | 用途 |
| eq | equal to | 等于 |
| ne | not equal to | 不等于 |
| lt | less than | 小于 |
| gt | greater than | 大于 |
| le | less than or equal to | 小于等于 |
| ge | greater than or equal to | 大于等于 |
对于比较操作,==和!=支持各种类型的数据互相比较,而<、>、<=、>=对数据类型有限制,如整数可以与浮点数比较大小,但整数不能与字符串比较大小,会报错。这一点,适用于后面的所有比较。
二、两个DataFrame比较
1. 用算术运算符比较

两个DataFrame进行比较,是将DataFrame中对应位置的数据进行比较。
使用比较运算符,两个DataFrame的形状必须相同,索引必须相等(索引顺序必须相同),否则会报错。
2. 用比较方法比较

直接用DataFrame调用比较方法,传入另一个DataFrame,即可完成比较操作。
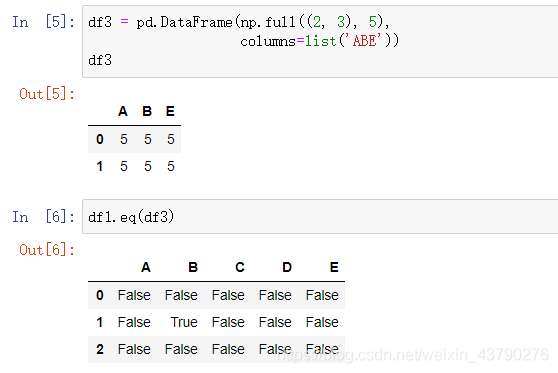
使用比较方法时,两个DataFrame的形状可以不相同,索引也可以不相同。结果是能兼容两个被比较DataFrame的新DataFrame,原理如下图。

三、两个Series比较
1. 用算术运算符比较
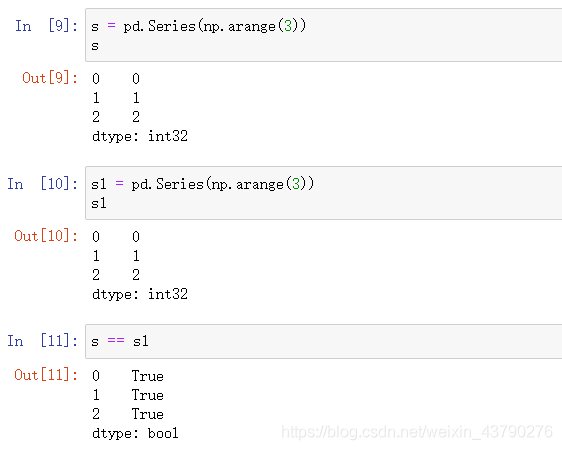
使用比较运算符,两个Series的长度必须相同,索引必须相等(索引顺序必须相同),否则会报错。
2. 用比较方法比较

使用比较方法,两个Series的长度可以不相同,索引也可以不相同。结果是能兼容两个被比较Series的新Series,原理同DataFrame。
四、与数字或字符串比较
1. DataFrame与数字比较

用DataFrame中的每个数据都与数字进行比较,返回对应位置的布尔值,Series同理。比较方法和运算符作用相同。
2. DataFrame与字符串比较

将每个数据都与指定的字符串进行比较,Series同理。比较方法和运算符作用相同。
用多维数据与单个数据进行比较时,要注意数据的类型,如果有不支持的比较,会报错。
五、与array进行比较
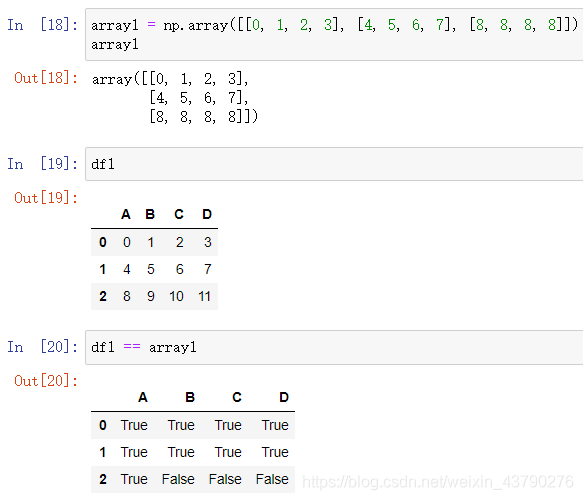
比较操作还支持DataFrame或Series与numpy中的array数据进行比较。array没有索引,所以对索引没有要求,但形状必须相同,否则会报错。比较方法和运算符作用相同。
到此这篇关于Python数据分析之pandas比较操作的文章就介绍到这了,更多相关Python pandas比较操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析之pandas比较操作
一.比较运算符和比较方法 比较运算符用于判断是否相等和比较大小,Python中的比较运算符有==.!=.<.>.<=.>=六个,Pandas中也一样. 在Pandas中,DataFrame和Series还支持6个比较方法,详见下表. 方法 英文全称 用途 eq equal to 等于 ne not equal to 不等于 lt less than 小于 gt greater than 大于 le less than or equal to 小于等于 ge greater than
-
Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa
-
Python数据分析之 Pandas Dataframe修改和删除及查询操作
目录 一.查询操作 元素的查询 二.修改操作 行列索引的修改 元素值的修改 三.行和列的删除操作 一.查询操作 可以使用Dataframe的index属性和columns属性获取行.列索引. import pandas as pd data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], &q
-
Python数据分析模块pandas用法详解
本文实例讲述了Python数据分析模块pandas用法.分享给大家供大家参考,具体如下: 一 介绍 pandas(Python Data Analysis Library)是基于numpy的数据分析模块,提供了大量标准数据模型和高效操作大型数据集所需要的工具,可以说pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一. pandas主要提供了3种数据结构: 1)Series,带标签的一维数组. 2)DataFrame,带标签且大小可变的二维表格结构. 3)Panel,带标
-
Python数据分析库pandas基本操作方法
pandas是什么? 是它吗? ....很显然pandas没有这个家伙那么可爱.... 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language. 很显然,pandas是python的一个非常强大的数据分析库! 让我们来学习一下它吧! 1.pandas序列 import nump
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
Python数据分析之pandas函数详解
一.apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) print(df) print(np.abs(df)) 运行结果: 0 1 2 3 0 -0.062413 0.844813 -1.853721 -1.980717 1 -0.539628 -1.975173 -0.856597 -2.612406
-
Python数据分析之 Pandas Dataframe应用自定义
目录 前言: 应用函数 apply 方法 applymap 方法 前言: 在进行数据分析时,难免需要对数据集应用一些我们自定义的一些函数,或者其他库的函数,得到我们想要的数据,这种情况下,可能大家第一时间想到的是使用for循环遍历Dataframe对象,取到指定行/列的数据再进行自定义函数的应用,当然这种方法完全可以实现,但是效率不高,接下来就来介绍一下在Pandas中如何对数据集高效的进行自定义函数的应用. 应用函数 apply 方法 apply()函数是一个自定义函数作用于某一行或几行,或者
-
Python数据分析之pandas读取数据
一.三种数据文件的读取 二.csv.tsv.txt 文件读取 1)CSV文件读取: 语法格式:pandas.read_csv(文件路径) CSV文件内容如下: import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回
-
Python数据分析之 Pandas Dataframe条件筛选遍历详情
目录 一.条件筛选 二.Dataframe数据遍历 for...in...语句 iteritems()方法 iterrows()方法 itertuples()方法 一.条件筛选 查询Pandas Dataframe数据时,经常会筛选出符合条件的数据,接下来介绍一下具体的使用方式. 示例Dataframe如下: 单条件筛选,例如查询gender为woman的数据: df[df["gender"]=="woman"] # 或 df.loc[df["gender