pytorch如何获得模型的计算量和参数量
方法1 自带
pytorch自带方法,计算模型参数总量
total = sum([param.nelement() for param in model.parameters()])
print("Number of parameter: %.2fM" % (total/1e6))
或者
total = sum(p.numel() for p in model.parameters())
print("Total params: %.2fM" % (total/1e6))
方法2 编写代码
计算模型参数总量和模型计算量
def count_params(model, input_size=224):
# param_sum = 0
with open('models.txt', 'w') as fm:
fm.write(str(model))
# 计算模型的计算量
calc_flops(model, input_size)
# 计算模型的参数总量
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
print('The network has {} params.'.format(params))
# 计算模型的计算量
def calc_flops(model, input_size):
def conv_hook(self, input, output):
batch_size, input_channels, input_height, input_width = input[0].size()
output_channels, output_height, output_width = output[0].size()
kernel_ops = self.kernel_size[0] * self.kernel_size[1] * (self.in_channels / self.groups) * (
2 if multiply_adds else 1)
bias_ops = 1 if self.bias is not None else 0
params = output_channels * (kernel_ops + bias_ops)
flops = batch_size * params * output_height * output_width
list_conv.append(flops)
def linear_hook(self, input, output):
batch_size = input[0].size(0) if input[0].dim() == 2 else 1
weight_ops = self.weight.nelement() * (2 if multiply_adds else 1)
bias_ops = self.bias.nelement()
flops = batch_size * (weight_ops + bias_ops)
list_linear.append(flops)
def bn_hook(self, input, output):
list_bn.append(input[0].nelement())
def relu_hook(self, input, output):
list_relu.append(input[0].nelement())
def pooling_hook(self, input, output):
batch_size, input_channels, input_height, input_width = input[0].size()
output_channels, output_height, output_width = output[0].size()
kernel_ops = self.kernel_size * self.kernel_size
bias_ops = 0
params = output_channels * (kernel_ops + bias_ops)
flops = batch_size * params * output_height * output_width
list_pooling.append(flops)
def foo(net):
childrens = list(net.children())
if not childrens:
if isinstance(net, torch.nn.Conv2d):
net.register_forward_hook(conv_hook)
if isinstance(net, torch.nn.Linear):
net.register_forward_hook(linear_hook)
if isinstance(net, torch.nn.BatchNorm2d):
net.register_forward_hook(bn_hook)
if isinstance(net, torch.nn.ReLU):
net.register_forward_hook(relu_hook)
if isinstance(net, torch.nn.MaxPool2d) or isinstance(net, torch.nn.AvgPool2d):
net.register_forward_hook(pooling_hook)
return
for c in childrens:
foo(c)
multiply_adds = False
list_conv, list_bn, list_relu, list_linear, list_pooling = [], [], [], [], []
foo(model)
if '0.4.' in torch.__version__:
if assets.USE_GPU:
input = torch.cuda.FloatTensor(torch.rand(2, 3, input_size, input_size).cuda())
else:
input = torch.FloatTensor(torch.rand(2, 3, input_size, input_size))
else:
input = Variable(torch.rand(2, 3, input_size, input_size), requires_grad=True)
_ = model(input)
total_flops = (sum(list_conv) + sum(list_linear) + sum(list_bn) + sum(list_relu) + sum(list_pooling))
print(' + Number of FLOPs: %.2fM' % (total_flops / 1e6 / 2))
方法3 thop
需要安装thop
pip install thop
调用方法:计算模型参数总量和模型计算量,而且会打印每一层网络的具体信息
from thop import profile input = torch.randn(1, 3, 224, 224) flops, params = profile(model, inputs=(input,)) print(flops) print(params)
或者
from torchvision.models import resnet50
from thop import profile
# model = resnet50()
checkpoints = '模型path'
model = torch.load(checkpoints)
model_name = 'yolov3 cut asff'
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input, ),verbose=True)
print("%s | %.2f | %.2f" % (model_name, params / (1000 ** 2), flops / (1000 ** 3)))#这里除以1000的平方,是为了化成M的单位,
注意:输入必须是四维的
提高输出可读性, 加入一下代码。
from thop import clever_format macs, params = clever_format([flops, params], "%.3f")
方法4 torchstat
from torchstat import stat from torchvision.models import resnet50, resnet101, resnet152, resnext101_32x8d model = resnet50() stat(model, (3, 224, 224)) # (3,224,224)表示输入图片的尺寸
使用torchstat这个库来查看网络模型的一些信息,包括总的参数量params、MAdd、显卡内存占用量和FLOPs等。需要安装torchstat:
pip install torchstat
方法5 ptflops
作用:计算模型参数总量和模型计算量
安装方法:pip install ptflops
或者
pip install --upgrade git+https://github.com/sovrasov/flops-counter.pytorch.git
使用方法
import torchvision.models as models
import torch
from ptflops import get_model_complexity_info
with torch.cuda.device(0):
net = models.resnet18()
flops, params = get_model_complexity_info(net, (3, 224, 224), as_strings=True, print_per_layer_stat=True) #不用写batch_size大小,默认batch_size=1
print('Flops: ' + flops)
print('Params: ' + params)
或者
from torchvision.models import resnet50
import torch
import torchvision.models as models
# import torch
from ptflops import get_model_complexity_info
# model = models.resnet50() #调用官方的模型,
checkpoints = '自己模型的path'
model = torch.load(checkpoints)
model_name = 'yolov3 cut'
flops, params = get_model_complexity_info(model, (3,320,320),as_strings=True,print_per_layer_stat=True)
print("%s |%s |%s" % (model_name,flops,params))
注意,这里输入一定是要tuple类型,且不需要输入batch,直接输入输入通道数量与尺寸,如(3,320,320) 320为网络输入尺寸。
输出为网络模型的总参数量(单位M,即百万)与计算量(单位G,即十亿)
方法6 torchsummary
安装:pip install torchsummary
使用方法:
from torchsummary import summary ... summary(your_model, input_size=(channels, H, W))
作用:
1、每一层的类型、shape 和 参数量
2、模型整体的参数量
3、模型大小,和 fp/bp 一次需要的内存大小,可以用来估计最佳 batch_size
补充:pytorch计算模型算力与参数大小
ptflops介绍
这个脚本设计用于计算卷积神经网络中乘法-加法操作的理论数量。它还可以计算参数的数量和打印给定网络的每层计算成本。
支持layer:Conv1d/2d/3d,ConvTranspose2d,BatchNorm1d/2d/3d,激活(ReLU, PReLU, ELU, ReLU6, LeakyReLU),Linear,Upsample,Poolings (AvgPool1d/2d/3d、MaxPool1d/2d/3d、adaptive ones)
安装要求:Pytorch >= 0.4.1, torchvision >= 0.2.1
get_model_complexity_info()
get_model_complexity_info是ptflops下的一个方法,可以计算出网络的算力与模型参数大小,并且可以输出每层的算力消耗。
栗子
以输出Mobilenet_v2算力信息为例:
from ptflops import get_model_complexity_info from torchvision import models net = models.mobilenet_v2() ops, params = get_model_complexity_info(net, (3, 224, 224), as_strings=True, print_per_layer_stat=True, verbose=True)
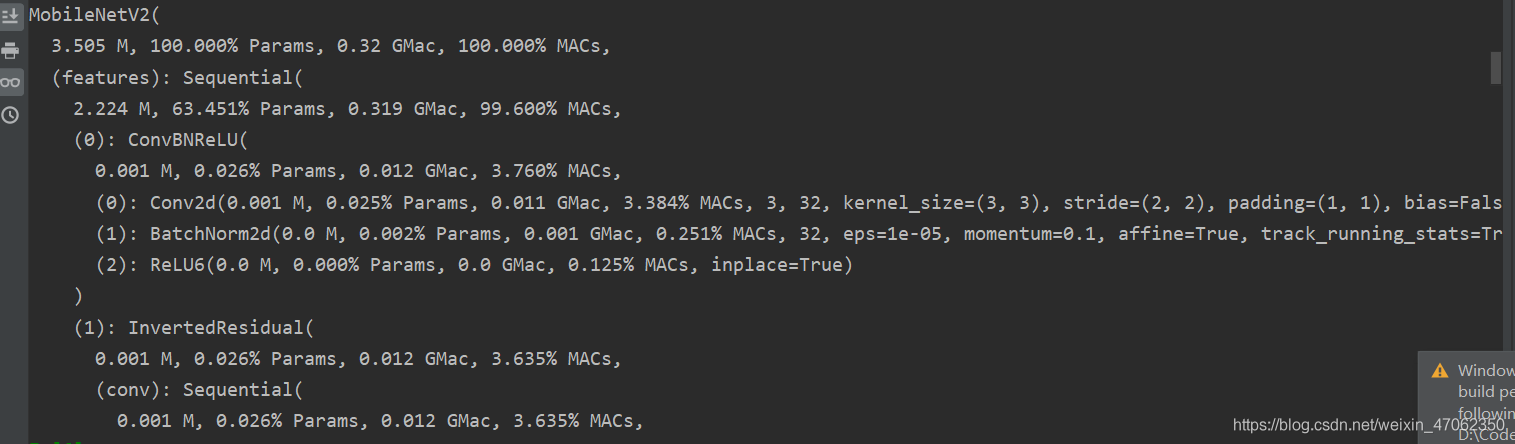
从图中可以看到,MobileNetV2在输入图像尺寸为(3, 224, 224)的情况下将会产生3.505MB的参数,算力消耗为0.32G,同时还打印出了每个层所占用的算力,权重参数数量。当然,整个模型的算力大小与模型大小也被存到了变量ops与params中。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch 求网络模型参数实例
用pytorch训练一个神经网络时,我们通常会很关心模型的参数总量.下面分别介绍来两种方法求模型参数 一 .求得每一层的模型参数,然后自然的可以计算出总的参数. 1.先初始化一个网络模型model 比如我这里是 model=cliqueNet(里面是些初始化的参数) 2.调用model的Parameters类获取参数列表 一个典型的操作就是将参数列表传入优化器里.如下 optimizer = optim.Adam(model.parameters(), lr=opt.lr) 言归正传,继续回到参
-
PyTorch和Keras计算模型参数的例子
Pytorch中,变量参数,用numel得到参数数目,累加 def get_parameter_number(net): total_num = sum(p.numel() for p in net.parameters()) trainable_num = sum(p.numel() for p in net.parameters() if p.requires_grad) return {'Total': total_num, 'Trainable': trainable_num} Kera
-
pytorch获取模型某一层参数名及参数值方式
1.Motivation: I wanna modify the value of some param; I wanna check the value of some param. The needed function: 2.state_dict() #generator type model.modules()#generator type named_parameters()#OrderDict type from torch import nn import torch #creat
-

pytorch如何获得模型的计算量和参数量
方法1 自带 pytorch自带方法,计算模型参数总量 total = sum([param.nelement() for param in model.parameters()]) print("Number of parameter: %.2fM" % (total/1e6)) 或者 total = sum(p.numel() for p in model.parameters()) print("Total params: %.2fM" % (total/1e
-
PyTorch搭建多项式回归模型(三)
PyTorch基础入门三:PyTorch搭建多项式回归模型 1)理论简介 对于一般的线性回归模型,由于该函数拟合出来的是一条直线,所以精度欠佳,我们可以考虑多项式回归来拟合更多的模型.所谓多项式回归,其本质也是线性回归.也就是说,我们采取的方法是,提高每个属性的次数来增加维度数.比如,请看下面这样的例子: 如果我们想要拟合方程: 对于输入变量和输出值,我们只需要增加其平方项.三次方项系数即可.所以,我们可以设置如下参数方程: 可以看到,上述方程与线性回归方程并没有本质区别.所以我们可以采用线性回
-
深入理解Pytorch微调torchvision模型
目录 一.简介 二.导入相关包 三.数据输入 四.辅助函数 1.模型训练和验证 2.设置模型参数的'.requires_grad属性' 一.简介 在本小节,深入探讨如何对torchvision进行微调和特征提取.所有模型都已经预先在1000类的magenet数据集上训练完成. 本节将深入介绍如何使用几个现代的CNN架构,并将直观展示如何微调任意的PyTorch模型. 本节将执行两种类型的迁移学习: 微调:从预训练模型开始,更新我们新任务的所有模型参数,实质上是重新训练整个模型. 特征提取:从预训
-
pytorch 实现打印模型的参数值
对于简单的网络 例如全连接层Linear 可以使用以下方法打印linear层: fc = nn.Linear(3, 5) params = list(fc.named_parameters()) print(params.__len__()) print(params[0]) print(params[1]) 输出如下: 由于Linear默认是偏置bias的,所有参数列表的长度是2.第一个存的是全连接矩阵,第二个存的是偏置. 对于稍微复杂的网络 例如MLP mlp = nn.Sequential
-
pytorch中获取模型input/output shape实例
Pytorch官方目前无法像tensorflow, caffe那样直接给出shape信息,详见 https://github.com/pytorch/pytorch/pull/3043 以下代码算一种workaround.由于CNN, RNN等模块实现不一样,添加其他模块支持可能需要改代码. 例如RNN中bias是bool类型,其权重也不是存于weight属性中,不过我们只关注shape够用了. 该方法必须构造一个输入调用forward后(model(x)调用)才可获取shape #coding
-
pytorch 实现cross entropy损失函数计算方式
均方损失函数: 这里 loss, x, y 的维度是一样的,可以是向量或者矩阵,i 是下标. 很多的 loss 函数都有 size_average 和 reduce 两个布尔类型的参数.因为一般损失函数都是直接计算 batch 的数据,因此返回的 loss 结果都是维度为 (batch_size, ) 的向量. (1)如果 reduce = False,那么 size_average 参数失效,直接返回向量形式的 loss (2)如果 reduce = True,那么 loss 返回的是标量 a
-
pytorch构建多模型实例
pytorch构建双模型 第一部分:构建"se_resnet152","DPN92()"双模型 import numpy as np from functools import partial import torch from torch import nn import torch.nn.functional as F from torch.optim import SGD,Adam from torch.autograd import Variable fro
-
Pytorch实现将模型的所有参数的梯度清0
有两种方式直接把模型的参数梯度设成0: model.zero_grad() optimizer.zero_grad()#当optimizer=optim.Optimizer(model.parameters())时,两者等效 如果想要把某一Variable的梯度置为0,只需用以下语句: Variable.grad.data.zero_() 补充知识:PyTorch中在反向传播前为什么要手动将梯度清零?optimizer.zero_grad()的意义 optimizer.zero_grad()意思
-
PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
vue中的计算属性传参
目录 vue计算属性传参 我们来看看下面的示例 vue计算属性传参,根据值不同,渲染相应的内容 业务描述 vue计算属性传参 最近很多小伙伴问到,计算属性怎么做到像普通函数一样传参呢? 针对这个问题 我们来看看下面的示例 <template> <p>{{ getCallerName }}</p> </template> <script> export default { props: { callRecord: