C语言举例讲解i++与++i之间的区别
目录
- 1.++i和i++的区别
- 2.++i与i++哪个效率更高
- 3.总结
1.++i和i++的区别
众所周知的(也是学校教的),就是先自增再赋值还是先赋值再自增的区别。
#include<iostream>
using namespace std;
int main()
{
int a = 0;
int b = 0;
int c = ++a;
int d = b++;
cout << "c = " << c << endl;
cout << "d = " << d << endl;
return 0;
}
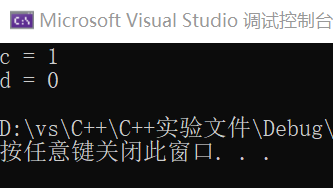
- a先自增再赋值给c,所以输出c为1。
- b先赋值给d再自增,所以输出d为0。
从这个方面来看,++i与i++的区别(尤其是性能方面)没有什么差别,很多同学也并没有思考过这个问题。
2.++i与i++哪个效率更高
下面是两段源码及其通过vs反汇编得到的汇编代码:
使用++i
#include<iostream>
using namespace std;
int main()
{
for (int i = 0; i < 100; ++i)
{
cout << "hello world" << endl;
}
return 0;
}
#include<iostream>
using namespace std;
int main()
{
00552540 push ebp
00552541 mov ebp,esp
00552543 sub esp,0CCh
00552549 push ebx
0055254A push esi
0055254B push edi
0055254C lea edi,[ebp-0Ch]
0055254F mov ecx,3
00552554 mov eax,0CCCCCCCCh
00552559 rep stos dword ptr es:[edi]
0055255B mov ecx,offset _57B8321F_源@cpp (055F029h)
00552560 call @__CheckForDebuggerJustMyCode@4 (055137Fh)
for (int i = 0; i < 100; ++i)
00552565 mov dword ptr [ebp-8],0
0055256C jmp __$EncStackInitStart+2Bh (0552577h)
0055256E mov eax,dword ptr [ebp-8]
00552571 add eax,1
00552574 mov dword ptr [ebp-8],eax
00552577 cmp dword ptr [ebp-8],64h
0055257B jge __$EncStackInitStart+5Ch (05525A8h)
{
cout << "hello world" << endl;
0055257D mov esi,esp
0055257F push offset std::endl<char,std::char_traits<char> > (055103Ch)
00552584 push offset string "hello world" (0559B30h)
00552589 mov eax,dword ptr [__imp_std::cout (055D0D4h)]
0055258E push eax
0055258F call std::operator<<<std::char_traits<char> > (05511A9h)
00552594 add esp,8
00552597 mov ecx,eax
00552599 call dword ptr [__imp_std::basic_ostream<char,std::char_traits<char> >::operator<< (055D0A0h)]
0055259F cmp esi,esp
005525A1 call __RTC_CheckEsp (055128Fh)
}
005525A6 jmp __$EncStackInitStart+22h (055256Eh)
return 0;
005525A8 xor eax,eax
}
使用i++
#include<iostream>
using namespace std;
int main()
{
for (int i = 0; i < 100; i++)
{
cout << "hello world" << endl;
}
return 0;
}
#include<iostream>
using namespace std;
int main()
{
008B2540 push ebp
008B2541 mov ebp,esp
008B2543 sub esp,0CCh
008B2549 push ebx
008B254A push esi
008B254B push edi
008B254C lea edi,[ebp-0Ch]
008B254F mov ecx,3
008B2554 mov eax,0CCCCCCCCh
008B2559 rep stos dword ptr es:[edi]
008B255B mov ecx,offset _57B8321F_源@cpp (08BF029h)
008B2560 call @__CheckForDebuggerJustMyCode@4 (08B137Fh)
for (int i = 0; i < 100; i++)
008B2565 mov dword ptr [ebp-8],0
008B256C jmp __$EncStackInitStart+2Bh (08B2577h)
008B256E mov eax,dword ptr [ebp-8]
008B2571 add eax,1
008B2574 mov dword ptr [ebp-8],eax
008B2577 cmp dword ptr [ebp-8],64h
008B257B jge __$EncStackInitStart+5Ch (08B25A8h)
{
cout << "hello world" << endl;
008B257D mov esi,esp
008B257F push offset std::endl<char,std::char_traits<char> > (08B103Ch)
008B2584 push offset string "hello world" (08B9B30h)
008B2589 mov eax,dword ptr [__imp_std::cout (08BD0D4h)]
008B258E push eax
008B258F call std::operator<<<std::char_traits<char> > (08B11A9h)
008B2594 add esp,8
008B2597 mov ecx,eax
008B2599 call dword ptr [__imp_std::basic_ostream<char,std::char_traits<char> >::operator<< (08BD0A0h)]
008B259F cmp esi,esp
008B25A1 call __RTC_CheckEsp (08B128Fh)
}
008B25A6 jmp __$EncStackInitStart+22h (08B256Eh)
return 0;
008B25A8 xor eax,eax
}
哈哈哈哈哈,有的同学已经发现了,好像并没有什么区别。
之前的说法是++i比i++的效率更高,但随着编译器的不断优化,两者简单应用时并没有什么区别。
但是,真是如此吗?
i++使用时,要先用将自身数据拷贝到临时变量中,再自增,最后传输临时变量。
而++i并不需要这般麻烦,直接自增再传输即可。一些追求压缩空间和时间的嵌入式工程师往往喜欢使用++i。
下面通过运算符重载自实现++i和i++来解释:
#include<iostream>
using namespace std;
class MyInt
{
friend ostream& operator<<(ostream& cout, MyInt& a);//友元
public:
MyInt();
MyInt& operator++();//前置++
MyInt& operator++(int);//使用占位参数区别前后置++,使之可以发生函数重载
private:
int m_num;
};
MyInt::MyInt()
{
this->m_num = 0;
}
MyInt& MyInt::operator++()
{
this->m_num++;
return *this;
}
MyInt& MyInt::operator++(int)
{
static MyInt temp = *this;
this->m_num++;
return temp;
}
ostream& operator<<(ostream& cout, MyInt& a)
{
cout << a.m_num;
return cout;
}
通过上面的代码显而易见其区别,且后置++难以实现链式编程。
3.总结
普通简单使用的情况下,两者并没有什么区别。
但在某些机器情况下或在类中使用时,++i的效率更高。
初学小白可以养成使用++i而非i++的习惯哦!
到此这篇关于C语言举例讲解i++与++i之间的区别的文章就介绍到这了,更多相关C语言 i++与++i内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
探讨++i与i++哪个效率更高
答案: 在内建数据类型的情况下,效率没有区别: 在自定义数据类型的情况下,++i效率更高! 分析: (自定义数据类型的情况下) ++i返回对象的引用: i++总是要创建一个临时对象,在退出函数时还要销毁它,而且返回临时对象的值时还会调用其拷贝构造函数. (重载这两个运算符如下) 复制代码 代码如下: #include <iostream>using namespace std; class MyInterger{public: long m_data;public: MyInter
-
C++小知识:用++i替代i++
静态代码分析工具可简化编码过程,检测出错误并帮助修复.PVS-Studio 是一个用于 C/C++ 的静态代码分析工具.该团队检测了 200 多个 C/C++ 开源项目,包括了 Unreal Engine.Php.Haiku.Qt 和 Linux 内核等知名项目.于是他们每天分享一个错误案例,并给出相应建议. 这个 bug 是在 Unreal Engine 4 的源代码中发现的. 错误代码: void FSlateNotificationManager::GetWindows( TArray<
-

C语言举例讲解i++与++i之间的区别
目录 1.++i和i++的区别 2.++i与i++哪个效率更高 3.总结 1.++i和i++的区别 众所周知的(也是学校教的),就是先自增再赋值还是先赋值再自增的区别. #include<iostream> using namespace std; int main() { int a = 0; int b = 0; int c = ++a; int d = b++; cout << "c = " << c << endl; cout &
-
用C语言举例讲解数据结构中的算法复杂度结与顺序表
数据结构算法复杂度 1.影响算法效率的主要因素 (1)算法采用的策略和方法: (2)问题的输入规模: (3)编译器所产生的代码: (4)计算机执行速度. 2.时间复杂度 // 时间复杂度:2n + 5 long sum1(int n) { long ret = 0; \\1 int* array = (int*)malloc(n * sizeof(int)); \\1 int i = 0; \\1 for(i=0; i<n; i++) \\n { array[i] = i + 1; } for(
-
C/C++举例讲解关键字的用法
目录 static static修饰全局变量 static修饰局部变量 static修饰函数 const BOOL break continue static static修饰全局变量 static修饰的全局变量只能在当前声明文件内使用,不能够在其他文件中使用. 举例: static int a=0; //static修饰后变量a仅在本文件中可见,其他文件里不可见变量a(隐藏了),别的文件不可以调用 int b=0; //其他文件可以通过extern int b来使用本文件中的全局变量b 目标:
-
Python调用R语言实例讲解
网络上经常看到有人问数据分析是学习Python好还是R语言好,还有一些争论Python好还是R好的文章.每次看到这样的文章我都会想到李舰和肖凯的<数据科学中的R语言>,书中一直强调,工具不分好坏,重要的是解决问题的思路,就算是简单的excel,也能应付数据分析中的大部分问题.再者Python和R本来就没有什么好对比的,一门是计算机工程语言,一门是统计语言,只有将两者结合起来,才能发挥更大的威力,不是吗,对于数据分析的人来说,难道不是两样都要掌握的吗? rpy2是Python调用R程序的模块,旨
-
C语言由浅入深讲解文件的操作下篇
目录 文件的顺序读写 字符输入输出fgetc和fputc 文本行输入输出函数fgets和fputs 格式化输入输出函数fscanf和fprintf 二进制输入输出函数fread和fwrite 文件的随机读写 fseek ftell fwind 文本文件和二进制文件 文件结束的判定 feof 文件缓冲区 第一篇讲了文件的基本概念,和文件如何打开和关闭.第二篇主要介绍文件的顺序读写和随机读写.外加文件缓冲区的知识点. 文件的顺序读写 字符输入输出fgetc和fputc fgetc:字符输入函数,也就
-
C语言全方位讲解指针与地址和数组函数堆空间的关系
目录 一.一种特殊的变量-指针 二.深入理解指针与地址 三.指针与数组(上) 四.指针与数组(下) 五.指针与函数 六.指针与堆空间 七.指针专题经典问题剖析 一.一种特殊的变量-指针 指针是C语言中的变量 因为是变量,所以用于保存具体值 特殊之处,指针保存的值是内存中的地址 内存地址是什么? 内存是计算机中的存储部件,每个存储单元有固定唯一的编号 内存中存储单元的编号即内存地址 需要弄清楚的事实 程序中的一切元素都存在于内存中,因此,可通过内存地址访问程序元素. 内存示例 获取地址 C语言中通
-
C语言全面讲解顺序表使用操作
目录 一.顺序表的结构定义 二.顺序表的结构操作 1.初始化 2.插入操作 3.删除操作 4.扩容操作 5.释放操作 6.输出 三.示例 编程环境为 ubuntu 18.04. 顺序表需要连续一片存储空间,存储任意类型的元素,这里以存储 int 类型数据为例. 一.顺序表的结构定义 size 为容量,length 为当前已知数据表元素的个数 typedef struct Vector{ int *data; //该顺序表这片连续空间的首地址 int size, length; } Vec; 二.
-
C语言简明讲解类型转换的使用与作用
目录 一.类型之间的转换 二.强制类型转换 三.隐式类型转换 四.表达式中的隐式类型转换 五.小结 一.类型之间的转换 C语言中的数据类型可以进行转换 强制类型转换 隐式类型转换 二.强制类型转换 强制类型转换的语法 (Type)var_name; (Type)value; 强制类型转换的结果 目标类型能够容纳目标值:结果不变 目标类型不能容纳目标值:结果将产生截断 注意:不是所有的强制类型转换都能成功,当不能进行强制类型转换时,编译器将产生错误信息(比如将自定义数据类型转换成基本数据类型).
-
C语言 详细讲解接续符和转义符的使用
目录 一.接续符的意义 二.接续符的使用 三.转义符的意义 四.转义符的使用 五.转义符和其他的语法混合 六.小结 一.接续符的意义 C语言中的接续符(\)是指示编译器行为的利器 下面看一段接续符的代码(代码1-1): #in\clud\e <st\dio.h>in\t m\ain(\){pri\ntf\ (\ "Hello AutumnZe.\n" )\ ; ret\urn 0;} 可以看到上述代码写的很凌乱,但是可以正常编译运行,如下: 二.接
-
C语言详细讲解二分查找用法
目录 [力扣题号]704.二分查找 力扣题目链接 示例 1: 输入: nums = [-1,0,3,5,9,12], target = 9 输出: 4 解释: 9 出现在 nums 中并且下标为 4 示例 2: 输入: nums = [-1,0,3,5,9,12], target = 2 输出: -1 解释: 2 不存在 nums 中因此返回 -1 提示: 你可以假设 nums中的所有元素是不重复的. n将在[1, 10000]之间. nums的每个元素