MySQL和Redis的数据一致性问题
目录
- 一、一致性问题
- 二、方案选择
- 1、是删除缓存还是更新缓存?
- 2、先更新数据库,再删除缓存
- 3、失败重试
- 4、异步更新缓存
- 5、、先删除缓存,再更新数据库
前言:
在数据读多写少的情况下作为缓存来使用,恐怕是Redis使用最普遍的场景了。当使用Redis作为缓存的时候,一般流程是这样的。
- 如果缓存在
Redis中存在,即缓存命中,则直接返回数据
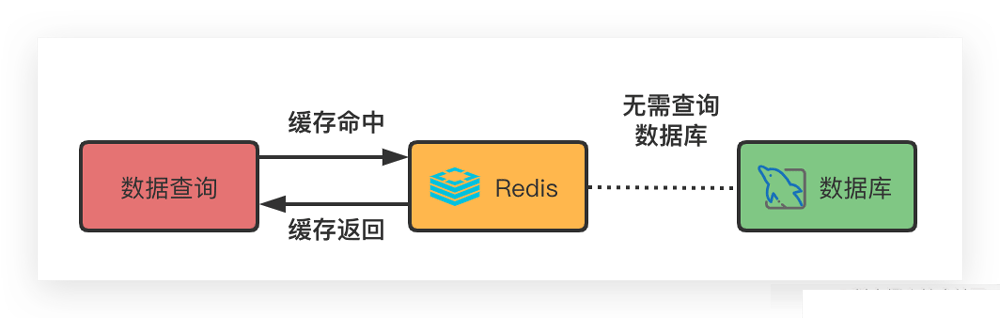
- 如果Redis中没有对应缓存,则需要直接查询数据库,然后存入Redis,最后把数据返回
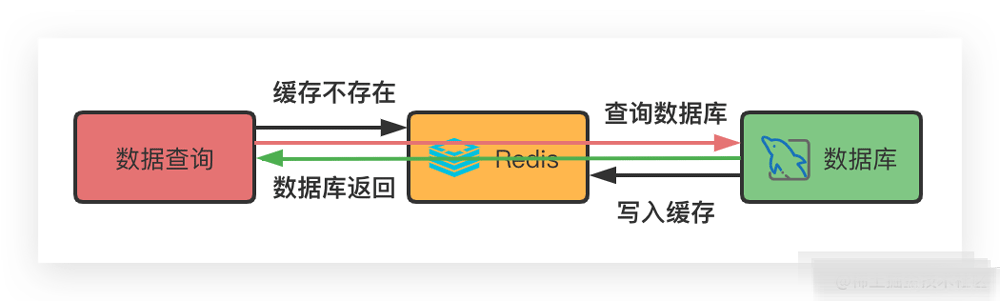
通常情况下,我们会为某个缓存设置一个key值,并针对key值设置一个过期时间,如果被查询的数据对应的key过期了,则直接查询数据库,并将查询得到的数据存入Redis,然后重置过期时间,最后将数据返回,伪代码如下:
/**
* 根据用户名获取用户详细信息
* @author 公众号【蝉沐风】
*/
public User getUserInfo(String userName) {
User user = redisCache.getName("user:" + userName);
if (user != null) {
return user;
}
// 从数据库中直接搜索
user = selectUserByUserName(userName);
// 将数据写入Redis,并设置过期时间
redisCache.set("user:" + userName, user, 30000);
// 返回数据
return user;
}
一、一致性问题
但是,在Redis的key值未过期的情况下,用户修改了个人信息,我们此时既要操作数据库数据,也要操作Redis数据。现在我们面临了两种选择:
- 先操作
Redis的数据,再操作数据库的数据 - 先操作数据库的数据,再操作
Redis的数据
如论选择哪种方法,最理想的情况下,两个操作要么同时成功,要么同时失败,否则就会出现Redis和数据库数据不一致的情况。
遗憾的是,目前没有什么框架能够保证Redis的数据和数据库的数据的完全一致性。我们只能根据场景和所需要付出的代码来采取一定的措施降低数据不一致出现的概率,在一致性和性能之间取得一个折中。
下面我们来讨论一下关于Redis和数据库质检数据一致性的一些方案。
二、方案选择
1、是删除缓存还是更新缓存?
当数据库数据发生变化的时候,Redis的数据也需要进行相应的操作,那么这个「操作」到底是用「更新」还是用「删除」呢?
「更新」的话调用Redis的set方法,新值替换旧值;「删除」直接删除原来的缓存,下次查询的时候重新读取数据库,然后再更新Redis。
结论:推荐直接使用「删除」操作。
因为使用「更新」操作的话,你会面临两种选择
- 先更新缓存,再更新数据库
- 先更新数据库,再更新缓存
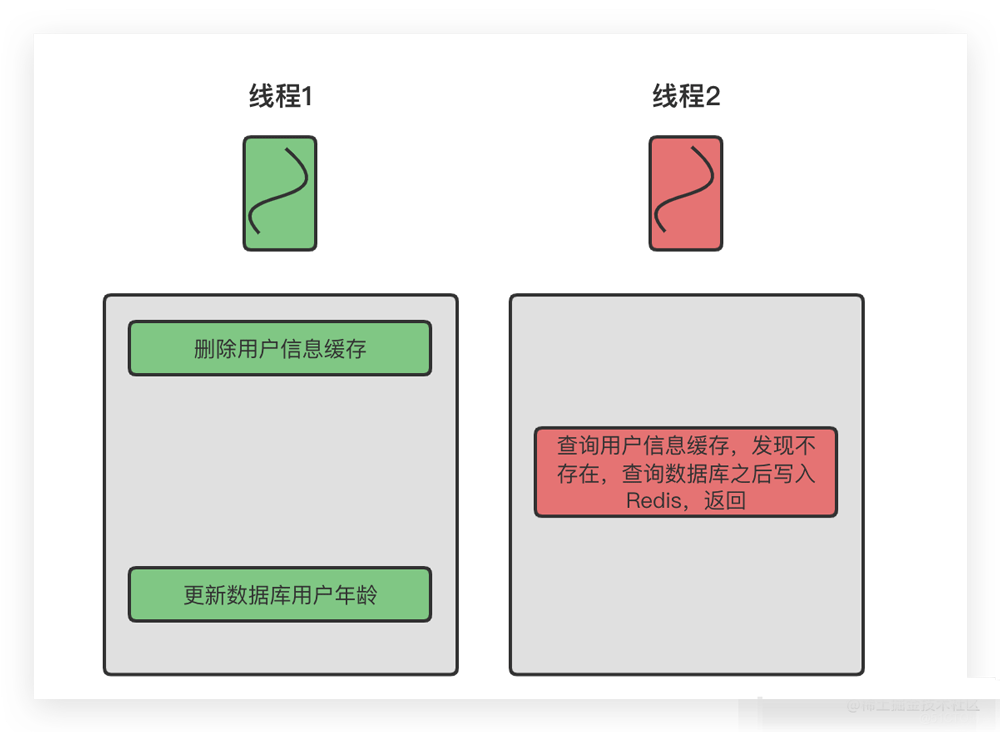
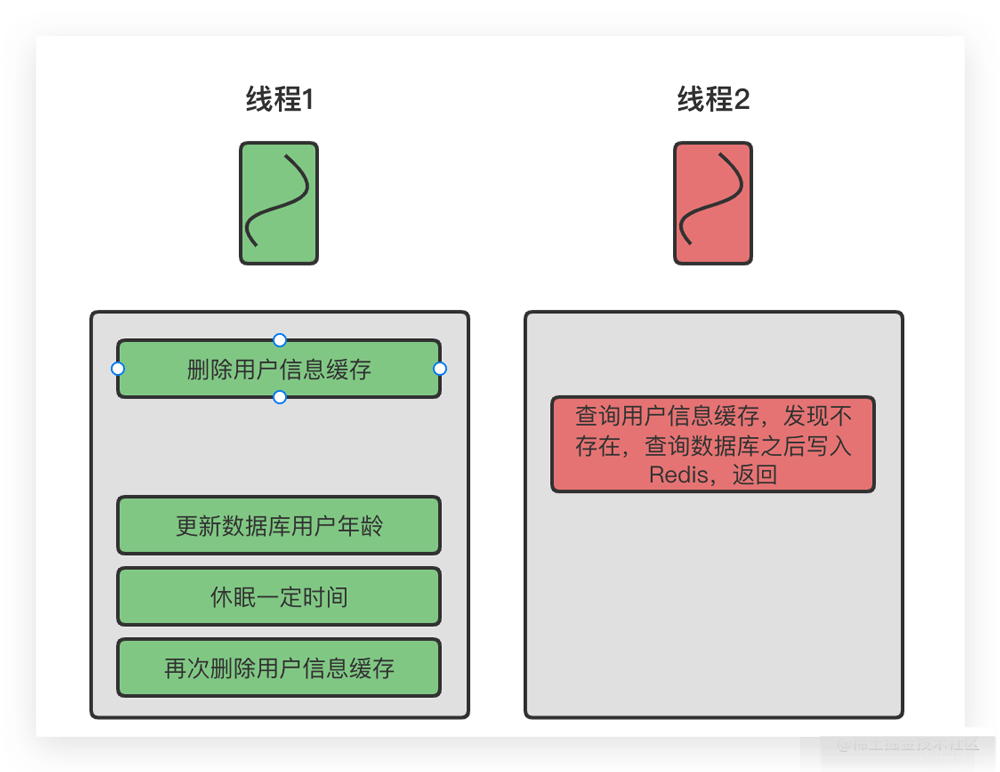
第1种不用考虑了,下面讨论一下「先更新数据库,再更新缓存」这种方案。

如果线程1和线程2同时进行更新操作,但是每个线程的执行顺序如上图所示,此时就会导致数据不一致,因此从这个角度上我们推荐直接使用删除缓存的方式。
此外,推荐使用「删除缓存」还有两点原因。
- 如果写数据库的场景比读数据场景多,采用这种方案就会导致缓存就被频繁写入,浪费性能;
- 如果缓存要经过一系列复杂的计算才能得到,那么每次写入数据库后,都再次计算写入的缓存无疑也是浪费性能的。
明确这个问题之后,摆在我们面前的就只有两个选择了:
- 先更新数据库,再删除缓存
- 先删除缓存,再更新数据库
2、先更新数据库,再删除缓存
这种方式可能存在以下两种异常情况
- 更新数据库失败,这时可以通过程序捕获异常,直接返回结果,不再继续删除缓存,所以不会出现数据不一致的问题
- 更新数据库成功,删除缓存失败。导致数据库是最新数据,缓存中的是旧数据,数据不一致
第2种情况应该怎么办呢?我们有两种方式:失败重试和异步更新。
3、失败重试
如果删除缓存失败,我们可以捕获这个异常,把需要删除的 key 发送到消息队列。自己创建一个消费者消费,尝试再次删除这个 key,直到删除成功为止。
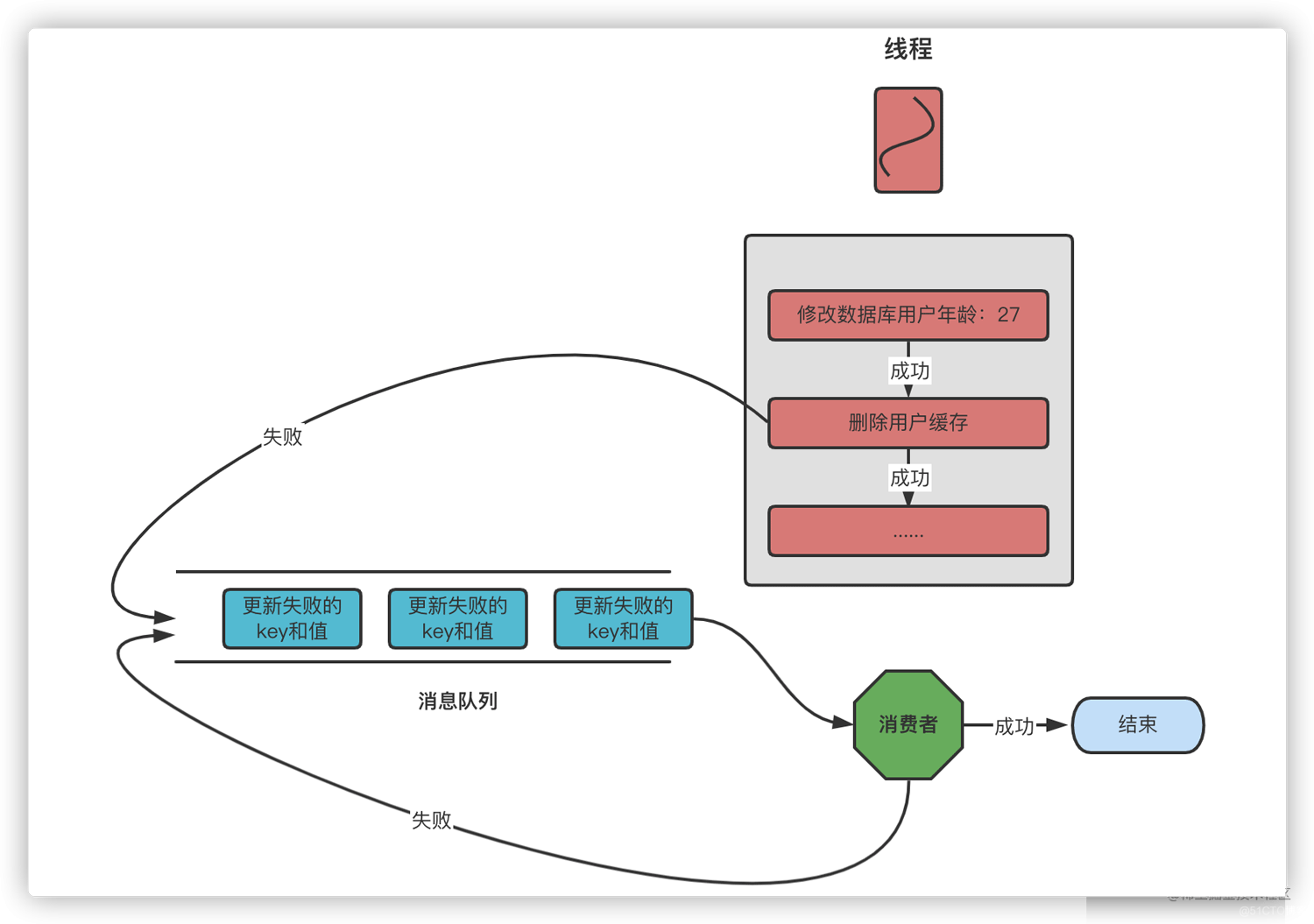
这种方式有个缺点,首先会对业务代码造成入侵,其次引入了消息队列,增加了系统的不确定性。
4、异步更新缓存
因为更新数据库时会往 binlog 中写入日志,所以我们可以启动一个监听 binlog变化的服务(比如使用阿里的 canal开源组件),然后在客户端完成删除 key 的操作。如果删除失败的话,再发送到消息队列。
总结
总之,对于删除缓存失败的情况,我们的做法是不断地重试删除操作,直到成功。无论是重试还是异步删除,都是最终一致性的思想。
5、、先删除缓存,再更新数据库
这种方式可能存在以下两种异常情况:
- 删除缓存失败,这时可以通过程序捕获异常,直接返回结果,不再继续更新数据库,所以不会出现数据不一致的问题
- 删除缓存成功,更新数据库失败。在多线程下可能会出现数据不一致的问题
这时,Redis中存储的旧数据,数据库的值是新数据,导致数据不一致。这时我们可以采用延时双删的策略,即更新数据库数据之后,再删除一次缓存。
用伪代码表示就是:
/**
* 延时双删
* @author 公众号【蝉沐风】
*/
public void update(String key, Object data) {
// 首先删除缓存
redisCache.delKey(key);
// 更新数据库
db.updateData(data);
// 休眠一段时间,时间依据数据的读取耗费的时间而定
Thread.sleep(500);
// 再次删除缓存
redisCache.delKey(key);
}
到此这篇关于MySQL和Redis的数据一致性问题的文章就介绍到这了,更多相关MySQL和Redis内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python定时从Mysql提取数据存入Redis的实现
设计思路: 1.程序一旦run起来,python会把mysql中最近一段时间的数据全部提取出来 2.然后实例化redis类,将数据简单解析后逐条传入redis队列 3.定时器设计每天凌晨12点开始跑 ps:redis是个内存数据库,做后台消息队列的缓存时有很大的用处,有兴趣的小伙伴可以去查看相关的文档. # -*- coding:utf-8 -*- import MySQLdb import schedule import time import datetime import random i
-

Spring Boot实战解决高并发数据入库之 Redis 缓存+MySQL 批量入库问题
目录 前言 架构设计 代码实现 测试 总结 前言 最近在做阅读类的业务,需要记录用户的PV,UV: 项目状况:前期尝试业务阶段: 特点: 快速实现(不需要做太重,满足初期推广运营即可)快速投入市场去运营 收集用户的原始数据,三要素: 谁在什么时间阅读哪篇文章 提到PV,UV脑海中首先浮现特点: 需要考虑性能(每个客户每打开一篇文章进行记录)允许数据有较小误差(少部分数据丢失) 架构设计 架构图: 时序图 记录基础数据MySQL表结构 CREATE TABLE `zh_article_count`
-
python连接MySQL、MongoDB、Redis、memcache等数据库的方法
用Python写脚本也有一段时间了,经常操作数据库(MySQL),现在就整理下对各类数据库的操作,如后面有新的参数会补进来,慢慢完善. 一,python 操作 MySQL:详情见:[apt-get install python-mysqldb] 复制代码 代码如下: #!/bin/env python# -*- encoding: utf-8 -*-#-------------------------------------------------------------------------
-
PHP结合Redis+MySQL实现冷热数据交换应用案例详解
本文实例讲述了PHP结合Redis+MySQL实现冷热数据交换应用案例.分享给大家供大家参考,具体如下: 场景:某网站需要对其项目做一个投票系统,投票项目上线后一小时之内预计有100万用户进行投票,希望用户投票完就能看到实时的投票情况 这个场景可以使用redis+mysql冷热数据交换来解决. 何为冷热数据交换? 冷数据:之前使用的数据,热数据:当前使用的数据. 交换:将Redis中的数据周期的存储到MySQL中 业务流程 用户进行投票后,首先将投票数据保存到Redis中,这些数据就是热数据,然
-
解决docker重启redis,mysql数据丢失的问题
官方文档: 所以 mysql应如下启动: docker run -p 3306:3306 -d -e MYSQL_ROOT_PASSWORD=密码 -v /windows盘符/指定的文件夹路径:/var/lib/mysql mysql:5.7 redis: docker run -p 6379:6379 -d -v /windows盘符/指定的文件夹路径:/data redis:5.0 redis-server --appendonly yes 多看官方文档,里面有详细的说明 补充
-
PHP的Laravel框架结合MySQL与Redis数据库的使用部署
相对于熟读官方文档,更重要的是要把框架环境搭起来. 零.环境介绍 操作系统:centOS 数据库: mysql 5.6 (阿里云RDS) PHP 5.4.4 (>=5.4即可) Laravel 5.0 一.安装LNMP 在安装Laravel之前,需要把Linux + Nginx + Mysql + Php的环境搭建好.具体的搭建步骤这里就不再详述了. P.S. Linux阿里云已经自带了,本文使用的是centOS 6.5 64位的ECS 关于Nginx和Apache的选择看自己喜好,本文使用的是
-
MySQL与Redis如何保证数据一致性详解
前言 由于缓存的高并发和高性能已经在各种项目中被广泛使用,在读取缓存这方面基本都是一致的,大概都是按照下图的流程进行操作: 但是在更新缓存方面,是更新完数据库再更新缓存还是直接删除缓存呢?又或者是先删除缓存再更新数据库?在这一点上就值得探讨了. 一致性方案 在实际项目开发中需要保证数据库和缓存中的数据一致,否则人家充值了100块,不断刷新却还是显示0.01元,岂不是尴尬?从理论上来说,为缓存设置过期时间是最终保证数据一致性的解决方案,采用这种方案的话,所有的写操作都是以数据库为准,如果数据库写入
-
从MySQL到Redis的简单数据库迁移方法
从mysql搬一个大表到redis中,你会发现在提取.转换或是载入一行数据时,速度慢的让你难以忍受.这里我就要告诉一个让你解脱的小技巧.使用"管道输出"的方式把mysql命令行产生的内容直接传递给redis-cli,以绕过"中间件"的方式使两者在进行数据操作时达到最佳速度. 一个约八百万行数据的mysql表,原本导入到redis中需要90分钟,使用这个方法后,只需要两分钟.不管你信不信,反正我是信了. Mysql到Redis的数据协议 redis-cli命令行工具有
-
MySQL和Redis的数据一致性问题
目录 一.一致性问题 二.方案选择 1.是删除缓存还是更新缓存? 2.先更新数据库,再删除缓存 3.失败重试 4.异步更新缓存 5..先删除缓存,再更新数据库 前言: 在数据读多写少的情况下作为缓存来使用,恐怕是Redis使用最普遍的场景了.当使用Redis作为缓存的时候,一般流程是这样的. 如果缓存在Redis中存在,即缓存命中,则直接返回数据 如果Redis中没有对应缓存,则需要直接查询数据库,然后存入Redis,最后把数据返回 通常情况下,我们会为某个缓存设置一个key值,并针对key值设
-
python笔记:mysql、redis操作方法
模块安装: 数据操作用到的模块pymysql,需要通过pip install pymysql进行安装. redis操作用的模块是redis,需要通过pip install redis进行安装. 检验是否安装成功:进入到Python命令行模式,输入import pymysql. import redis ,无报错代表成功: mysql操作方法如下: 查询数据:fetchone.fetchmany(n).fetchall() import pymysql #建立mysql连接,ip.端口.用户名.密
-
PHP商品秒杀问题解决方案实例详解【mysql与redis】
本文实例讲述了PHP商品秒杀问题解决方案.分享给大家供大家参考,具体如下: 引言 假设num是存储在数据库中的字段,保存了被秒杀产品的剩余数量. if($num > 0){ //用户抢购成功,记录用户信息 $num--; } 假设在一个并发量较高的场景,数据库中num的值为1时,可能同时会有多个进程读取到num为1,程序判断符合条件,抢购成功,num减一.这样会导致商品超发的情况,本来只有10件可以抢购的商品,可能会有超过10个人抢到,此时num在抢购完成之后为负值. 解决该问题的方案由很多,可
-
MySQL和Redis实现二级缓存的方法详解
redis简介 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库 Redis 与其他 key - value 缓存产品有以下三个特点: Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用 Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储 Redis支持数据的备份,即master-slave模式的数据备份 优势 性能极高 - Redis能读的速度是110
-
Docker安装Tomcat、MySQL和Redis的步骤详解
总体步骤 Docker安装Tomcat docker hub上查找tomcat镜像 docker search tomcat 从docker hub上拉取tomcat镜像到本地 docker pull tomcat docker images查看是否有拉取到的tomcat 使用tomcat镜像创建容器(运行镜像) docker run -it -p 8080:8080 tomcat -p 主机端口:docker容器端口 -P 随机分配端口 i:交互 t:终端 Docker安装MySQL dock
-
Docker安装MySQL和Redis的方法步骤
本文是基于CentOS 7.3系统环境,进行MySQL和Redis的安装和使用 CentOS 7.3 Docker-ce 一.安装MySQL镜像 (1) 拉取MySQL镜像 docker pull mysql:5.6 (2) 运行并配置MySQL docker run -p 3306:3306 --name xz_mysql -v /data/mysql/conf:/etc/mysql/conf.g -v /data/mysql/logs:/logs -v /data/mysql/data:/v
-
浅谈MySQL与redis缓存的同步方案
本文介绍MySQL与Redis缓存的同步的两种方案 方案1:通过MySQL自动同步刷新Redis,MySQL触发器+UDF函数实现 方案2:解析MySQL的binlog实现,将数据库中的数据同步到Redis 一.方案1(UDF) 场景分析:当我们对MySQL数据库进行数据操作时,同时将相应的数据同步到Redis中,同步到Redis之后,查询的操作就从Redis中查找 过程大致如下: 在MySQL中对要操作的数据设置触发器Trigger,监听操作 客户端(NodeServer)向MySQL中写入数
-
点赞功能使用MySQL还是Redis
目录 1. 新手常犯的错误 2. 使用Iterator的remove()方法 3. 使用for循环正序遍历 4. 使用for循环倒序遍历 5. 使用Iterator的remove()方法 6. 使用for循环正序遍历 7. 使用for循环倒序遍历 这是最近面试时被问到的1道面试题,本篇博客对此问题进行总结分享. 1. 新手常犯的错误 可能很多新手(包括当年的我,哈哈)第一时间想到的写法是下面这样的: public static void main(String[] args) { List<St