YOLOV5代码详解之损失函数的计算
目录
- 摘要:
- 1、位置损失
- 2、置信度损失和类损失
- 总结
摘要:
神经网络的训练的主要流程包括图像输入神经网络, 得到模型的输出结果,计算模型的输出与真实值的损失, 计算损失值的梯度,最后用梯度下降算法更新模型参数。损失函数值的计算是非常关键的一个步骤。
本博客将对yolov5损失值的计算过程代码的实现做简要的理解。
def compute_loss(p, targets, model): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors = build_targets(p, targets, model) # targets
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['cls_pw']])).to(device)
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['obj_pw']])).to(device)
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
cp, cn = smooth_BCE(eps=0.0)
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
。。。。。。
yolov5代码用IOU指标评价目标框和预测框的位置损失损失。yolov5代码用nn.BCEWithLogitsLoss或FocalLoss评价目标框和预测框的类损失和置信度损失 .
yolov5代码用宽高比选择对应真实框的预测框,且每一个真实框对应三个预测框 。
1、位置损失
yolov5代码用IOU值评价预测框和真实框的位置损失, 本文介绍CIoU指标.
公式如下截图:

公式中参数代表的意义如下:
IOU: 预测框和真实框的叫并比
v是衡量长宽比一致性的参数,我们也可以定义为:
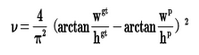
代码实现:
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-9):
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
box2 = box2.T
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if DIoU:
return iou - rho2 / c2 # DIoU
elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / ((1 + eps) - iou + v)
return iou - (rho2 / c2 + v * alpha) # CIoU
else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
else:
return iou # IoU
2、置信度损失和类损失
yolov5代码用nn.BCEWithLogitsLoss或FocalLoss评价目标框和预测框的类损失和置信度损失,本节一一介绍这两个损失函数。
- nn.BCEWithLogitsLoss:
首先对预测输出作sigmoid变换,然后求变换后的结果与真实值的二值交叉熵.
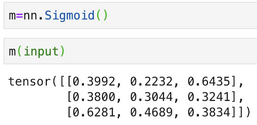
假设预测输出是3分类,预测输出:

预测输出sigmoid变换:
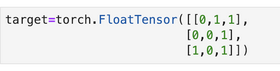
假设真实输出是:
两者的二值交叉熵的计算方法:

接口函数验证下上面的结果:
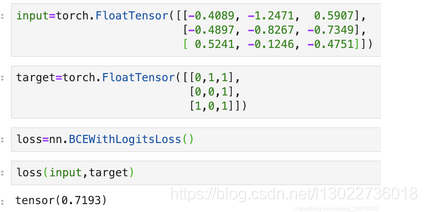
- FocalLoss损失:
FocalLoss损失考虑的是:目标检测中正负样本严重不均衡的一种策略。该损失函数的设计思想类似于boosting,降低容易分类的样本对损失函数的影响,注重较难分类的样本的训练.
简而言之,FocalLoss更加关注的是比较难分的样本,何谓难分?若某一个真实类预测的概率只有0.2,我们认为它比较难分,相反若该真实类的预测概率是0.95,则容易分类.
FocalLoss通过提高难分类别的损失函数来实现,公式如下:
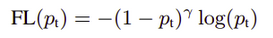
图像如下:
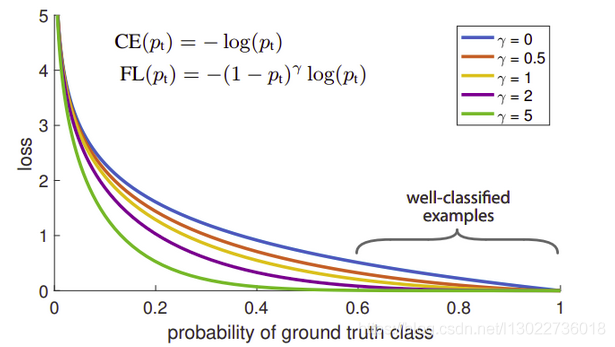
可以看出预测真实类概率越大,则损失函数越小,即实现了之前的想法.
为了能够平衡正负样本的重要性,我们可以给各个类别添加一个权重常数 α ,比如想使正样本初始权重为0.8,负样本就为0.2.
代码实现为:
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(FocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
其中成员函数loss_fcn为nn.BCEWithLogitsLoss。
总结
到此这篇关于YOLOV5代码详解之损失函数计算的文章就介绍到这了,更多相关YOLOV5损失函数计算内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

YOLOV5代码详解之损失函数的计算
目录 摘要: 1.位置损失 2.置信度损失和类损失 总结 摘要: 神经网络的训练的主要流程包括图像输入神经网络, 得到模型的输出结果,计算模型的输出与真实值的损失, 计算损失值的梯度,最后用梯度下降算法更新模型参数.损失函数值的计算是非常关键的一个步骤. 本博客将对yolov5损失值的计算过程代码的实现做简要的理解. def compute_loss(p, targets, model): # predictions, targets, model device = targets.device
-
Python生成验证码、计算具体日期是一年中的第几天实例代码详解
1.约瑟夫环问题 <幸运的基督徒> 有15个基督徒和15个非基督徒在海上遇险,为了能让一部分人活下来不得不将其中15个人扔到海里面去,有个人想了个办法就是大家围成一个圈,由某个人开始从1报数,报到9的人就扔到海里面,他后面的人接着从1开始报数,报到9的人继续扔到海里面,直到扔掉15个人.由于上帝的保佑,15个基督徒都幸免于难,问这些人最开始是怎么站的,哪些位置是基督徒哪些位置是非基督徒. def main(): ''' 先用列表中每个数字代表每个人,然后通过循环替换列表中的数字 用@代表基督徒
-
Java欧拉函数的计算代码详解
欧拉函数 在数论,对正整数n,欧拉函数是小于或等于n的正整数中与n互质的数的数目(因此φ(1)=1).此函数以其首名研究者欧拉命名(Euler's totient function),它又称为Euler's totient function.φ函数.欧拉商数等. 例如φ(8)=4,因为1,3,5,7均和8互质. 从欧拉函数引伸出来在环论方面的事实和拉格朗日定理构成了欧拉定理的证明. 欧拉函数-百度百科. 前言 在数论,对正整数n,欧拉函数是小于n的正整数中与n互质的数的数目(因此φ(1)=1).
-
JavaScript编写棋盘覆盖代码详解
一.前言 之前做了一个算法作业,叫做棋盘覆盖,本来需要用c语言来编写的,但是因为我的c语言是半桶水(哈哈),所以索性就把网上的c语言写法改成JavaScript写法,并且把它的覆盖效果显示出来 二.关键代码 <!DOCTYPE html> <html> <head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <titl
-
Java中Math类常用方法代码详解
近期用到四舍五入想到以前整理了一点,就顺便重新整理好经常见到的一些四舍五入,后续遇到常用也会直接在这篇文章更新... public class Demo{ public static void main(String args[]){ /** *Math.sqrt()//计算平方根 *Math.cbrt()//计算立方根 *Math.pow(a, b)//计算a的b次方 *Math.max( , );//计算最大值 *Math.min( , );//计算最小值 */ System.out.pri
-
Java数据溢出代码详解
java是一门相对安全的语言,那么数据溢出时它是如何处理的呢? 看一段代码, public class Overflow { /** * @param args */ public static void main(String[] args) { int big = 0x7fffffff; //max int value System.out.println("big = " + big); int bigger = big * 4; System.out.println("
-
python数字图像处理之高级滤波代码详解
本文提供许多的滤波方法,这些方法放在filters.rank子模块内. 这些方法需要用户自己设定滤波器的形状和大小,因此需要导入morphology模块来设定. 1.autolevel 这个词在photoshop里面翻译成自动色阶,用局部直方图来对图片进行滤波分级. 该滤波器局部地拉伸灰度像素值的直方图,以覆盖整个像素值范围. 格式:skimage.filters.rank.autolevel(image, selem) selem表示结构化元素,用于设定滤波器. from skimage im
-
java时间日期使用与查询代码详解
只要格式正确,直接比较字符串就可以了呀,精确到秒的也一样 String s1 = "2003-12-12 11:30:24"; String s2 = "2004-04-01 13:31:40"; int res = s1.compareTo(s2); 求日期差 SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date begin=df.parse("
-
Java计算数学表达式代码详解
Java字符串转换成算术表达式计算并输出结果,通过这个工具可以直接对字符串形式的算术表达式进行运算,并且使用非常简单. 这个工具中包含两个类 Calculator 和 ArithHelper Calculator 代码如下: import java.util.Collections; import java.util.Stack; /** * 算数表达式求值 * 直接调用Calculator的类方法conversion() * 传入算数表达式,将返回一个浮点值结果 * 如果计算过程错误,将返回一
-
机器学习经典算法-logistic回归代码详解
一.算法简要 我们希望有这么一种函数:接受输入然后预测出类别,这样用于分类.这里,用到了数学中的sigmoid函数,sigmoid函数的具体表达式和函数图象如下: 可以较为清楚的看到,当输入的x小于0时,函数值<0.5,将分类预测为0:当输入的x大于0时,函数值>0.5,将分类预测为1. 1.1 预测函数的表示 1.2参数的求解 二.代码实现 函数sigmoid计算相应的函数值:gradAscent实现的batch-梯度上升,意思就是在每次迭代中所有数据集都考虑到了:而stoGradAscen