Python神经网络TensorFlow基于CNN卷积识别手写数字
目录
- 基础理论
- 一、训练CNN卷积神经网络
- 1、载入数据
- 2、改变数据维度
- 3、归一化
- 4、独热编码
- 5、搭建CNN卷积神经网络
- 5-1、第一层:第一个卷积层
- 5-2、第二层:第二个卷积层
- 5-3、扁平化
- 5-4、第三层:第一个全连接层
- 5-5、第四层:第二个全连接层(输出层)
- 6、编译
- 7、训练
- 8、保存模型
- 代码
- 二、识别自己的手写数字(图像)
- 1、载入数据
- 2、载入训练好的模型
- 3、载入自己写的数字图片并设置大小
- 4、转灰度图
- 5、转黑底白字、数据归一化
- 6、转四维数据
- 7、预测
- 8、显示图像
- 效果展示
- 代码

基础理论
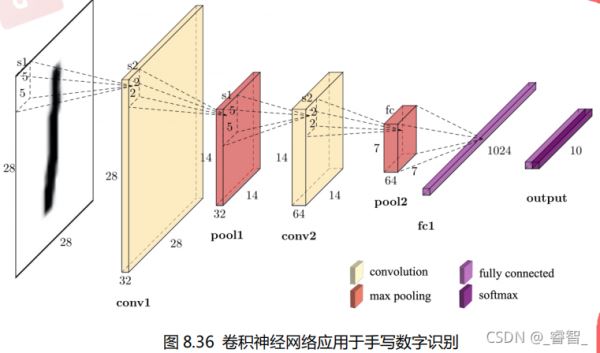
第一层:卷积层。
第二层:卷积层。
第三层:全连接层。
第四层:输出层。
图中原始的手写数字的图片是一张 28×28 的图片,并且是黑白的,所以图片的通道数是1,输入数据是 28×28×1 的数据,如果是彩色图片,图片的通道数就为 3。
该网络结构是一个 4 层的卷积神经网络(计算神经网络层数的时候,有权值的才算是一层,池化层就不能单独算一层)(池化的计算是在卷积层中进行的)。
对多张特征图求卷积,相当于是同时对多张特征图进行特征提取。

特征图数量越多说明卷积网络提取的特征数量越多,如果特征图数量设置得太少容易出现欠拟合,如果特征图数量设置得太多容易出现过拟合,所以需要设置为合适的数值。
一、训练CNN卷积神经网络
1、载入数据
# 1、载入数据 mnist = tf.keras.datasets.mnist (train_data, train_target), (test_data, test_target) = mnist.load_data()
2、改变数据维度
注:在TensorFlow中,在做卷积的时候需要把数据变成4维的格式。
这4个维度分别是:数据数量,图片高度,图片宽度,图片通道数。
# 3、归一化(有助于提升训练速度) train_data = train_data/255.0 test_data = test_data/255.0
3、归一化
# 3、归一化(有助于提升训练速度) train_data = train_data/255.0 test_data = test_data/255.0
4、独热编码
# 4、独热编码 train_target = tf.keras.utils.to_categorical(train_target, num_classes=10) test_target = tf.keras.utils.to_categorical(test_target, num_classes=10) #10种结果
5、搭建CNN卷积神经网络
model = Sequential()
5-1、第一层:第一个卷积层
第一个卷积层:卷积层+池化层。
# 5-1、第一层:卷积层+池化层 # 第一个卷积层 model.add(Convolution2D(input_shape = (28,28,1), filters = 32, kernel_size = 5, strides = 1, padding = 'same', activation = 'relu')) # 卷积层 输入数据 滤波器数量 卷积核大小 步长 填充数据(same padding) 激活函数 # 第一个池化层 # pool_size model.add(MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)) # 池化层(最大池化) 池化窗口大小 步长 填充方式
5-2、第二层:第二个卷积层
# 5-2、第二层:卷积层+池化层 # 第二个卷积层 model.add(Convolution2D(64, 5, strides=1, padding='same', activation='relu')) # 64:滤波器个数 5:卷积窗口大小 # 第二个池化层 model.add(MaxPooling2D(2, 2, 'same'))
5-3、扁平化
把(64,7,7,64)数据变成:(64,7*7*64)。
flatten扁平化:
# 5-3、扁平化 (相当于把(64,7,7,64)数据->(64,7*7*64)) model.add(Flatten())
5-4、第三层:第一个全连接层
# 5-4、第三层:第一个全连接层model.add(Dense(1024,activation = 'relu'))model.add(Dropout(0.5))
5-5、第四层:第二个全连接层(输出层)
# 5-5、第四层:第二个全连接层(输出层) model.add(Dense(10, activation='softmax')) # 10:输出神经元个数
6、编译
设置优化器、损失函数、标签。
# 6、编译 model.compile(optimizer=Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy']) # 优化器(adam) 损失函数(交叉熵损失函数) 标签
7、训练
# 7、训练 model.fit(train_data, train_target, batch_size=64, epochs=10, validation_data=(test_data, test_target))
8、保存模型
# 8、保存模型
model.save('mnist.h5')
效果:
Epoch 1/10
938/938 [==============================] - 142s 151ms/step - loss: 0.3319 - accuracy: 0.9055 - val_loss: 0.0895 - val_accuracy: 0.9728
Epoch 2/10
938/938 [==============================] - 158s 169ms/step - loss: 0.0911 - accuracy: 0.9721 - val_loss: 0.0515 - val_accuracy: 0.9830
Epoch 3/10
938/938 [==============================] - 146s 156ms/step - loss: 0.0629 - accuracy: 0.9807 - val_loss: 0.0389 - val_accuracy: 0.9874
Epoch 4/10
938/938 [==============================] - 120s 128ms/step - loss: 0.0498 - accuracy: 0.9848 - val_loss: 0.0337 - val_accuracy: 0.9889
Epoch 5/10
938/938 [==============================] - 119s 127ms/step - loss: 0.0424 - accuracy: 0.9869 - val_loss: 0.0273 - val_accuracy: 0.9898
Epoch 6/10
938/938 [==============================] - 129s 138ms/step - loss: 0.0338 - accuracy: 0.9897 - val_loss: 0.0270 - val_accuracy: 0.9907
Epoch 7/10
938/938 [==============================] - 124s 133ms/step - loss: 0.0302 - accuracy: 0.9904 - val_loss: 0.0234 - val_accuracy: 0.9917
Epoch 8/10
938/938 [==============================] - 132s 140ms/step - loss: 0.0264 - accuracy: 0.9916 - val_loss: 0.0240 - val_accuracy: 0.9913
Epoch 9/10
938/938 [==============================] - 139s 148ms/step - loss: 0.0233 - accuracy: 0.9926 - val_loss: 0.0235 - val_accuracy: 0.9919
Epoch 10/10
938/938 [==============================] - 139s 148ms/step - loss: 0.0208 - accuracy: 0.9937 - val_loss: 0.0215 - val_accuracy: 0.9924
可以发现训练10次以后,效果达到了99%+,还是比较不错的。

代码
# 手写数字识别 -- CNN神经网络训练
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Convolution2D,MaxPooling2D,Flatten
from tensorflow.keras.optimizers import Adam
# 1、载入数据
mnist = tf.keras.datasets.mnist
(train_data, train_target), (test_data, test_target) = mnist.load_data()
# 2、改变数据维度
train_data = train_data.reshape(-1, 28, 28, 1)
test_data = test_data.reshape(-1, 28, 28, 1)
# 注:在TensorFlow中,在做卷积的时候需要把数据变成4维的格式
# 这4个维度分别是:数据数量,图片高度,图片宽度,图片通道数
# 3、归一化(有助于提升训练速度)
train_data = train_data/255.0
test_data = test_data/255.0
# 4、独热编码
train_target = tf.keras.utils.to_categorical(train_target, num_classes=10)
test_target = tf.keras.utils.to_categorical(test_target, num_classes=10) #10种结果
# 5、搭建CNN卷积神经网络
model = Sequential()
# 5-1、第一层:卷积层+池化层
# 第一个卷积层
model.add(Convolution2D(input_shape = (28,28,1), filters = 32, kernel_size = 5, strides = 1, padding = 'same', activation = 'relu'))
# 卷积层 输入数据 滤波器数量 卷积核大小 步长 填充数据(same padding) 激活函数
# 第一个池化层 # pool_size
model.add(MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',))
# 池化层(最大池化) 池化窗口大小 步长 填充方式
# 5-2、第二层:卷积层+池化层
# 第二个卷积层
model.add(Convolution2D(64, 5, strides=1, padding='same', activation='relu'))
# 64:滤波器个数 5:卷积窗口大小
# 第二个池化层
model.add(MaxPooling2D(2, 2, 'same'))
# 5-3、扁平化 (相当于把(64,7,7,64)数据->(64,7*7*64))
model.add(Flatten())
# 5-4、第三层:第一个全连接层
model.add(Dense(1024, activation = 'relu'))
model.add(Dropout(0.5))
# 5-5、第四层:第二个全连接层(输出层)
model.add(Dense(10, activation='softmax'))
# 10:输出神经元个数
# 6、编译
model.compile(optimizer=Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy'])
# 优化器(adam) 损失函数(交叉熵损失函数) 标签
# 7、训练
model.fit(train_data, train_target, batch_size=64, epochs=10, validation_data=(test_data, test_target))
# 8、保存模型
model.save('mnist.h5')
二、识别自己的手写数字(图像)
1、载入数据
# 1、载入数据 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
数据集的图片(之一):

2、载入训练好的模型
# 2、载入训练好的模型
model = load_model('mnist.h5')
3、载入自己写的数字图片并设置大小
# 3、载入自己写的数字图片并设置大小
img = Image.open('6.jpg')
# 设置大小(和数据集的图片一致)
img = img.resize((28, 28))

4、转灰度图
# 4、转灰度图
gray = np.array(img.convert('L')) #.convert('L'):转灰度图

可以发现和数据集中的白底黑字差别很大,所以我们把它反转一下:
5、转黑底白字、数据归一化
MNIST数据集中的数据都是黑底白字,且取值在0~1之间。
# 5、转黑底白字、数据归一化 gray_inv = (255-gray)/255.0
6、转四维数据
CNN神经网络预测需要四维数据。
# 6、转四维数据(CNN预测需要) image = gray_inv.reshape((1,28,28,1))
7、预测
# 7、预测
prediction = model.predict(image) # 预测
prediction = np.argmax(prediction,axis=1) # 找出最大值
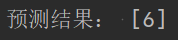
print('预测结果:', prediction)
8、显示图像
# 8、显示
# 设置plt图表
f, ax = plt.subplots(3, 3, figsize=(7, 7))
# 显示数据集图像
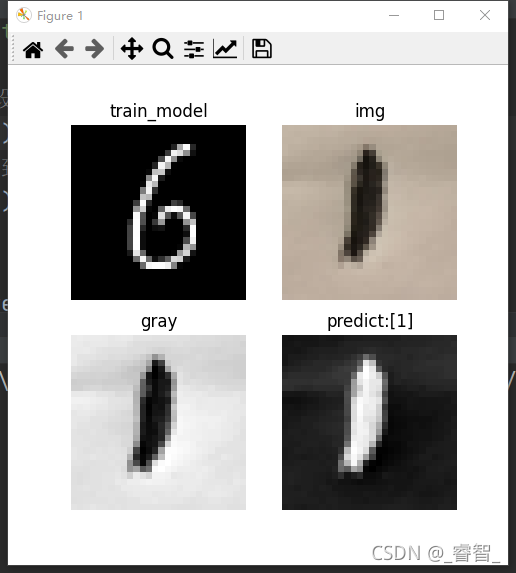
ax[0][0].set_title('train_model')
ax[0][0].axis('off')
ax[0][0].imshow(x_train[18], 'gray')
# 显示原图
ax[0][1].set_title('img')
ax[0][1].axis('off')
ax[0][1].imshow(img, 'gray')
# 显示灰度图(白底黑字)
ax[0][2].set_title('gray')
ax[0][2].axis('off')
ax[0][2].imshow(gray, 'gray')
# 显示灰度图(黑底白字)
ax[1][0].set_title('gray')
ax[1][0].axis('off')
ax[1][0].imshow(gray_inv, 'gray')
plt.show()
效果展示

代码
# 识别自己的手写数字(图像预测)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
# 1、载入数据
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 2、载入训练好的模型
model = load_model('mnist.h5')
# 3、载入自己写的数字图片并设置大小
img = Image.open('5.jpg')
# 设置大小(和数据集的图片一致)
img = img.resize((28, 28))
# 4、转灰度图
gray = np.array(img.convert('L')) #.convert('L'):转灰度图
# 5、转黑底白字、数据归一化
gray_inv = (255-gray)/255.0
# 6、转四维数据(CNN预测需要)
image = gray_inv.reshape((1,28,28,1))
# 7、预测
prediction = model.predict(image) # 预测
prediction = np.argmax(prediction,axis=1) # 找出最大值
print('预测结果:', prediction)
# 8、显示
# 设置plt图表
f, ax = plt.subplots(2, 2, figsize=(5, 5))
# 显示数据集图像
ax[0][0].set_title('train_model')
ax[0][0].axis('off')
ax[0][0].imshow(x_train[18], 'gray')
# 显示原图
ax[0][1].set_title('img')
ax[0][1].axis('off')
ax[0][1].imshow(img, 'gray')
# 显示灰度图(白底黑字)
ax[1][0].set_title('gray')
ax[1][0].axis('off')
ax[1][0].imshow(gray, 'gray')
# 显示灰度图(黑底白字)
ax[1][1].set_title(f'predict:{prediction}')
ax[1][1].axis('off')
ax[1][1].imshow(gray_inv, 'gray')
plt.show()
以上就是Python神经网络TensorFlow基于CNN卷积识别手写数字的详细内容,更多关于TensorFlow识别手写数字的资料请关注我们其它相关文章!
相关推荐
-
python tensorflow基于cnn实现手写数字识别
一份基于cnn的手写数字自识别的代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 加载数据集 mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 以交互式方式启动session # 如果不使用交互式session,则在启动s
-
Python(TensorFlow框架)实现手写数字识别系统的方法
手写数字识别算法的设计与实现 本文使用python基于TensorFlow设计手写数字识别算法,并编程实现GUI界面,构建手写数字识别系统.这是本人的本科毕业论文课题,当然,这个也是机器学习的基本问题.本博文不会以论文的形式展现,而是以编程实战完成机器学习项目的角度去描述. 项目要求:本文主要解决的问题是手写数字识别,最终要完成一个识别系统. 设计识别率高的算法,实现快速识别的系统. 1 LeNet-5模型的介绍 本文实现手写数字识别,使用的是卷积神经网络,建模思想来自LeNet-5,如下图所示
-
基于TensorFlow的CNN实现Mnist手写数字识别
本文实例为大家分享了基于TensorFlow的CNN实现Mnist手写数字识别的具体代码,供大家参考,具体内容如下 一.CNN模型结构 输入层:Mnist数据集(28*28) 第一层卷积:感受视野5*5,步长为1,卷积核:32个 第一层池化:池化视野2*2,步长为2 第二层卷积:感受视野5*5,步长为1,卷积核:64个 第二层池化:池化视野2*2,步长为2 全连接层:设置1024个神经元 输出层:0~9十个数字类别 二.代码实现 import tensorflow as tf #Tensorfl
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-

tensorflow识别自己手写数字
tensorflow作为google开源的项目,现在赶超了caffe,好像成为最受欢迎的深度学习框架.确实在编写的时候更能感受到代码的真实存在,这点和caffe不同,caffe通过编写配置文件进行网络的生成.环境tensorflow是0.10的版本,注意其他版本有的语句会有错误,这是tensorflow版本之间的兼容问题. 还需要安装PIL:pip install Pillow 图片的格式: – 图像标准化,可安装在20×20像素的框内,同时保留其长宽比. – 图片都集中在一个28×28的图像中
-
tensorflow基于CNN实战mnist手写识别(小白必看)
很荣幸您能看到这篇文章,相信通过标题打开这篇文章的都是对tensorflow感兴趣的,特别是对卷积神经网络在mnist手写识别这个实例感兴趣.不管你是什么基础,我相信,你在看完这篇文章后,都能够完全理解这个实例.这对于神经网络入门的小白来说,简直是再好不过了. 通过这篇文章,你能够学习到 tensorflow一些方法的用法 mnist数据集的使用方法以及下载 CNN卷积神经网络具体python代码实现 CNN卷积神经网络原理 模型训练.模型的保存和载入 Tensorflow实战mnist手写数字
-
Python神经网络TensorFlow基于CNN卷积识别手写数字
目录 基础理论 一.训练CNN卷积神经网络 1.载入数据 2.改变数据维度 3.归一化 4.独热编码 5.搭建CNN卷积神经网络 5-1.第一层:第一个卷积层 5-2.第二层:第二个卷积层 5-3.扁平化 5-4.第三层:第一个全连接层 5-5.第四层:第二个全连接层(输出层) 6.编译 7.训练 8.保存模型 代码 二.识别自己的手写数字(图像) 1.载入数据 2.载入训练好的模型 3.载入自己写的数字图片并设置大小 4.转灰度图 5.转黑底白字.数据归一化 6.转四维数据 7.预测 8.显示
-
Python Opencv使用ann神经网络识别手写数字功能
opencv中也提供了一种类似于Keras的神经网络,即为ann,这种神经网络的使用方法与Keras的很接近.关于mnist数据的解析,读者可以自己从网上下载相应压缩文件,用python自己编写解析代码,由于这里主要研究knn算法,为了图简单,直接使用Keras的mnist手写数字解析模块.本次代码运行环境为:python 3.6.8opencv-python 4.4.0.46opencv-contrib-python 4.4.0.46 下面的代码为使用ann进行模型的训练: from kera
-
TensorFlow教程Softmax逻辑回归识别手写数字MNIST数据集
基于MNIST数据集的逻辑回归模型做十分类任务 没有隐含层的Softmax Regression只能直接从图像的像素点推断是哪个数字,而没有特征抽象的过程.多层神经网络依靠隐含层,则可以组合出高阶特征,比如横线.竖线.圆圈等,之后可以将这些高阶特征或者说组件再组合成数字,就能实现精准的匹配和分类. import tensorflow as tf import numpy as np import input_data print('Download and Extract MNIST datas
-
Python利用逻辑回归模型解决MNIST手写数字识别问题详解
本文实例讲述了Python利用逻辑回归模型解决MNIST手写数字识别问题.分享给大家供大家参考,具体如下: 1.MNIST手写识别问题 MNIST手写数字识别问题:输入黑白的手写阿拉伯数字,通过机器学习判断输入的是几.可以通过TensorFLow下载MNIST手写数据集,通过import引入MNIST数据集并进行读取,会自动从网上下载所需文件. %matplotlib inline import tensorflow as tf import tensorflow.examples.tutori
-
Python实现识别手写数字 Python图片读入与处理
写在前面 在上一篇文章Python徒手实现手写数字识别-大纲中,我们已经讲过了我们想要写的全部思路,所以我们不再说全部的思路. 我这一次将图片的读入与处理的代码写了一下,和大纲写的过程一样,这一段代码分为以下几个部分: 读入图片: 将图片读取为灰度值矩阵: 图片背景去噪: 切割图片,得到手写数字的最小矩阵: 拉伸/压缩图片,得到标准大小为100x100大小矩阵: 将图片拉为1x10000大小向量,存入训练矩阵中. 所以下面将会对这几个函数进行详解. 代码分析 基础内容 首先我们现在最前面定义基础
-
Python实现识别手写数字大纲
写在前面 其实我之前写过一个简单的识别手写数字的程序,但是因为逻辑比较简单,而且要求比较严苛,是在50x50大小像素的白底图上手写黑色数字,并且给的训练材料也不够多,导致准确率只能五五开.所以这一次准备写一个加强升级版的,借此来提升我对Python处理文件与图片的能力. 这次准备加强难度: 被识别图片可以是任意大小: 不一定是白底图,只要数字颜色是黑色,周围环境是浅色就行: 加强识别手写数字的逻辑,提升准确率. 因为我还没开始正式写,并且最近专业课程学习也比较紧迫,所以可能更新的比较慢.不过放心
-
python实现识别手写数字 python图像识别算法
写在前面 这一段的内容可以说是最难的一部分之一了,因为是识别图像,所以涉及到的算法会相比之前的来说比较困难,所以我尽量会讲得清楚一点. 而且因为在编写的过程中,把前面的一些逻辑也修改了一些,将其变得更完善了,所以一切以本篇的为准.当然,如果想要直接看代码,代码全部放在我的GitHub中,所以这篇文章主要负责讲解,如需代码请自行前往GitHub. 本次大纲 上一次写到了数据库的建立,我们能够实时的将更新的训练图片存入CSV文件中.所以这次继续往下走,该轮到识别图片的内容了. 首先我们需要从文件夹中
-
Python实现识别手写数字 简易图片存储管理系统
写在前面 上一篇文章Python实现识别手写数字-图像的处理中我们讲了图片的处理,将图片经过剪裁,拉伸等操作以后将每一个图片变成了1x10000大小的向量.但是如果只是这样的话,我们每一次运行的时候都需要将他们计算一遍,当图片特别多的时候会消耗大量的时间. 所以我们需要将这些向量存入一个文件当中,每次先看看图库中有没有新增的图片,如果有新增的图片,那么就将新增的图片变成1x10000向量再存入文件之中,然后从文件中读取全部图片向量即可.当图库中没有新增图片的时候,那么就直接调用文件中的图片向量进