MySql各种查询方式详解
目录
- 新增
- 聚合查询
- 分组查询
- 条件查询
- 联合查询
- 自连接
- 合并查询
新增
insert into B select * from A;//将A表的信息通过查询新增到B表中去

聚合查询
count;//返回到查询的数据总和
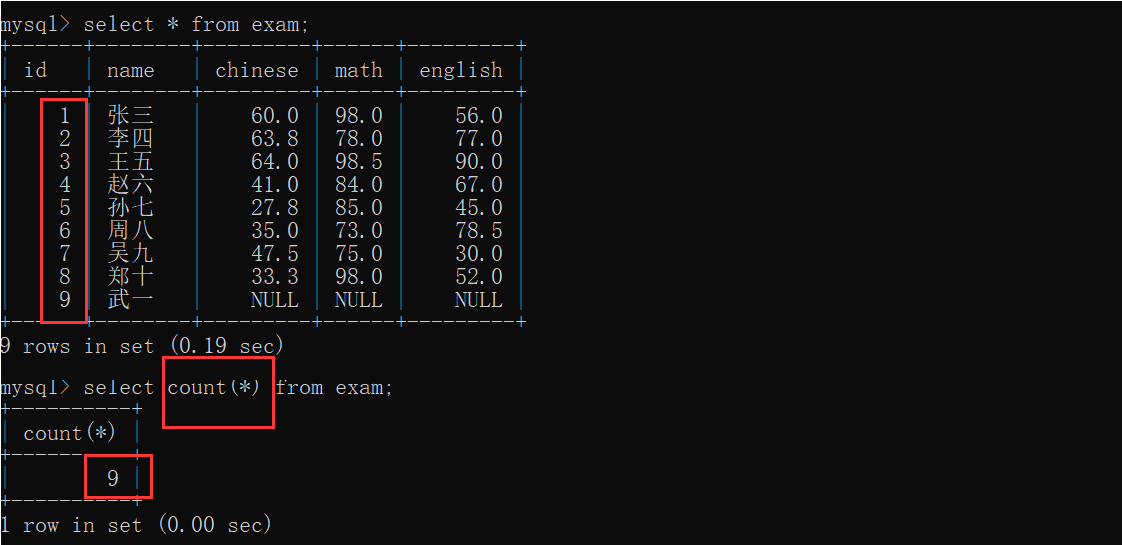
sum;//返回到查询的数据总和(只对数字有意义)

只对数字有意义

avg/max/min;//返回查询数据的平均值/最大值/最小值(只对数字有意义)

分组查询
select * from 表名 group by 分组条件;

这里是先执行分组,再根据分组执行每个组的聚合函数。
条件查询
having;
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,就可以使用having。where是在分组之前执行,如果要对分组之后的结果进行条件筛选,就需要使用having(having搭配group by使用)。
例如:求每种角色的平均薪资,除了吴九。(这里就是用where,分组之前指定条件,先去除吴九,在分组求平均薪资。

求每种角色平均薪资,只保留平均薪资10000以下的,这里就用having。要先求出平均薪资才能进行筛选。

联合查询
第一种写法:select * from 表名1,表名2;
第二种写法:select * from 表名1 join 表名2 on 条件;
联合查询(较重要)是多表查询,前面的查询都是单表查询。多表查询中的核心操作---笛卡尔积。
笛卡尔积的运算就是将两个表的每条记录分别进行组合,得到一组新的记录。

以上记录并不都是我们想要的结果,我们可以通过筛选得到我们想要的结果。


那么join on后面跟条件和 用where 跟条件有什么区别呢?
from多个表where写法叫做“内连接"。
使用 join on的写法,既可以表示内连接,还可以表示外连接。
select 列名 from 表1 inner join 表2 on条件;inner join表示是"内连接"其中inner可以省略。
select 列名 from 表1 left join 表2 on条件;左外连接。
select列from表1 right join表2 on条件;右外连接。

自连接
自连接是指在同一张表连接自身进行查询。 例如:显示所有 “ 语文 ” 成绩比 “数学” 成绩高的成绩信息。 首先要知道语文和数学这两门课程的course_id,先找到这俩门课程。然后在比较他俩高低。
select s1.student_id,s1.score,s2.score from score as s1,score as s2 where s1.student_id=s2.student_id and s1.course_id=3 and s2.course_id=1 and s1.score>s2.score;

合并查询
union;//这个可自动去重 union all;//这个不可自动去重
该操作符用于取得两个结果集的并集。
例如:查询id小于3,或者名字为“英文”的课程。
select * from course where id<3 union select * from course where name='英文';
或者使用or来实现
select * from course where id<3 or name='英文';
到此这篇关于MySql各种查询方式详解的文章就介绍到这了,更多相关MySql查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL中的连接查询(等值连接)
目录 1. 笛卡尔乘积 2. 分类 (1)按年代分类 (2)按功能分类 3. 等值连接 4. 总结 1. 笛卡尔乘积 表1有m行数据,表2有n行数据,查询结果有m*n行数据. 2. 分类 (1)按年代分类 sql92标准:仅支持内连接 sql99标准(推荐):支持内连接.外连接(左外连接和右外连接).交叉连接 (2)按功能分类 内连接:等值连接.非等值连接.自连接 外连接:左外连接.右外连接.全外连接 交叉连接 3. 等值连接 (1)查询女生名及其对应的男朋友名 SELECT girl
-

mysql拆分字符串作为查询条件的示例代码
目录 mysql.help_topic REPLACE LENGHT substring_index 分析 有个群友问一个问题 这表的ancestors列存放的是所有的祖先节点,以,分隔 例如我查询dept_id为103的所有祖先节点,现在我只有一个dept_id该怎么查 然后我去网上找到这样一个神奇的sql,改改表名就成了下面的这样 SELECT substring_index( substring_index( a.ancestors, ',', b.help_topic_id + 1 ),
-
MySQL数据库学习之去重与连接查询详解
目录 1.去重 2.连接查询 使用where进行多表连接查询 内连接 - 等值连接 内连接 - 非等值连接 内连接 - 自连接 外连接 - 左右外连接 三表连接 1.去重 示例表内容参考此文章 有些 MySQL 数据表中可能存在重复的记录,有些情况我们允许重复数据的存在,但有时候我们也需要删除这些重复的数据. 例如:去重显示岗位信息: mysql> select distinct job from emp; +-----------+ | job | +-----------+ | CLERK
-
MySQL学习之分组查询的用法详解
目录 为什么要分组 逐级分组 逐级分组对 SELECT 子句的要求 对分组结果集再次做汇总计算 GROUP_CONCAT 函数 GROUP BY 子句的执行顺序 该章节来开始学习分组查询,上一章节我们学习了聚合函数,默认统计的是全表范围内的数据,配合上 WHERE 就能够缩小统计的范围了.但是这并不能满足我们的要求,比如说我们按照之前的数据表查询每个部门的平均底薪是多少?这样的记录就需要针对部门编号进行分组了.根据分组的情况统计分组内的最大值.最小值.平均值等等.如此就能够满足刚刚提到的 “查询
-
Mysql深入了解联表查询的特点
目录 前言 一.传统方法(查询性能不佳) 二.使用union all将多个表联合成一个表查询 三.总结 前言 为了减少对数据库的查询次数,例如在互不关联的表中为了减轻系统的压力,我们可以通过union all关键词将多个表查到的数据做一个联查处理 (便于统计分析时使用到不同的数据而只用一次请求) 举例:通过一条sql语句一次查询查询学生表中的性别为男的学生总数和教师表中的教师性别为男的教师总数 数据库表准备: 1.student表 SET NAMES utf8mb4; SET FOREIGN_K
-
MySQL数据库学习之查询操作详解
目录 1.示例表内容 2.简单查询 3.给列起别名 4.列运算 5.条件查询 1.示例表内容 dept表: +--------+------------+----------+ | DEPTNO | DNAME | LOC | +--------+------------+----------+ | 10 | ACCOUNTING | NEW YORK | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS
-
MySQL提升大量数据查询效率的优化神器
目录 前言 查看SQL执行频率 定位低效率执行SQL explain分析执行计划 trace分析优化器执行计划 使用索引优化 SQL优化 大量插入数据 优化insert语句 优化order by语句 2.两种排序方式 3.Filesort 的优化 优化group by 子查询优化 limit优化 前言 在应用的的开发过程中,由于初期数据量小,开发人员写 SQL 语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多 SQL 语句开始逐渐显露出性能问题,对生产的影响也越
-
MySQL数据库之union,limit和子查询详解
目录 1.where中的子查询 2.from子句后的子查询 3.union 4.limit查询 5.分页 1.where中的子查询 示例数据参见此文章 案例:查询比最低工资高的员工姓名和薪资 子查询,先查询子查询括号里的,再向上级进行查询 mysql> select ename,sal from emp where sal -> > -> (select min(sal) from emp); +--------+---------+ | ename | sal | +------
-
Mysql子查询关键字的使用方式(exists)
目录 1. all 1.1 格式 1.2 特点 1.3 操作 2. any(some) 1.1 格式 1.2 特点 1.3 操作 3. in 1.1 格式 1.2 特点 1.3 操作 4. exist 1.1 格式 1.2 特点 1.3 操作 1.4 解释 1. all 1.1 格式 1.2 特点 all:与子查询返回的所有值比较为true则返回true all可以与=,>=,>,<,<=,<>结合使用,分别表示等于,大于等于,大于,小于,小于等于,不等于其中的所有数据
-
MySql各种查询方式详解
目录 新增 聚合查询 分组查询 条件查询 联合查询 自连接 合并查询 新增 insert into B select * from A://将A表的信息通过查询新增到B表中去 聚合查询 count://返回到查询的数据总和 sum://返回到查询的数据总和(只对数字有意义) 只对数字有意义 avg/max/min;//返回查询数据的平均值/最大值/最小值(只对数字有意义) 分组查询 select * from 表名 group by 分组条件: 这里是先执行分组,再根据分组执行每个组的聚合函数.
-
MySql连接查询方式详解
目录 1. 什么是连接查询 2. 连接查询的方式 3. 内连接 1. 等值连接 2. 非等值连接 3. 自连接 4. 外连接 1. 右外连接 2. 左外连接 5. 多张表(两张以上)连接 1. 什么是连接查询 从一张表中单独查询,称为单表查询. 跨表查询,多张表联合其来查询,称为连接查询. 2. 连接查询的方式 内连接: 等值连接 非等值连接 自连接 外连接: 左外连接(左连接) 右外连接(右连接) 当对多张表进行查询,没有任何限制的时候,返回的值是笛卡尔积 3. 内连接 1. 等值连接 查询每
-
Spring Data Jpa的四种查询方式详解
这篇文章主要介绍了Spring Data Jpa的四种查询方式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.调用接口的方式 1.基本介绍 通过调用接口里的方法查询,需要我们自定义的接口继承Spring Data Jpa规定的接口 public interface UserDao extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User> 使用这
-
MySql二进制连接方式详解
使用mysql二进制方式连接 您可以使用MySQL二进制方式进入到mysql命令提示符下来连接MySQL数据库. 实例 以下是从命令行中连接mysql服务器的简单实例: 复制代码 代码如下: [root@host]# mysql -u root -p Enter password:****** 在登录成功后会出现 mysql> 命令提示窗口,你可以在上面执行任何 SQL 语句. 以上命令执行后,登录成功输出结果如下: Welcome to the MySQL monitor. Commands
-
Mybatis-Plus时间范围查询方式详解
目录 方式一 方式二 请求方式 传参类型 方式一 通过apply方法,来实现时间范围查询,该方法可用于数据库函数,动态入参的params对应前面applySql内部的{index}部分,这样是不会有sql注入风险的,反之会有! apply(boolean condition, String applySql, Object... params) 反例: queryWrapper.apply(StrUtil.isNotBlank(serviceItemListDto.getStartTime())
-
mysql慢查询使用详解
1 慢查询定义 指mysql记录所有执行超过long_query_time参数设定的时间阈值的SQL语句.慢查询日志就是记录这些sql的日志. 2 开启慢查询日志 找到mysql配置文件my.cnf.在mysqld的下面添加 复制代码 代码如下: log-slow-queries = D:/MySQL/log/mysqld-slow-query.log #日志存在的位置.(注意权限的问题,可以不用设置,系统会给一个缺省的文件host_name-slow.log) long-query-time
-
MySQL嵌套查询实例详解
本文实例分析了MySQL嵌套查询.分享给大家供大家参考,具体如下: MySQl从4.11版后已经完全支持嵌套查询了,那么下面举些简单的嵌套查询的例子吧(源程序来自MySQL User Manual): 1. SELECT语句的子查询 语法: 复制代码 代码如下: SELECT ... FROM (subquery) AS name ... 先创建一个表: CREATE TABLE t1 (s1 INT, s2 CHAR(5), s3 FLOAT); INSERT INTO t1 VALUES (
-
Mysql自连接查询实例详解
本文实例讲述了Mysql自连接查询.分享给大家供大家参考,具体如下: 自连接查询 假想以下场景:某一电商网站想要对站内产品做层级分类,一个类别下面有若干子类,子类下面也会有别的子类.例如数码产品这个类别下面有笔记本,台式机,智能手机等:笔记本,台式机,智能手机又可以按照品牌分类:品牌又可以按照价格分类,等等.也许这些分类会达到一个很深的层次,呈现一种树状的结构.那么这些数据要怎么在数据库中表示呢?我们可以在数据库中创建两个字段来存储id和类别名称,使用第三个字段存储类别的子类或者父类的id,最后
-
MySQL连接查询实例详解
本文实例讲述了MySQL连接查询.分享给大家供大家参考,具体如下: 创建表suppliers: CREATE TABLE suppliers ( s_id int NOT NULL AUTO_INCREMENT, s_name char(50) NOT NULL, s_city char(50) NULL, s_zip char(10) NULL, s_call CHAR(50) NOT NULL, PRIMARY KEY (s_id) ) ; INSERT INTO suppliers(s_i
-
MySql日期查询语句详解
使用DATE_FORMAT方法SELECT * FROM `ler_items` WHERE DATE_FORMAT(postTime,'%Y-%m')='2013-03'注意:日期一定要用'',否则没有效果其它的一些关于mysql日期查找语句mysql> select date_format(DATE_SUB(CURDATE(), INTERVAL 7 DAY),'%y%m%d');+-------------------–+| date_format(DATE_SUB(CURDATE(),