图文详解感知机算法原理及Python实现
目录
- 写在前面
- 1.什么是线性模型
- 2.感知机概述
- 3.手推感知机原理
- 4.Python实现
- 4.1 创建感知机类
- 4.2 更新权重与偏置
- 4.3 判断误分类点
- 4.4 训练感知机
- 4.5 动图可视化
- 5.总结
写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。
本期目标:实现这样一个效果
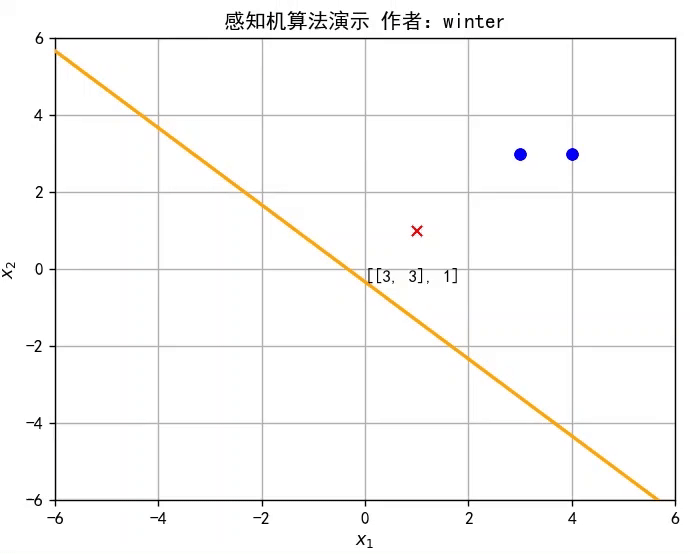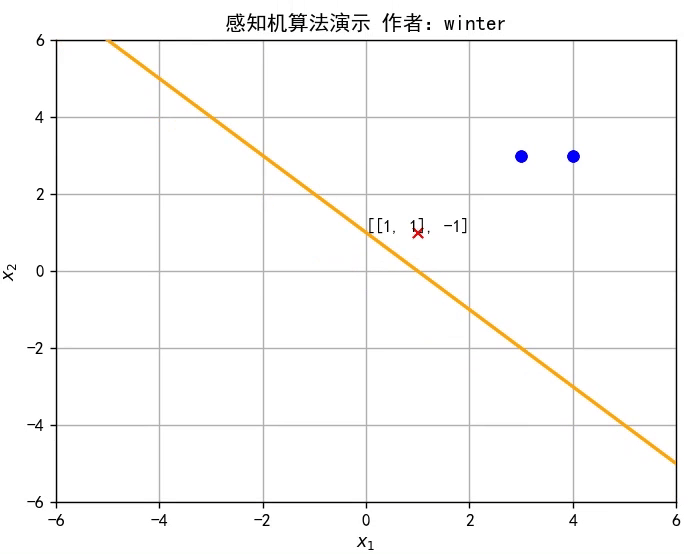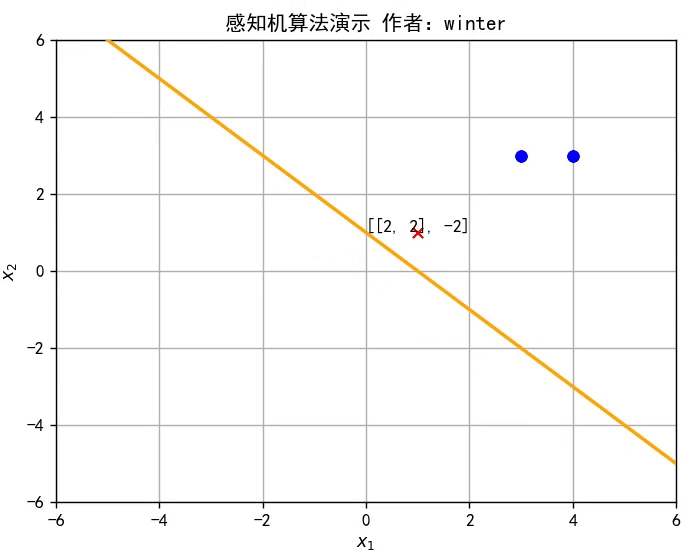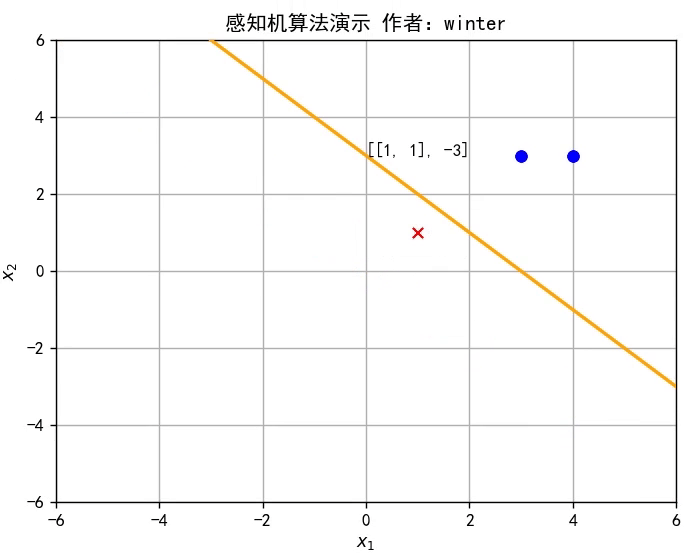
1.什么是线性模型
线性模型的假设形式是属性权重、偏置与属性的线性组合,即

称为广义线性模型(generalized linear model),其中g(⋅)称为联系函数(link function)。
广义线性模型本质上仍是线性的,但通过g(⋅)进行非线性映射,使之具有更强的拟合能力,类似神经元的激活函数。例如对数线性回归(log-linear regression)是g(⋅)=ln(⋅)时的情形,此时模型拥有了指数逼近的性质。
线性模型的优点是形式简单、易于建模、可解释性强,是更复杂非线性模型的基础。
2.感知机概述
感知机(Perceptron)是最简单的二分类线性模型,也是神经网络的起源算法,如图所示。
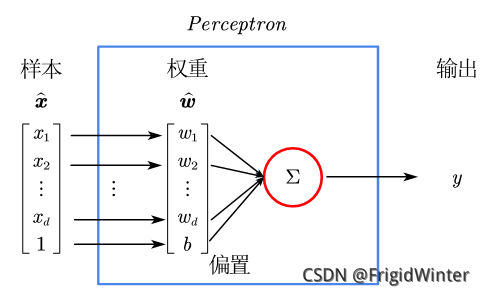
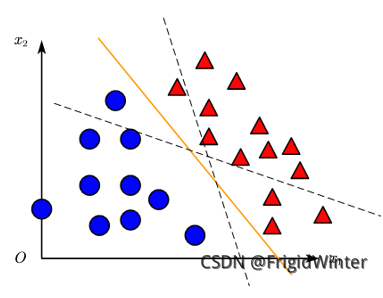
y=w^Tx^是 Rd空间的一条直线,因此感知机实质上是通过训练参数w^改变直线位置,直至将训练集分类完全,如图所示,或者参考文章开头的动图。
3.手推感知机原理
机器学习强基计划的初衷就是搞清楚每个算法、每个模型的数学原理,让我们开始吧!
感知机的损失函数定义为全体误分类点到感知机切割超平面的距离之和:

对于二分类问题y∈{−1,1},则误分类点的判断方法为


这在二分类问题中是个很常用的技巧,后面还会遇到这种等效形式。
从而损失函数也可简化为下面的形式以便于求导:

方程两边同时乘以系数都成立,所以直线系数 w^可以随意缩放,这里可令|w^|=1
若采用梯度下降法进行优化(梯度法可参考图文详解梯度下降算法的原理及Python实现),则算法流程为:

4.Python实现
4.1 创建感知机类
class Perceptron:
def __init__(self):
self.w = np.mat([0,0]) # 初始化权重
self.b = 0 # 初始化偏置
self.delta = 1 # 设置学习率为1
self.train_set = [[np.mat([3, 3]), 1], [np.mat([4, 3]), 1], [np.mat([1, 1]), -1]] # 设置训练集
self.history = [] # 训练历史
4.2 更新权重与偏置
def update(self,error_point):
self.w += self.delta*error_point[1]*error_point[0]
self.b += self.delta*error_point[1]
self.history.append([self.w.tolist()[0],self.b])
4.3 判断误分类点
def judge(self,point):
return point[1]*(self.w*point[0].T+self.b)
4.4 训练感知机
def train(self):
flag = True
while(flag):
count = 0
for point in self.train_set:
if(self.judge(point)<=0):
self.update(point)
else:
count += 1
if(count == len(self.train_set)):
flag = False
4.5 动图可视化
def show():
print("参数w,b更新过程:",perceptron.history)
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(perceptron.history),
interval=1000, repeat=False,blit=True)
plt.show()
5.总结
感知机最大的缺陷在于其线性,单个感知机只能表达一条直线,即使是如图(a)所示简单的异或门样本,都无法进行分类。对此有两种解决方式:
通过多条直线,即多层感知机(Multi-Layer Perceptron, MLP)进行分类,如图(b)所示;在线性加权的基础上引入非线性变换,如图(c)所示。

到此这篇关于图文详解感知机算法原理及Python实现的文章就介绍到这了,更多相关Python感知机算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现感知机模型的示例
from sklearn.linear_model import Perceptron import argparse #一个好用的参数传递模型 import numpy as np from sklearn.datasets import load_iris #数据集 from sklearn.model_selection import train_test_split #训练集和测试集分割 from loguru import logger #日志输出,不清楚用法 #python is a
-

Python实现感知机(PLA)算法
我们主要讲解一下利用Python实现感知机算法. 算法一 首选,我们利用Python,按照上一节介绍的感知机算法基本思想,实现感知算法的原始形式和对偶形式. #利用Python实现感知机算法的原始形式 # -*- encoding:utf-8 -*- """ Created on 2017.6.7 @author: Ada """ import numpy as np import matplotlib.pyplot as plt #1.创建数据
-
Python深度学习pytorch神经网络多层感知机简洁实现
我们可以通过高级API更简洁地实现多层感知机. import torch from torch import nn from d2l import torch as d2l 模型 与softmax回归的简洁实现相比,唯一的区别是我们添加了2个全连接层.第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数.第二层是输出层. net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 1
-
python实现感知机线性分类模型示例代码
前言 感知器是分类的线性分类模型,其中输入为实例的特征向量,输出为实例的类别,取+1或-1的值作为正类或负类.感知器对应于输入空间中对输入特征进行分类的超平面,属于判别模型. 通过梯度下降使误分类的损失函数最小化,得到了感知器模型. 本节为大家介绍实现感知机实现的具体原理代码: 运 行结果如图所示: 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对我们的支持.
-
Python机器学习多层感知机原理解析
目录 隐藏层 从线性到非线性 激活函数 ReLU函数 sigmoid函数 tanh函数 隐藏层 我们在前面描述了仿射变换,它是一个带有偏置项的线性变换.首先,回想下之前下图中所示的softmax回归的模型结构.该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作.如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法就足够了.但是,仿射变换中的线性是一个很强的假设. 我们的数据可能会有一种表示,这种表示会考虑到我们的特征之间的相关交互作用.在此表示的基础上建立
-
python感知机实现代码
本文实例为大家分享了python感知机实现的具体代码,供大家参考,具体内容如下 一.实现例子 李航<统计学方法>p29 例2.1 正例:x1=(3,3), x2=(4,3), 负例:x3=(1,1) 二.最终效果 三.代码实现 import numpy as np import matplotlib.pyplot as plt p_x = np.array([[3, 3], [4, 3], [1, 1]]) y = np.array([1, 1, -1]) plt.figure() for i
-
图文详解感知机算法原理及Python实现
目录 写在前面 1.什么是线性模型 2.感知机概述 3.手推感知机原理 4.Python实现 4.1 创建感知机类 4.2 更新权重与偏置 4.3 判断误分类点 4.4 训练感知机 4.5 动图可视化 5.总结 写在前面 机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用.“深”在详细推导算法模型背后的数学原理:“广”在分析多个机器学习模型:决策树.支持向量机.贝叶斯与马尔科夫决策.强化学习等. 本期目标:实现这样一个效果 1.什么是线性模型 线性模型的假设形式是属性权重.偏置与属性
-
详解Dijkstra算法原理及其C++实现
目录 什么是最短路径问题 Dijkstra算法 实现思路 案例分析 代码实现 什么是最短路径问题 如果从图中某一顶点(称为源点)到达另一顶点(称为终点)的路径可能不止一条,如何找到一条路径使得沿此路径上各边上的权值总和达到最小. 单源最短路径问题是指对于给定的图G=(V,E),求源点v0到其它顶点vt的最短路径. Dijkstra算法 Dijkstra算法用于计算一个节点到其他节点的最短路径.Dijkstra是一种按路径长度递增的顺序逐步产生最短路径的方法,是一种贪婪算法. Dijkstra算法
-
详解堆排序算法原理及Java版的代码实现
概述 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义如下:具有n个元素的序列(k1,k2,...,kn), 当且仅当满足: 时称之为堆.由堆的定义可以看出,堆顶元素(即第一个元素)必为最小项(小顶堆)或最大项(大顶堆). 若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点(有子女的结点)的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的. (a)大顶堆序列:(96, 83, 27, 38, 11, 09) (b)小顶堆序列:(12, 36,
-
图文详解牛顿迭代算法原理及Python实现
目录 1.引例 2.牛顿迭代算法求根 3.牛顿迭代优化 4 代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何计算函数零点x0 在数学上我们如何处理这个问题? 最简单的办法是解方程f(x)=0,在代数学上还有著名的零点判定定理 如果函数y=f(x)在区间[a,b]上的图象是连续不断的一条曲线,并且有f(a)⋅f(b)<0,那么函数y=f(x)在区间(a,b)内有零点,即至少存在一个c∈(a,b),使得f(c)=0,这个c也就是方程f(x)=0的根. 然而,数学上的方法并不一定
-
图文详解梯度下降算法的原理及Python实现
目录 1.引例 2.数值解法 3.梯度下降算法 4.代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何通过计算机算法编程求f(x)min? 2.数值解法 传统方法是数值解法,如图所示 按照以下步骤迭代循环直至最优: ① 任意给定一个初值x0: ② 随机生成增量方向,结合步长生成Δx: ③ 计算比较f(x0)与f(x0+Δx)的大小,若f(x0+Δx)<f(x0)则更新位置,否则重新生成Δx: ④ 重复②③直至收敛到最优f(x)min. 数值解法最大的优点是编程简明,但缺陷也很
-
详解Bagging算法的原理及Python实现
目录 一.什么是集成学习 二.Bagging算法 三.Bagging用于分类 四.Bagging用于回归 一.什么是集成学习 集成学习是一种技术框架,它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组"个体学习器",再用某种策略将它们结合起来,目前,有三种常见的集成学习框架(策略):bagging,boosting和stacking 也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策
-
机器学习之KNN算法原理及Python实现方法详解
本文实例讲述了机器学习之KNN算法原理及Python实现方法.分享给大家供大家参考,具体如下: 文中代码出自<机器学习实战>CH02,可参考本站: 机器学习实战 (Peter Harrington著) 中文版 机器学习实战 (Peter Harrington著) 英文原版 [附源代码] KNN算法介绍 KNN是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归.若K=1,新数据被简单分配给其近邻的类. KNN算法
-
详解K-means算法在Python中的实现
K-means算法简介 K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低. K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法.k-means 算法接受输入量 k :然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高:而不同聚类中的对象相似度较小. 核心思想 通过迭代寻找
-
SSH原理及两种登录方法图文详解
SSH(Secure Shell)是一套协议标准,可以用来实现两台机器之间的安全登录以及安全的数据传送,其保证数据安全的原理是非对称加密. 传统的对称加密使用的是一套秘钥,数据的加密以及解密用的都是这一套秘钥,可想而知所有的客户端以及服务端都需要保存这套秘钥,泄露的风险很高,而一旦秘钥便泄露便保证不了数据安全. 非对称加密解决的就是这个问题,它包含两套秘钥 - 公钥以及私钥,其中公钥用来加密,私钥用来解密,并且通过公钥计算不出私钥,因此私钥谨慎保存在服务端,而公钥可以随便传递,即使泄露也无风险.
-
通俗易懂的C++前缀和与差分算法图文详解
目录 1.前缀和 2.前缀和算法有什么好处? 3.二维前缀和 4.差分 5.一维差分 6.二维差分 1.前缀和 前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和,而差分可以看成前缀和的逆运算.合理的使用前缀和与差分,可以将某些复杂的问题简单化. 2.前缀和算法有什么好处? 先来了解这样一个问题: 输入一个长度为n的整数序列.接下来再输入m个询问,每个询问输入一对l, r.对于每个询问,输出原序列中从第l个数到第r个数的和. 我们很容易想出暴力解法,遍历区间求和. 代码如下: in