解决Mybatis 大数据量的批量insert问题
前言
通过Mybatis做7000+数据量的批量插入的时候报错了,error log如下:
,
('G61010352',
'610103199208291214',
'学生52',
'G61010350',
'610103199109920192',
'学生50',
'07',
'01',
'0104',
' ',
,
' ',
' ',
current_timestamp,
current_timestamp
)
被中止,呼叫 getNextException 以取得原因。
at org.postgresql.jdbc2.AbstractJdbc2Statement$BatchResultHandler.handleError(AbstractJdbc2Statement.java:2743) at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:411) at org.postgresql.jdbc2.AbstractJdbc2Statement.executeBatch(AbstractJdbc2Statement.java:2892) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2596) at com.alibaba.druid.wall.WallFilter.statement_executeBatch(WallFilter.java:473) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2594) at com.alibaba.druid.filter.FilterAdapter.statement_executeBatch(FilterAdapter.java:2474) at com.alibaba.druid.filter.FilterEventAdapter.statement_executeBatch(FilterEventAdapter.java:279) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2594) at com.alibaba.druid.proxy.jdbc.StatementProxyImpl.executeBatch(StatementProxyImpl.java:192) at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeBatch(DruidPooledPreparedStatement.java:559) at org.apache.ibatis.executor.BatchExecutor.doFlushStatements(BatchExecutor.java:108) at org.apache.ibatis.executor.BaseExecutor.flushStatements(BaseExecutor.java:127) at org.apache.ibatis.executor.BaseExecutor.flushStatements(BaseExecutor.java:120) at org.apache.ibatis.executor.BaseExecutor.commit(BaseExecutor.java:235) at org.apache.ibatis.executor.CachingExecutor.commit(CachingExecutor.java:112) at org.apache.ibatis.session.defaults.DefaultSqlSession.commit(DefaultSqlSession.java:196) at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:390) ... 39 more
可以看到这种异常无法捕捉,仅能看到异常指向了druid和ibatis的原码处,初步猜测是由于默认的SqlSession无法支持这个数量级的批量操作,下面就结合源码和官方文档具体看一看。
源码分析
项目使用的是Spring+Mybatis,在Dao层是通过Spring提供的SqlSessionTemplate来获取SqlSession的:
@Resource(name = "sqlSessionTemplate")
private SqlSessionTemplate sqlSessionTemplate;
public SqlSessionTemplate getSqlSessionTemplate()
{
return sqlSessionTemplate;
}
为了验证,接下看一下它是如何提供SqlSesion的,打开SqlSessionTemplate的源码,看一下它的构造方法:
/**
* Constructs a Spring managed SqlSession with the {@code SqlSessionFactory}
* provided as an argument.
*
* @param sqlSessionFactory
*/
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
this(sqlSessionFactory, sqlSessionFactory.getConfiguration().getDefaultExecutorType());
}
接下来再点开getDefaultExecutorType这个方法:
public ExecutorType getDefaultExecutorType() {
return defaultExecutorType;
}
可以看到它直接返回了类中的全局变量defaultExecutorType,我们再在类的头部寻找一下这个变量:
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
找到了,Spring为我们提供的默认执行器类型为Simple,它的类型一共有三种:
/**
* @author Clinton Begin
*/
public enum ExecutorType {
SIMPLE, REUSE, BATCH
}
仔细观察一下,发现有3个枚举类型,其中有一个BATCH是否和批量操作有关呢?我们看一下mybatis官方文档中对这三个值的描述:
- ExecutorType.SIMPLE: 这个执行器类型不做特殊的事情。它为每个语句的执行创建一个新的预处理语句。
- ExecutorType.REUSE: 这个执行器类型会复用预处理语句。
- ExecutorType.BATCH:这个执行器会批量执行所有更新语句,如果 SELECT 在它们中间执行还会标定它们是 必须的,来保证一个简单并易于理解的行为。
可以看到我的使用的SIMPLE会为每个语句创建一个新的预处理语句,也就是创建一个PreparedStatement对象,即便我们使用druid连接池进行处理,依然是每次都会向池中put一次并加入druid的cache中。这个效率可想而知,所以那个异常也有可能是insert timeout导致等待时间超过数据库驱动的最大等待值。
好了,已解决问题为主,根据分析我们选择通过BATCH的方式来创建SqlSession,官方也提供了一系列重载方法:
SqlSession openSession() SqlSession openSession(boolean autoCommit) SqlSession openSession(Connection connection) SqlSession openSession(TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType,TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType) SqlSession openSession(ExecutorType execType, boolean autoCommit) SqlSession openSession(ExecutorType execType, Connection connection)
可以观察到主要有四种参数类型,分别是
- Connection connection - ExecutorType execType - TransactionIsolationLevel level - boolean autoCommit
官方文档中对这些参数也有详细的解释:
SqlSessionFactory 有六个方法可以用来创建 SqlSession 实例。通常来说,如何决定是你 选择下面这些方法时:
Transaction (事务): 你想为 session 使用事务或者使用自动提交(通常意味着很多 数据库和/或 JDBC 驱动没有事务)?
Connection (连接): 你想 MyBatis 获得来自配置的数据源的连接还是提供你自己
Execution (执行): 你想 MyBatis 复用预处理语句和/或批量更新语句(包括插入和 删除)?
所以根据需求选择即可,由于我们要做的事情是批量insert,所以我们选择SqlSession openSession(ExecutorType execType, boolean autoCommit)
顺带一提关于TransactionIsolationLevel也就是我们经常提起的事务隔离级别,官方文档中也介绍的很到位:
MyBatis 为事务隔离级别调用使用一个 Java 枚举包装器, 称为 TransactionIsolationLevel, 否则它们按预期的方式来工作,并有 JDBC 支持的 5 级
NONE, READ_UNCOMMITTED READ_COMMITTED, REPEATABLE_READ, SERIALIZA BLE)
解决问题
回归正题,初步找到了问题原因,那我们换一中SqlSession的获取方式再试试看。
testing… 2minutes later…
不幸的是,依旧报相同的错误,看来不仅仅是ExecutorType的问题,那会不会是一次commit的数据量过大导致响应时间过长呢?上面我也提到了这种可能性,那么就再分批次处理试试,也就是说,在同一事务范围内,分批commit insert batch。具体看一下Dao层的代码实现:
@Override
public boolean insertCrossEvaluation(List<CrossEvaluation> members)
throws Exception {
// TODO Auto-generated method stub
int result = 1;
SqlSession batchSqlSession = null;
try {
batchSqlSession = this.getSqlSessionTemplate()
.getSqlSessionFactory()
.openSession(ExecutorType.BATCH, false);// 获取批量方式的sqlsession
int batchCount = 1000;// 每批commit的个数
int batchLastIndex = batchCount;// 每批最后一个的下标
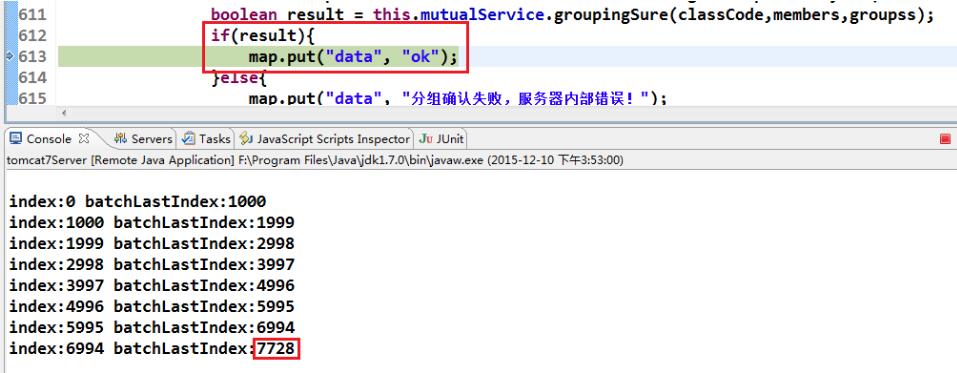
for (int index = 0; index < members.size();) {
if (batchLastIndex >= members.size()) {
batchLastIndex = members.size();
result = result * batchSqlSession.insert("MutualEvaluationMapper.insertCrossEvaluation",members.subList(index, batchLastIndex));
batchSqlSession.commit();
System.out.println("index:" + index+ " batchLastIndex:" + batchLastIndex);
break;// 数据插入完毕,退出循环
} else {
result = result * batchSqlSession.insert("MutualEvaluationMapper.insertCrossEvaluation",members.subList(index, batchLastIndex));
batchSqlSession.commit();
System.out.println("index:" + index+ " batchLastIndex:" + batchLastIndex);
index = batchLastIndex;// 设置下一批下标
batchLastIndex = index + (batchCount - 1);
}
}
batchSqlSession.commit();
}
finally {
batchSqlSession.close();
}
return Tools.getBoolean(result);
}
再次测试,程序没有报异常,总共7728条数据 insert的时间大约为10s左右,如下图所示,
总结
简单记录一下Mybatis批量insert大数据量数据的解决方案,仅供参考,Tne End。
补充:mybatis批量插入报错:','附近有错误
mybatis批量插入的时候报错,报错信息‘,'附近有错误

mapper.xml的写法为
<insert id="insertByBatch">
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES
<foreach collection="userIds" item="userId" open="(" close=")" separator=",">
(#{rateId}, #{opType}, #{content}, #{ipStr}, #{userId}, #{opTime},
</foreach>
</insert>
打印的sql语句
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES ( (?, ?, ?, ?, ?, ?) , (?, ?, ?, ?, ?, ?) )
调试的时候还是把sql复制到navicate中进行检查,就报了上面的错。这个错看起来毫无头绪,然后就自己重新写insert语句,发现正确的语句应该为
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES (?, ?, ?, ?, ?, ?) , (?, ?, ?, ?, ?, ?)
比之前的sql少了外面的括号,此时运行成功,所以mapper.xml中应该把opern=”(” close=”)”删除即可。
多说一句,批量插入的时候也可以把要插入的数据组装成List<实体>,这样就不用传这么多的参数了。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
详解mybatis plus使用insert没有返回主键的处理
项目使用springboot搭建.最初的时候是使用mybatis,后来升级到mybatis plus.按照mp的官网介绍,使用mp的insert方法,对于自增的数据库表,mp会把主键写入回实例的对应属性.但实际操作起来,却没有主键. entity 类设置如下: @TableName(value = "USERINFO") public class UserInfo { /** * 指定自增策略 */ @TableId(value = "user_id",type =
-
mybatis中insert返回值为1,但数据库却没有数据
今天在利用Mybatis框架进行数据库插入时,遇到了好几个超级奇怪的问题,也可能是我真的太菜鸡了.做个记录吧~ 1. 排除数据库中表设置错误 使用show variables like '%autocommit%';查看表是否设置自动提交 autocommit已经设置为on,无问题 2. 检查测试类代码 Test.java import entity.Data; import org.apache.ibatis.io.Resources; import org.apache.ibatis.ses
-
使用mybatis-plus的insert方法遇到的问题及解决方法(添加时id值不存在异常)
mybatis在持久层框架中还是比较火的,一般项目都是基于ssm.虽然mybatis可以直接在xml中通过SQL语句操作数据库,很是灵活.但正其操作都要通过SQL语句进行,就必须写大量的xml文件,很是麻烦. 下面给大家介绍使用mybatis-plus的insert方法遇到的问题,具体内容如下所示: 我在添加的时候,无缘无辜的给我报 java.sql.SQLException: Field 'id' doesn't have a default value 如图: 后来了解到 使用 mybati
-
mybatis insert返回主键代码实例
这篇文章主要介绍了mybatis insert返回主键代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在使用ibatis插入数据进数据库的时候,会用到一些sequence的数据,有些情况下,在插入完成之后还需要将sequence的值返回,然后才能进行下一步的操作. 使用ibatis的selectKey就可以得到sequence的值,同时也会将值返回.不过对于不同的数据库有不同的操作方式. 对于oracle: <insert id="
-
MyBatis insert操作插入数据之后返回插入记录的id
MyBatis插入数据的时候,返回该记录的id <insert id="insert" keyProperty="id" useGeneratedKeys="true" parameterType="com.demo.domain.CountRateConfig"> insert into query_rate_config (code,partner_type,search_count, booking_co
-
解决Mybatis中mapper.xml文件update,delete及insert返回值问题
最近写了几个非常简单的接口(CRUD),在单元测试的时候却出了问题,报错如下: Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'messageListener': Unsatisfied dependency expressed through field 'reviewCheckInfoService'; nested exce
-
mybatis的insert语句插入数据时的返回值的实现
mybatis的sql语句一般是配置在配置文件中,现先给出一个例子, sqlMap.xml文件中的一条插入语句: <insert id="add" parameterClass="xxx"> insert into A(a, b, c, d) VALUE (#a#, #b#, #c#, #d#) </insert> 以上的代码片段只是最简单的插入语句,上面这条SQL语句无论执行结果是成功还是失败,它的返回值都是null 如果想要在执行插入之后
-
mybatis generator只能生成insert和selectAll的操作
一般出现这个情况的时候,怎么办? 第一步:不要慌,保持冷静的思考和清醒的头脑,这很关键! 第二步:打开浏览器,搜索一下:Cannot obtain primary key information from the database, generated objects may be incomplete这个错误, 遇到这种情况的时候,代码生成器就只会生成insert和selectAll这两个方法,这个时候需要在jdbc配置的connectionURL上加上一个参数:nullCatalogMean
-

解决Mybatis 大数据量的批量insert问题
前言 通过Mybatis做7000+数据量的批量插入的时候报错了,error log如下: , ('G61010352', '610103199208291214', '学生52', 'G61010350', '610103199109920192', '学生50', '07', '01', '0104', ' ', , ' ', ' ', current_timestamp, current_timestamp ) 被中止,呼叫 getNextException 以取得原因. at org.p
-
针对Sqlserver大数据量插入速度慢或丢失数据的解决方法
我的设备上每秒将2000条数据插入数据库,2个设备总共4000条,当在程序里面直接用insert语句插入时,两个设备同时插入大概总共能插入约2800条左右,数据丢失约1200条左右,测试了很多方法,整理出了两种效果比较明显的解决办法: 方法一:使用Sql Server函数: 1.将数据组合成字串,使用函数将数据插入内存表,后将内存表数据复制到要插入的表. 2.组合成的字符换格式:'111|222|333|456,7894,7458|0|1|2014-01-01 12:15:16;1111|222
-
详解Mysql数据库平滑扩容解决高并发和大数据量问题
目录 1 停机方案 2 停写方案 3 平滑扩容之双写方案(中小型数据) 4 平滑扩容之2N方案大数据量问题解决 4.1 扩容问题 4.2 解决方案 4.3 双主架构思想 4.4 环境部署 5 数据库秒级平滑2N扩容实践 5.1 新增数据库VIP 5.2 应用服务增加动态数据源 5.3 解除原双主同步 5.4 安装MariaDB扩容服务器 5.5 增加KeepAlived服务实现高可用 5.6 清理数据并验证 1 停机方案 发布公告 停止服务 离线数据迁移(拆分,重新分配数据) 数据校验 更改配置
-
完美解决TensorFlow和Keras大数据量内存溢出的问题
内存溢出问题是参加kaggle比赛或者做大数据量实验的第一个拦路虎. 以前做的练手小项目导致新手产生一个惯性思维--读取训练集图片的时候把所有图读到内存中,然后分批训练. 其实这是有问题的,很容易导致OOM.现在内存一般16G,而训练集图片通常是上万张,而且RGB图,还很大,VGG16的图片一般是224x224x3,上万张图片,16G内存根本不够用.这时候又会想起--设置batch,但是那个batch的输入参数却又是图片,它只是把传进去的图片分批送到显卡,而我OOM的地方恰是那个"传进去&quo
-
分布式难题ElasticSearch解决大数据量检索面试
目录 引言 1.面试官: 我看你简历有写项目里有使用了ES,哪些场景用到了ES? 2.面试官: 那使用了ES后结果如何? 3.面试官: 关于ES的一些概念名字你了解多少?如索引,文档,倒排索引这些东西你是怎么理解的? 最重要的倒排索引 总结 关于ES的特性是使用场景概括: 引言 如果你的项目里有超过千万上亿级别的数据,且数据日增量较大需要高性能检索时,如订单数据,你该怎么办? 作为面试官,你需要找一个能解决这个问题的人!为应聘者,你该如何回答面试官这个问题? 你可以了解下使用搜索引擎框架,Ela
-
Mysql大数据量查询优化思路详析
目录 1. 千万级别日志查询的优化 2. 几百万黑名单库的查询优化 3. Mybatis批量插入处理问题 项目场景: Mysql大表查询优化,理论上千万级别以下的数据量Mysql单表查询性能处理都是可以的. 问题描述: 在我们线上环境中,出现了mysql几千万级别的日志查询.几百万级别的黑名单库查询分页查询及条件查询都慢的问题,针对Mysql表优化做了一些优化处理. 原因分析:首先说一下日志查询,在Mysql中如果索引加的比较合适,走索引情况下千万级别查询不会超过一秒,Mysql查询的速度和检索
-
大数据量高并发的数据库优化详解
如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. 一.数据库结构的设计 在一个系统分析.设计阶段,因为数据量较小,负荷较低.我们往往只注意到功能的实现,而很难注意到性能的薄弱之处,等到系统投入实际运行一段时间后,才发现系统的性能在降低,这时再来考虑提高系统性能则要花费更多的人力物力,而整个系统也不可避免的形成了一个打补丁工程. 所以在考虑整个系统的流程的时候,我们必须
-
在ASP.NET 2.0中操作数据之二十五:大数据量时提高分页的效率
导言 如我们在之前的教程里讨论的那样,分页可以通过两种方法来实现: 1.默认分页– 你仅仅只用选中data Web control的 智能标签的Enable Paging ; 然而,当你浏览页面的时候,虽然你看到的只是一小部分数据,ObjectDataSource 还是会每次都读取所有数据 2.自定义分页– 通过只从数据库读取用户需要浏览的那部分数据,提高了性能. 显然这种方法需要你做更多的工作. 默认的分页功能非常吸引人,因为你只需要选中一个checkbox就可以完成了.但是它每次都读取所有的
-
Java实现excel大数据量导入
本文实例为大家分享了Java实现excel大数据量导入的具体代码,供大家参考,具体内容如下 情景分析: 通常我们通过poi读取excel文件时,若在用户模式下,由于数据量较大.Sheet较多,很容易出现内存溢出的情况 用户模式读取excel的典型代码如下: FileInputStream file = new FileInputStream("c:\\test.xlsx"); Workbook wb=new XSSFWorkbook(file); 而03版(xls)excel文件每个s
-
php 大数据量及海量数据处理算法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论. 1.Bloom filter 适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集 基本原理及要点: 对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明