Python使用pyfinance包进行证券收益分析
目录
- pyfinance简介
- returns模块应用实例
- 收益率计算
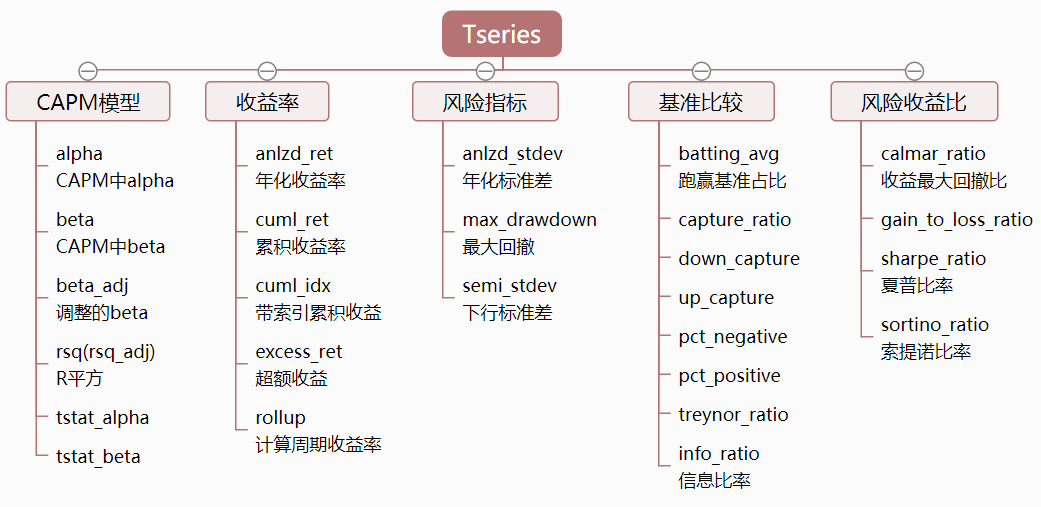
- CAPM模型相关指标
- 风险指标
- 基准比较指标
- 风险调整收益指标
- 综合业绩评价指标分析实例
- 结语
- 技术交流
pyfinance简介
datasets.py :金融数据下载(基于request进行数据爬虫,有些数据由于外网受限已经无法下载);
general.py:通用财务计算,例如主动份额计算,收益分配近似值和跟踪误差优化;
ols.py:回归分析,支持pandas滚动窗口回归;
options.py:期权衍生品计算和策略分析;
returns.py:通过CAPM框架对财务时间序列进行统计分析,旨在模拟FactSet Research Systems和Zephyr等软件的功能,并提高了速度和灵活性;
utils.py:基础架构。

本文主要围绕returns模块,介绍pyfinance在证券投资分析中的应用,后续将逐步介绍datasets、options、ols等模块。
returns模块应用实例
pyfinance的安装比较简单,直接在cmd(或anaconda prompt)上输入"pip install pyfinance"即可。returns模块主要以TSeries类为主体(暂不支持dataframe),相当于对pandas的Series进行类扩展,使其实现更多功能,支持证券投资分析中基于CAMP(资本资产定价模型)框架的业绩评价指标计算。引用returns模块时,直接使用"from pyfinance import TSeries"即可。
下面以tushare为数据接口,先定义一个数据获取函数,在函数里对收益率数据使用TSeries进行转换,之后便可以直接使用TSeries类的相关函数。
import pandas as pd
import numpy as np
from pyfinance import TSeries
import tushare as ts
def get_data(code,start='2011-01-01',end=''):
df=ts.get_k_data(code,start,end)
df.index=pd.to_datetime(df.date)
ret=df.close/df.close.shift(1)-1
#返回TSeries序列
return TSeries(ret.dropna())
#获取中国平安数据
tss=get_data('601318')
#tss.head()
收益率计算
pyfinance的returns提供了年化收益率(anlzd_ret)、累计收益率(cuml_ret)和周期收益率(rollup)等,下面以平安银行股票为例,计算收益率指标。
#年化收益率
anl_ret=tss.anlzd_ret()
#累计收益率
cum_ret=tss.cuml_ret()
#计算周期收益率
q_ret=tss.rollup('Q')
a_ret=tss.rollup('A')
print(f'年化收益率:{anl_ret*100:.2f}%')
print(f'累计收益率:{cum_ret*100:.2f}%')
#print(f'季度收益率:{q_ret.tail().round(4)}')
#print(f'历年收益率:{a_ret.round(4)}')
输出结果:
累计收益率:205.79%
年化收益率:12.24%
#可视化每个季度(年)收益率
from pyecharts import Bar
attr=q_ret.index.strftime('%Y%m')
v1=(q_ret*100).round(2).values
bar=Bar('中国平安各季度收益率%')bar.add('',attr,v1,)
bar

from pyecharts import Bar
attr=a_ret.index.strftime('%Y')
v1=(a_ret*100).round(2).values
bar=Bar('中国平安历年收益率%')
bar.add('',attr,v1,is_label_show=True,
is_splitline_show=False)
bar
CAPM模型相关指标
基于CAPM模型计算alpha、beta、回归决定系数R2、t统计量和残差项等。实际上主要使用了ols回归,因此如果要获得这些动态的alpha和beta值,可以进一步借助ols模块的滚动回归函数(PandasRollingOLS)了,这将在后续推文介绍其应用。
#以沪深300指数为基准
#为保证二者长度一致,以中国平安的索引为准
benchmark=get_data('hs300')
benchmark=benchmark.loc[tss.index]
alpha,beta,rsq=tss.alpha(benchmark),tss.beta(benchmark),tss.rsq(benchmark)
tstat_a,tstat_b=tss.tstat_alpha(benchmark),tss.tstat_beta(benchmark)
print(f'alpha:{alpha:.4f},t统计量:{tstat_a:.2f}')
print(f'beta :{beta:.4f},t统计量:{tstat_b:.2f}')
print(f'回归决定系数R2:{tss.rsq(benchmark):.3f}')
alpha:0.0004,t统计量:1.55
beta :1.0634,t统计量:60.09
回归决定系数R2:0.606
风险指标
风险指标主要包括标准差和最大回撤。在计算标准差时,注意需要修改默认参数,打开pyfinance安装包所在路径,如果是安装了Anaconda,进入以下路径:
c:\Anaconda3\Lib\site-packages\pyfinance,打开returns源文件,找到anlzd_stdev和semi_stdev函数,将freq默认None改成250(一年的交易天数)。
#年化标准差
a_std=tss.anlzd_stdev()
#下行标准差
s_std=tss.semi_stdev()
#最大回撤
md=tss.max_drawdown()
print(f'年化标准差:{a_std*100:.2f}%')
print(f'下偏标准差:{s_std*100:.2f}%')
print(f'最大回撤差:{md*100:.2f}%')
年化标准差:31.37%
下偏标准差:0.43%
最大回撤差:-45.76%
下偏标准差主要是为解决收益率分布的不对称问题,当收益率函数分布左偏的情况下,使用正态分布会低估风险,因此使用传统夏普比率分母使用全样本标准差进行估计不太合适,应使用收益对无风险投资收益的偏离。
基准比较指标
基准比较指标是需要指定一个基准(benchmark),如将沪深300指数作为中国平安个股的基准进行比较分析。
bat=tss.batting_avg(benchmark)
uc=tss.up_capture(benchmark)
dc=tss.down_capture(benchmark)
tc=uc/dc
pct_neg=tss.pct_negative()
pct_pos=tss.pct_positive()
print(f'比基准收益高的时间占比:{bat*100:.2f}%')
print(f'上行期与基准收益比:{uc*100:.2f}%')
print(f'下行期与基准收益比:{dc*100:.2f}%')
print(f'上行期与下行期比:{tc*100:.2f}%')
print(f'个股下行(收益负)时间占比:{pct_neg*100:.2f}%')
print(f'个股上行(收益正)时间占比:{pct_pos*100:.2f}%')
比基准收益高的时间占比:47.83%
上行期与基准收益比:111.70%
下行期与基准收益比:105.32%
上行期与下行期比:106.06%
个股下行(收益负)时间占比:48.94%
个股上行(收益正)时间占比:50.00%
此外,信息比率和特雷诺指数是两个常用的基准比较评价指标,特别是用于对基金产品或投资组合的业绩进行量化评价。
信息比率(information ratio):以马克维茨的均值方差模型为基础,衡量超额风险所带来的超额收益,表示单位主动风险所带来的超额收益。IR=α ∕ ω (α为组合的超额收益,ω为主动风险),分子α为真实预期收益率与定价模型所计算出的收益率的差,分母为残差风险即残差项的标准差。
特雷诺指数(Treynor ratio):衡量单位风险的超额收益,计算公式为:TR=(Rp―Rf)/βp,其中:TR表示特雷诺业绩指数,Rp表示某投资组合平均收益率,Rf为平均无风险利率,βp表示某投资组合的系统风险。
ir=tss.info_ratio(benchmark)
tr=tss.treynor_ratio(benchmark)
print(f'信息比率:{ir:.3f}')
print(f'特雷诺指数:{tr:.3f}')
信息比率:0.433
特雷诺指数:0.096
风险调整收益指标
风险调整收益率指标比较常用的有夏普比率(sharpe ratio)、索提诺比率(sortino ratio)和卡玛比率(calmar ratio),这三个指标都是风险调整后收益比率,因此分子都是收益指标,分母都是风险指标。
- 夏普比率(Sharpe Ratio):风险调整后的收益率,计算公式:=[E(Rp)-Rf]/σp,其中E(Rp):投资组合预期报酬率,Rf:无风险利率,σp:投资组合的标准差。计算投资组合每承受一单位总风险,会产生多少的超额报酬。
- 索提诺比率(Sortino Ratio):与夏普比率思路一致,核心在于分母应用了下行波动率概念(Downside Risk),计算标准差的时候,不采用均值,而是一个设定的可接受最小收益率(r_min),收益率序列中,超出这个最小收益率的收益距离按照0计算,低于这个收益率的平方距离累积,这样标准差就变成了半个下行标准差。对应的,索提诺比率的分子也采用策略收益超出最低收益的部分。与夏普比率相比,索提诺比率更看重对(左)尾部的预期损失分析,而夏普比率则是对全体样本进行分析。
- Calmar比率(Calmar Ratio) :描述收益和最大回撤之间的关系,计算方式为年化收益率与历史最大回撤之间的比率。Calmar比率数值越大,投资组合业绩表现越好。
sr=tss.sharpe_ratio()
sor=tss.sortino_ratio(freq=250)
cr=tss.calmar_ratio()
print(f'夏普比率:{sr:.2f}')
print(f'索提诺比率:{sor:.2f}')
print(f'卡玛比率:{cr:.2f}')
夏普比率:0.33
索提诺比率:28.35
卡玛比率:0.27
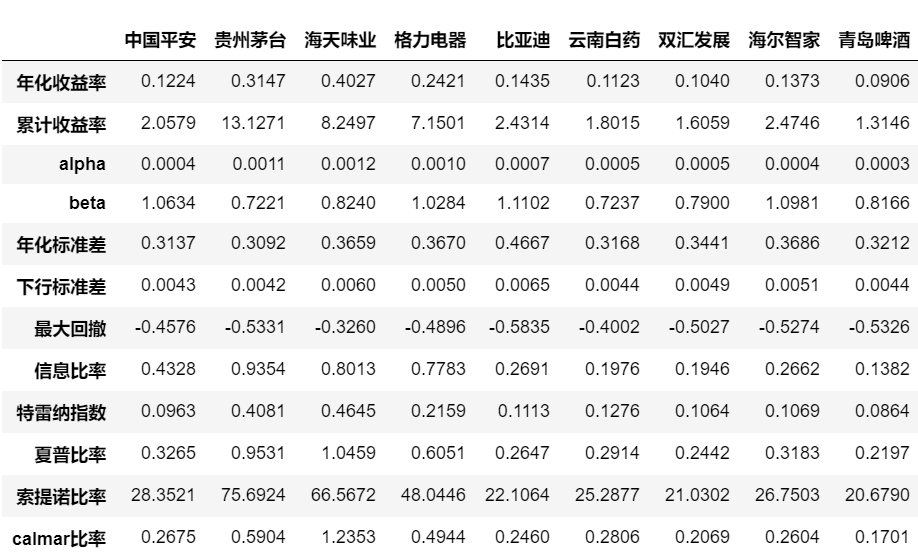
综合业绩评价指标分析实例
下面将上述常用指标进行综合,并获取多只个股进行比较分析。
def performance(code,start='2011-01-01',end=''):
tss=get_data(code,start,end)
benchmark=get_data('hs300',start,end).loc[tss.index]
dd={}
#收益率
#年化收益率
dd['年化收益率']=tss.anlzd_ret()
#累积收益率
dd['累计收益率']=tss.cuml_ret()
#alpha和beta
dd['alpha']=tss.alpha(benchmark)
dd['beta']=tss.beta(benchmark)
#风险指标
#年化标准差
dd['年化标准差']=tss.anlzd_stdev()
#下行标准差
dd['下行标准差']=tss.semi_stdev()
#最大回撤
dd['最大回撤']=tss.max_drawdown()
#信息比率和特雷诺指数
dd['信息比率']=tss.info_ratio(benchmark)
dd['特雷纳指数']=tss.treynor_ratio(benchmark)
#风险调整收益率
dd['夏普比率']=tss.sharpe_ratio()
dd['索提诺比率']=tss.sortino_ratio(freq=250)
dd['calmar比率']=tss.calmar_ratio()
df=pd.DataFrame(dd.values(),index=dd.keys()).round(4)
return df
获取多只个股(也构建投资组合)数据,对比评估业绩评价指标:
#获取多只股票数据
df=pd.DataFrame(index=performance('601318').index)
stocks={'中国平安':'601318','贵州茅台':'600519',\
'海天味业':'603288','格力电器':'000651',\
'万科A':'00002','比亚迪':'002594',\
'云南白药':'000538','双汇发展':'000895',\
'海尔智家':'600690','青岛啤酒':'600600'}
for name,code in stocks.items():
try:
df[name]=performance(code).values
except:
continue
d
结语
pyfinance主要为证券投资管理和绩效评价指标而设计的python包,对于考CFA和FRM的读者相当实用。实际上,pyfinance的returns模块是对pandas的Series类进行了扩展,从而支持证券投资收益分析和绩效评价。Python是建立在各种轮子上(module)的“胶水”语言,因此善于借用已有的包进行计算和编程,可以提高效率,减少自己“造轮子”的时间和精力。本文主要介绍了pyfinance中returns模块的应用,其他模块的应用将在后续推文中进行介绍。
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

到此这篇关于Python使用pyfinance包进行证券收益分析的文章就介绍到这了,更多相关Python pyfinance包内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析之Numpy库的使用详解
目录 前言
-
python数据分析之聚类分析(cluster analysis)
何为聚类分析 聚类分析或聚类是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上).它是探索性数据挖掘的主要任务,也是统计 数据分析的常用技术,用于许多领域,包括机器学习,模式识别,图像分析,信息检索,生物信息学,数据压缩和计算机图形学. 聚类分析本身不是一个特定的算法,而是要解决的一般任务.它可以通过各种算法来实现,这些算法在理解群集的构成以及如何有效地找到它们方面存在显着差异.流行的群集概念包括群集成员之间距离较小的群体,数据
-
Python 机器学习之线性回归详解分析
为了检验自己前期对机器学习中线性回归部分的掌握程度并找出自己在学习中存在的问题,我使用C语言简单实现了单变量简单线性回归. 本文对自己使用C语言实现单变量线性回归过程中遇到的问题和心得做出总结. 线性回归 线性回归是机器学习和统计学中最基础和最广泛应用的模型,是一种对自变量和因变量之间关系进行建模的回归分析. 代码概述 本次实现的线性回归为单变量的简单线性回归,模型中含有两个参数:变量系数w.偏置q. 训练数据为自己使用随机数生成的100个随机数据并将其保存在数组中.采用批量梯度下降法训练模型,
-
Python卷积神经网络图片分类框架详解分析
[人工智能项目]卷积神经网络图片分类框架 本次硬核分享当时做图片分类的工作,主要是整理了一个图片分类的框架,如果想换模型,引入新模型,在config中修改即可.那么走起来瓷!!! 整体结构 config 在config文件夹下的config.py中主要定义数据集的位置,训练轮数,batch_size以及本次选用的模型. # 定义训练集和测试集的路径 train_data_path = "./data/train/" train_anno_path = "./data/trai
-
利用python实现聚类分析K-means算法的详细过程
K-means算法介绍 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标. 算法过程如下: 1)从N个文档随机选取K个文档作为中心点: 2)对剩余的每个文档测量其到每个中心点的距离,并把它归到最近的质心的类: 3)重新计算已经得到的各个类的中心点: 4)迭代2-3步直至新的质心与原质心相等或小于指定阈值,算法结束. 算法优缺点: 优点: 原理简单 速度
-
Python数据分析的八种处理缺失值方法详解
目录 1. 删除有缺失值的行或列 2. 删除只有缺失值的行或列 3. 根据阈值删除行或列 4. 基于特定的列子集删除 5. 填充一个常数值 6. 填充聚合值 7. 替换为上一个或下一个值 8. 使用另一个数据框填充 总结 技术交流 在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务.欢迎收藏学习,喜欢点赞支持,技术交流可以文末加群,尽情畅聊. 让我们首先创建一个示例数据框并向其中添加一些缺失值. 我们有一个 10 行 6 列的数据框. 下一步是添加缺失
-
Python使用pyfinance包进行证券收益分析
目录 pyfinance简介 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 技术交流 pyfinance简介 datasets.py :金融数据下载(基于request进行数据爬虫,有些数据由于外网受限已经无法下载): general.py:通用财务计算,例如主动份额计算,收益分配近似值和跟踪误差优化: ols.py:回归分析,支持pandas滚动窗口回归: options.py:期权衍生品计算和策略分析:
-
python数据可视化使用pyfinance分析证券收益示例详解
目录 pyfinance简介 pyfinance包含六个模块 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 pyfinance简介 在查找如何使用Python实现滚动回归时,发现一个很有用的量化金融包--pyfinance.顾名思义,pyfinance是为投资管理和证券收益分析而构建的Python分析包,主要是对面向定量金融的现有包进行补充,如pyfolio和pandas等. pyfinance包含六个模块
-
Python模块、包(Package)概念与用法分析
本文实例讲述了Python模块.包(Package)概念与用法.分享给大家供大家参考,具体如下: Python中"模块"的概念 在开发中,我们会有很多函数,我们可以把这些函数都放到一个文件. 比如function.py中: #定义函数 def show(): print("jack") #定义变量 name = "tom" 在其他地方要使用其中的函数怎么办呢? 第一步:需要先引入 import funtions 第二步:通过文件名.函数名/变量名
-
python导入csv文件出现SyntaxError问题分析
背景 np.loadtxt()用于从文本加载数据. 文本文件中的每一行必须含有相同的数据. *** loadtxt(fname,dtype=<class'float'>,comments='#',delimiter=None,converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0) fname要读取的文件.文件名.或生成器. dtype数据类型,默认float. comments注释. delimiter分隔符,默认是空格. s
-
python通过elixir包操作mysql数据库实例代码
本文研究的主要是python通过elixir包操作mysql数据库的相关实例,具体如下. python操作数据库有很多方法,下面介绍elixir来操作数据库.elixir是对sqlalchemy lib的一个封装,classes和tables是一一对应的,能够一步定义classes,tables和mappers,支持定义多个primary key. 定义model.py from elixir import sqlalchemy from elixir import * engine =sqla
-
Python实现简单的文本相似度分析操作详解
本文实例讲述了Python实现简单的文本相似度分析操作.分享给大家供大家参考,具体如下: 学习目标: 1.利用gensim包分析文档相似度 2.使用jieba进行中文分词 3.了解TF-IDF模型 环境: Python 3.6.0 |Anaconda 4.3.1 (64-bit) 工具: jupyter notebook 注:为了简化问题,本文没有剔除停用词"stop-word".实际应用中应该要剔除停用词. 首先引入分词API库jieba.文本相似度库gensim import ji
-
Python数据分析之双色球中蓝红球分析统计示例
本文实例讲述了Python数据分析之双色球中蓝红球分析统计.分享给大家供大家参考,具体如下: 这里接着上一篇Python数据分析之获取双色球历史信息收集的数据处理下, newdata.txt数据样子 ... 2005-08-21, 05,10,23,27,28,30,15 2005-08-18, 04,05,17,18,26,33,04 2005-08-16, 09,12,18,21,28,29,05 ... 一.蓝球统计: analyze_data_lan.py #!/usr/bin/pyth
-
通过python的matplotlib包将Tensorflow数据进行可视化的方法
使用matplotlib中的一些函数将tensorflow中的数据可视化,更加便于分析 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt def add_layer(inputs, in_size, out_size, activation_function=None): Weights = tf.Variable(tf.random_normal([in_size, out_size])) bi
-
解决python 虚拟环境删除包无法加载的问题
项目开发一直在docker的虚拟环境上,遇到了一个问题,就是把虚拟环境的包删掉(rm -rf xxx)之后,再重新拷贝一个(跟原来包一模一样的文件夹)进去发现pycharm再也找不到这个包了,后来在同事的帮助下一步步的解决了这个问题: 解决流程: 1.定位问题 在虚拟环境下引入这个包: #进入虚拟环境 source bin/activate #1.进入python #2.引入报错的包 (xenwebsite-env)[root@aeb02c10de04 xenwebsite-env]# pyth
-
利用Python的folium包绘制城市道路图的实现示例
写在前面 很长一段时间内,我都在研究在线地图的开发者文档,百度地图和高德地图的开发者中心提供了丰富的在线地图服务,虽然有一定的权限限制,但不得不说,还是给我的科研工作提供了特别方便的工具,在博客前面我先放上这两个在线地图开放平台的web API的地址链接: 百度地图开放平台 高德地图开放平台 基于这两个平台,博主进行了一系列的开发研究工作,本文介绍其中一项技术,如何用folium包绘制城市道路图,当然,也可绘制非城市道路图,只要提供正确的路名就行了. 开发工具: Python3.7 Spyder