ZooKeeper框架教程Curator分布式锁实现及源码分析
目录
- 如何使用InterProcessMutex
- 实现思路
- 代码实现概述
- InterProcessMutex源码分析
- 实现接口
- 属性
- 构造方法
- 方法
- 获得锁
- 释放锁
- LockInternals源码分析
- 获取锁
- 释放锁
- 总结
ZooKeeper入门教程一简介与核心概念
ZooKeeper入门教程二在单机和集群环境下的安装搭建及使用
ZooKeeper入门教程三分布式锁实现及完整运行源码
上一篇文章中,我们使用zookeeper的java api实现了分布式排他锁。
Curator中有着更为标准、规范的分布式锁实现。与其我们自己去实现,不如直接使用Curator。通过学习Curator的源代码,我们也能了解实现分布式锁的最佳实践。
Curator中有各种分布式锁,本文挑选其中一个---InterProcessMutex进行讲解。
我们先看一下Curator代码中对于InterProcessMutex的注释:
可重入的互斥锁,跨JVM工作。使用ZooKeeper来控制锁。所有JVM中的任何进程,只要使用同样的锁路径,将会成为跨进程的一部分。此外,这个排他锁是“公平的”,每个用户按照申请的顺序得到排他锁。
可见InterProcessMutex和我们自己实现的例子都是一个排他锁,此外还可以重入。
如何使用InterProcessMutex
在分析InterProcessMutex代码前,我们先看一下它是如何使用的,下面代码简单展示了InterProcessMutex的使用:
public static void soldTickWithLock(CuratorFramework client) throws Exception {
//创建分布式锁, 锁空间的根节点路径为/curator/lock
InterProcessMutex mutex = new InterProcessMutex(client, "/curator/locks");
mutex.acquire();
//获得了锁, 进行业务流程
//代表复杂逻辑执行了一段时间
int sleepMillis = (int) (Math.random() * 2000);
Thread.sleep(sleepMillis);
//完成业务流程, 释放锁
mutex.release();
}
使用方式和我们自己编写的锁是一样的,首先通过mutex.acquire()获取锁,该方法会阻塞进程,直到获取锁,然后执行你的业务方法,最后通过 mutex.release()释放锁。
接下来我们进入正题,展开分析Curator关于分布式锁的实现:
实现思路
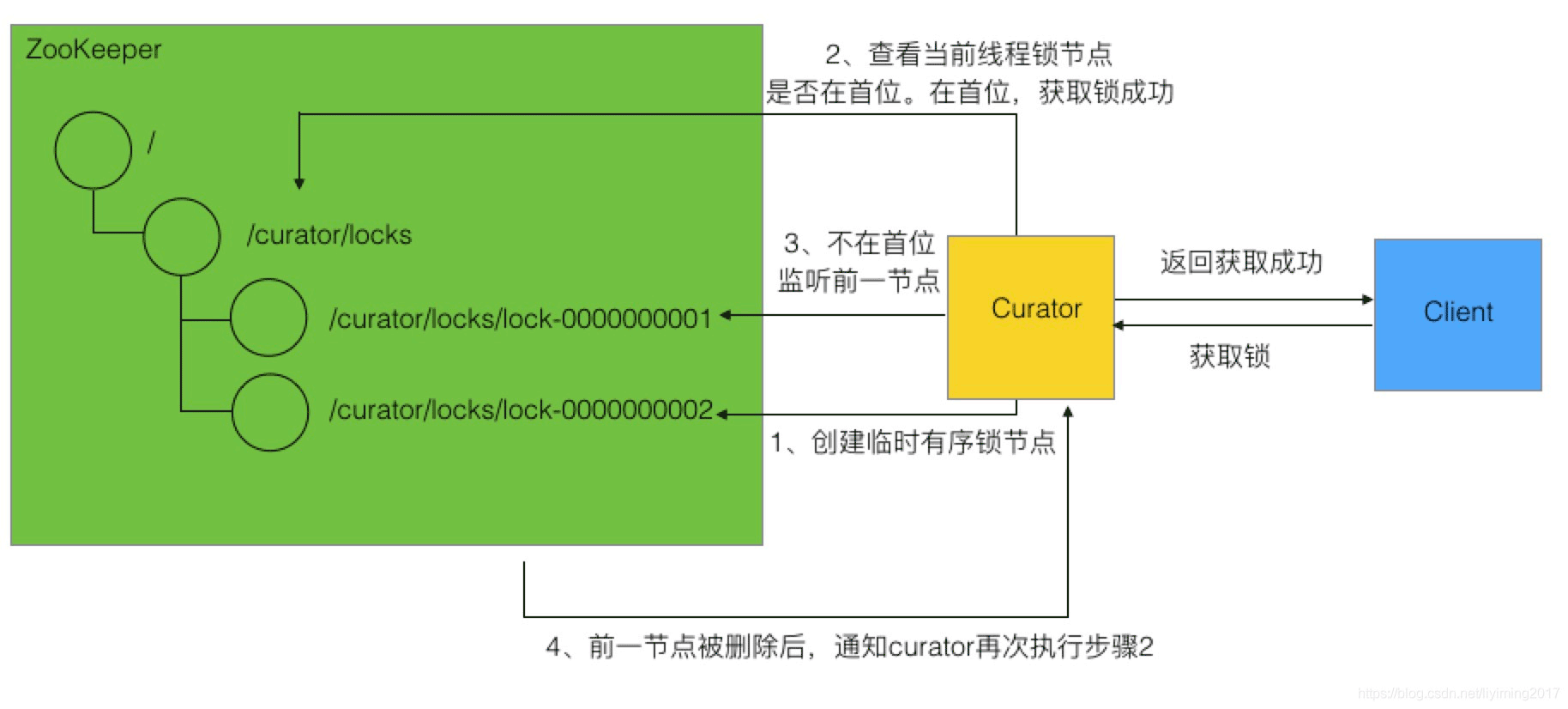
Curator设计方式和之前我们自己实现的方式是类似的:
1、创建有序临时节点
2、触发“尝试取锁逻辑”,如果自己是临时锁节点序列的第一个,则取得锁,获取锁成功。
3、如果自己不是序列中第一个,则监听前一个锁节点变更。同时阻塞线程。
4、当前一个锁节点变更时,通过watcher恢复线程,然后再次到步骤2“尝试取锁逻辑”
如下图所示:
代码实现概述
Curator对于排它锁的顶层实现逻辑在InterProcessMutex类中,它对客户端暴露锁的使用方法,如获取锁和释放锁等。但锁的上述实现逻辑,是由他持有的LockInternals对象来具体实现的。LockInternals使用StandardLockInternalsDriver类中的方法来做一些处理。
简单点解释,我们打个比方,Curator好比是一家公司承接各种业务,InterProcessMutex是老板,收到自己客户(client)的需求后,分配给自己的下属LockInternals去具体完成,同时给他一个工具StandardLockInternalsDriver,让他在做任务的过程中使用。如下图展示:

接下来我们将深入分析InterProcessMutex、LockInternals及StandardLockInternalsDriver类。
InterProcessMutex源码分析
InterProcessMutex类是curator中的排它锁类,客户端直接打交道的就是InterProcessMutex。所以我们从顶层开始,先分析InterProcessMutex。
实现接口
InterProcessMutex实现了两个接口:
public class InterProcessMutex implements InterProcessLock, Revocable<InterProcessMutex>
InterProcessLock是分布式锁接口,分布式锁必须实现接口中的如下方法:
1、获取锁,直到锁可用
public void acquire() throws Exception;
2、在指定等待的时间内获取锁。
public boolean acquire(long time, TimeUnit unit) throws Exception;
3、释放锁
public void release() throws Exception;
4、当前线程是否获取了锁
boolean isAcquiredInThisProcess();
以上方法也是InterProcessMutex暴露出来,供客户端在使用分布式锁时调用。
Revocable<T>,实现该接口的锁,锁是可以被撤销的。本编文章重点讲解锁的实现机制,关于撤销部分不做讨论。
属性
InterProcessMutex属性如下:
| 类型 | 名称 | 说明 |
| LockInternals | internals | 锁的实现都在该类中,InterProcessMutex通过此类的方法实现锁 |
| String | basePath | 锁节点在zk中的根路径 |
| ConcurrentMap<Thread, LockData> | threadData | 线程和自己的锁相关数据映射 |
| String | LOCK_NAME | 常量,值为"lock-"。表示锁节点的前缀 |
它还有一个内部静态类LockData,也是threadData中保存的value,它定义了锁的相关数据,包括锁所属线程,锁的全路径,和该线程加锁的次数(InterProcessMutex为可重入锁)。代码如下:
private static class LockData
{
final Thread owningThread;
final String lockPath;
final AtomicInteger lockCount = new AtomicInteger(1);
private LockData(Thread owningThread, String lockPath)
{
this.owningThread = owningThread;
this.lockPath = lockPath;
}
}
构造方法
InterProcessMutex有三个构造方法,根据入参不同,嵌套调用,最终调用的构造方法如下:
InterProcessMutex(CuratorFramework client, String path, String lockName, int maxLeases, LockInternalsDriver driver)
{
basePath = PathUtils.validatePath(path);
internals = new LockInternals(client, driver, path, lockName, maxLeases);
}
可见构造方法最终初始化了两个属性,basePath被设置为我们传入的值 "/curator/lock",这是锁的根节点。此外就是初始化了internals,前面说过internals是真正实现锁功能的对象。真正干活的是internals。
构造完InterProcessMutex对象后,我们看看它是如何工作的。
方法
InterProcessMutex实现InterProcessLock接口,关于分布式锁的几个方法都在这个接口中,我们看看InterProcessMutex是如何实现的。
获得锁
获得锁有两个方法,区别为是否限定了等待锁的时间长度。其实最终都是调用的私有方法internalLock()。不限定等待时长的代码如下:
public void acquire() throws Exception
{
if ( !internalLock(-1, null) )
{
throw new IOException("Lost connection while trying to acquire lock: " + basePath);
}
}
可以看到internalLock()返回false时,只可能因为连接超时,否则会一直等待获取锁。
internalLock逻辑如下:
- 取得当前线程在threadData中的lockData
- 如果存在该线程的锁数据,说明是锁重入, lockData.lockCount加1,直接返回true。获取锁成功
- 如果不存在该线程的锁数据,则通过internals.attemptLock()获取锁,此时线程被阻塞,直至获得到锁
- 锁获取成功后,把锁的信息保存到threadData中。
- 如果没能获取到锁,则返回false。
完整代码如下:
private boolean internalLock(long time, TimeUnit unit) throws Exception
{
/*
Note on concurrency: a given lockData instance
can be only acted on by a single thread so locking isn't necessary
*/
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData != null )
{
// re-entering
lockData.lockCount.incrementAndGet();
return true;
}
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if ( lockPath != null )
{
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
}
return false;
}
可以看到获取锁的核心代码是internals.attemptLock
释放锁
释放锁的方法为release(),逻辑如下:
从threadData中取得当前线程的锁数据,有如下情况:
不存在,抛出无此锁的异常
存在,而且lockCount-1后大于零,说明该线程锁重入了,所以直接返回,并不在zk中释放。
存在,而且lockCount-1后小于零,说明有某种异常发生,直接抛异常
存在,而且lockCount-1等于零,这是无重入的正确状态,需要做的就是从zk中删除临时节点,通过internals.releaseLock(),不管结果如何,在threadData中移除该线程的数据。
InterProcessMutex小结
分布式锁主要用到的是上面两个方法,InterProcessMutex还有些其他的方法,这里就不做具体讲解,可以自己看一下,实现都不复杂。
通过对InterProcessMutex的讲解,相信我们已经对锁的获得和释放有了了解,应该也意识到真正实现锁的是LockInternals类。接下来我们将重点讲解LockInternals。
LockInternals源码分析
Curator通过zk实现分布式锁的核心逻辑都在LockInternals中,我们按获取锁到释放锁的流程为指引,逐步分析LockInternals的源代码。
获取锁
在InterProcessMutex获取锁的代码分析中,可以看到它是通过internals.attemptLock(time, unit, getLockNodeBytes());来获取锁的,那么我们就以这个方法为入口。此方法的逻辑比较简单,如下:
通过driver在zk上创建锁节点,获得锁节点路径。
通过internalLockLoop()方法阻塞进程,直到获取锁成功。
核心代码如下:
ourPath = driver.createsTheLock(client, path, localLockNodeBytes); hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
我们继续分析internalLockLoop方法,获取锁的核心逻辑在此方法中。
internalLockLoop中通过while自旋,判断锁如果没有被获取,将不断的去尝试获取锁。
while循环中逻辑如下:
- 通过driver查看当前锁节点序号是否排在第一位,如果排在第一位,说明取锁成功,跳出循环
- 如果没有排在第一位,则监听自己的前序锁节点,然后阻塞线程。
当前序节点释放了锁,监听会被触发,恢复线程,此时主线程又回到while中第一步。
重复以上逻辑,直至获取到锁(自己锁的序号排在首位)。
internalLockLoop方法核心代码如下:
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock )
{
List<String> children = getSortedChildren();
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() )
{
haveTheLock = true;
}
else
{
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this)
{
try
{
// use getData() instead of exists() to avoid leaving unneeded watchers which is a type of resource leak
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
if ( millisToWait != null )
{
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 )
{
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}
else
{
wait();
}
}
catch ( KeeperException.NoNodeException e )
{
// it has been deleted (i.e. lock released). Try to acquire again
}
}
}
}
获取锁的主要代码逻辑我们到这就已经分析完了,可见和我们自己的实现还是基本一样的。此外上面提到了driver对象,也就是StandardLockInternalsDriver类,它提供了一些辅助的方法,比如说在zk创建锁节点,判断zk上锁序列第一位是否为当前锁,锁序列的排序逻辑等。我们就不具体讲解了。
释放锁
释放锁的逻辑很简单,移除watcher,删除锁节点。代码如下:
final void releaseLock(String lockPath) throws Exception
{
client.removeWatchers();
revocable.set(null);
deleteOurPath(lockPath);
}
总结
至此,Curator中InterProcessMutex的源代码分析全部完成。
简单回顾下,InterProcessMutex类封装上层逻辑,对外暴露锁的使用方法。而真正的锁实现逻辑在LockInternals中,它通过对zk临时有序锁节点的创建和监控,判断自己的锁序号是否在首位,来实现锁的获取。此外它还结合StandardLockInternalsDriver提供的方法,共同实现了排他锁。
希望大家以后多多支持我们!
相关推荐
-

微服务架构之服务注册与发现功能详解
目录 微服务的注册与发现 1.服务注册 2.服务发现 3.注册中心 4.现下的主流注册中心 4.1 Eureka 4.1.1 介绍 4.1.2 整体架构 4.1.3 接入Spring Cloud 4.2 ZooKeeper 4.2.1 介绍 4.2.2 整体架构 4.2.3 接入Dubbo生态 4.3 Consul 4.3.1 介绍 4.3.2 整体架构 4.3.3 生态对接 4.4 总结对比 详解微服务架构及其演进史 微服务全景架构全面瓦解 微服务架构拆分策略详解 微服务的注册与发现 我们前面
-
zookeeper服务优化的一些建议
1.快照文件和事务日志文件分别挂在不同磁盘.zoo.cfg文件中,dataDir是存放快照数据的,dataLogDir是存放事务日志的.zookeeper更新操作过程:先写事务日志,再写内存,周期性落到磁盘(刷新内存到快照文件).事务日志的对写请求的性能影响很大,保证dataLogDir所在磁盘性能良好.没有竞争者. 2. 默认jvm没有配置Xmx.Xms等信息,可以在conf目录下创建java.env文件(内存堆空间一定要小于机器内存,避免使用swap) export JVMFLAGS="-X
-
ZooKeeper的安装及部署教程
一.Zookeeper介绍 •是一个针对大型分布式系统的可靠协调系统: •提供的功能包括:配置维护.名字服务.分布式同步.组服务等: •目标就是封装好复杂易出错的关键职务,将简单易用的接口和性能高效.功能稳定的系统提供给用户: •Zookeeper已经成为Hadoop生态系统中的基础组件. 二.Zookeeper特点 •最终一致性:为客户端展示同一视图,这是Zookeeper最重要的性能: •可靠性:如果消息被一台服务器接受,那么它将被所有的服务器接受: •原子性:更新只能成功或失败,没有中间状
-
ZooKeeper入门教程三分布式锁实现及完整运行源码
目录 1.0版本 2.0版本 LockSample类 构造方法 获取锁实现 createLock() attemptLock() 释放锁实现 TicketSeller类 sell() sellTicketWithLock() 测试入口 测试方法 代码清单如下: 1.LockSample 2.TicketSeller ZooKeeper入门教程一简介与核心概念 ZooKeeper入门教程二在单机和集群环境下的安装搭建及使用 1.0版本 首先我们先介绍一个简单的zookeeper实现分布式锁的思路:
-
zookeeper概述图文详解
1.1 概述 分布式系统:分布式系统指由很多台计算机组成的一个整体!这个整体一致对外,并且处理同一请求!系统对内透明,对外不透明!内部的每台计算机,都可以相互通信,例如使用RPC/REST或者是WebService!客户端向一个分布式系统发送的一次请求到接受到响应,有可能会经历多台计算机! Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目,多用作为集群提供服务的中间件! Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责
-
ZooKeeper入门教程一简介与核心概念
目录 1.ZooKeeper介绍与核心概念 1.1 简介 1.2分布式系统面临的问题 1.通过网络进行信息共享 2.通过共享存储 1.3 ZooKeeper如何解决分布式系统面临的问题 1.4 zookeeper概念介绍 1.4.1 znode 1.4.2 观察与通知 1.4.3 版本 1.4.4 法定人数 1.4.5 会话 1.4.6 会话状态和生命周期 回顾总结 本章是后续学习的基石,只有充分理解了分布式系统的概念和面临的问题,以及ZooKeeper内部的概念,才能懂得ZooKeeper是如
-
ZooKeeper开发实际应用案例实战
目录 项目背景介绍 面临问题 如何解决 代码讲解 数据服务器 检索服务器 总结 附:完整代码 数据服务端代码 检索服务端代码 项目背景介绍 首先给大家介绍一下本文描述项目的情况.这是一个检索网站,它让你能在几千万份复杂文档数据中检索出你所需要的文档数据.为了加快检索速度,项目的数据分布在100台机器的内存里,我们称之为数据服务器.除了数据,这100台机器上均部署着检索程序.这些server之外,还有数台给前端提供接口的搜索server,这些机器属一个集群,我们称之为检索服务器.当搜索请求过来时,
-
ZooKeeper框架教程Curator分布式锁实现及源码分析
目录 如何使用InterProcessMutex 实现思路 代码实现概述 InterProcessMutex源码分析 实现接口 属性 构造方法 方法 获得锁 释放锁 LockInternals源码分析 获取锁 释放锁 总结 ZooKeeper入门教程一简介与核心概念 ZooKeeper入门教程二在单机和集群环境下的安装搭建及使用 ZooKeeper入门教程三分布式锁实现及完整运行源码 上一篇文章中,我们使用zookeeper的java api实现了分布式排他锁. Curator中有着更为标准.规
-
Netty分布式NioEventLoop任务队列执行源码分析
目录 执行任务队列 跟进runAllTasks方法: 我们跟进fetchFromScheduledTaskQueue()方法 回到runAllTasks(long timeoutNanos)方法中 章节小结 前文传送门:NioEventLoop处理IO事件 执行任务队列 继续回到NioEventLoop的run()方法: protected void run() { for (;;) { try { switch (selectStrategy.calculateStrategy(selectN
-
pytorch教程resnet.py的实现文件源码分析
目录 调用pytorch内置的模型的方法 解读模型源码Resnet.py 包含的库文件 该库定义了6种Resnet的网络结构 每种网络都有训练好的可以直接用的.pth参数文件 Resnet中大多使用3*3的卷积定义如下 如何定义不同大小的Resnet网络 定义Resnet18 定义Resnet34 Resnet类 网络的forward过程 残差Block连接是如何实现的 调用pytorch内置的模型的方法 import torchvision model = torchvision.models
-
Java集合框架源码分析之LinkedHashMap详解
LinkedHashMap简介 LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同. LinkedHashMap可以用来实现LRU算法(这会在下面的源码中进行分析). LinkedHashMap同样是非线程安全的,只在单线程环境下使用. LinkedHashMap源码剖析 LinkedHashM
-
MySQL InnoDB 事务锁源码分析
目录 1. Lock 与 Latch 2. Repeatable Read 3. Insert加锁流程 3.1 lock mode 3.2 加锁流程 3.3 隐式锁 4. Select 加锁流程 本文前提: 代码MySQL 8.0.13 只整理Repeatable Read当前读.Read Committed简单很多,另外快照读是基于MVCC不用加锁,所以不在本文讨论范畴. 1. Lock 与 Latch InnoDB 中的lock是事务中对访问/修改的record加的锁,它一般是在事务提交或回
-
深入理解框架背后的原理及源码分析
目录 问题1 问题2 总结 近期团队中同学遇到几个问题,想在这儿跟大家分享一波,虽说不是很有难度,但是背后也折射出一些问题,值得思考. 开始之前先简单介绍一下我所在团队的技术栈,基于这个背景再展开后面将提到的几个问题,将会有更深刻的体会. 控制层基于SpringMvc,数据持久层基于JdbcTemplate自己封装了一套类MyBatis的Dao框架,视图层基于Velocity模板技术,其余组件基于SpringCloud全家桶. 问题1 某应用发布以后开始报数据库连接池不够用异常,日志如下: co
-
分布式Netty源码分析EventLoopGroup及介绍
目录 EventLoopGroup介绍 功能1:先来看看注册Channel 功能2:执行一些Runnable任务 EventLoop介绍 NioEventLoop介绍 EpollEventLoop介绍 后续 EventLoopGroup介绍 在前面一篇文章中提到了,EventLoopGroup主要负责2个事情,这里再重复下: 它主要包含2个方面的功能,注册Channel和执行一些Runnable任务. 功能1:先来看看注册Channel 即将Channel注册到Selector上,由Select
-
分布式Netty源码分析概览
目录 服务器端demo EventLoopGroup介绍 功能1:先来看看注册Channel 功能2:执行一些Runnable任务 ChannelPipeline介绍 bind过程 sync介绍 误区 4 后续 服务器端demo 看下一个简单的Netty服务器端的例子 public static void main(String[] args){ EventLoopGroup bossGroup=new NioEventLoopGroup(1); EventLoopGroup workerGro
-
Netty分布式server启动流程Nio创建源码分析
目录 NioServerSocketChannel创建 继承关系 绑定端口 端口封装成socket地址对象 跟进initAndRegister()方法 创建channel 父类的构造方法 将jdk的channel设置为非阻塞模式 前文传送门 Netty分布式Server启动流程服务端初始化源码分析 NioServerSocketChannel创建 我们如果熟悉Nio, 则对channel的概念则不会陌生, channel在相当于一个通道, 用于数据的传输 Netty将jdk的channel进行了