彻底弄懂Redis的LRU淘汰策略
目录
- Redis的淘汰策略
- LRU算法简介
- 实现思想推导
- 巧用LinkedHashMap
- 手写LRU
- 第一步:构建DoubleLinkedList对象
- 第二步:构建节点
- 第三步:初始化DoubleLinkedList对象
- 第四步:LRU对象属性
- 第五步:LRU对象的方法
- 第六步:测试
- 总结
今天我们这篇文章的目的是要 搞懂LRU淘汰策略 以及 实现一个LRU算法 。
文章会结合图解循序渐进的讲解,跟着我的思路慢慢来就能看懂,我们开始吧。
文章导读

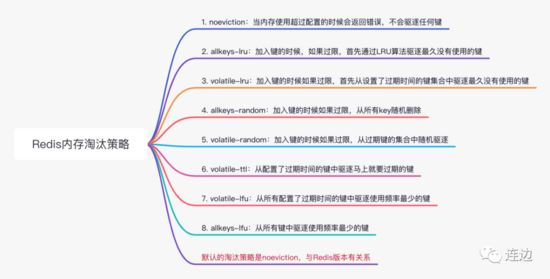
Redis的淘汰策略
为什么要有淘汰策略呢?
因为存储内存的空间是有限的,所以需要有淘汰的策略。
Redis的清理内存淘汰策略有哪些呢?
LRU算法简介
LRU是 Least Recently Used 的缩写,即 最近最少使用 ,是一种常见的页面置换算法。
我们手机的后台窗口(苹果手机双击Home的效果),他总是会把最近常用的窗口放在最前边,而最不常用的应用窗口,就排列在后边了,如果再加上只能放置N个应用窗口的限制,淘汰最不常用的最近最少用的应用窗口,那就是一个活生生的 LRU 。

实现思想推导

手机应用案例
从上边的示意图,我们可以分析出这么几个点:
- 有序;
- 如果应用开满3个了,要淘汰最不常用的应用,每次新访问应用,需要把数据插入队头(按照业务可以设定左右哪一边是队头);
- O(1)复杂度是我们查找数据的追求,我们什么结构能够实现快速的O(1)查找呢?

推导图
通过上边的推导,我们就能得出, LRU 算法核心是 HashMap + DoubleLinkedList 。
思想搞明白了,我们接下来编码实现。
巧用LinkedHashMap
我们查看Java的 LinkedHashMap 使用说明。

LinkedHashMap使用说明
翻译:这种Map结构很适合构建LRU缓存。
继承 LinkedHashMap 实现 LRU 算法:
public class LRUDemo<K, V> extends LinkedHashMap<K, V> {
private int capacity;
public LRUDemo(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
LRUDemo lruDemo = new LRUDemo(3);
lruDemo.put(1, "a");
lruDemo.put(2, "b");
lruDemo.put(3, "c");
System.out.println(lruDemo.keySet());
lruDemo.put(4, "d");
lruDemo.put(5, "e");
System.out.println(lruDemo.keySet());
}
}
重点讲解:
构造方法: super(capacity, 0.75F, true) ,主要看第三个参数:

order参数
true -> access-order // false -> insertion-order 即按照访问时间排序,还是按照插入的时间来排序
// 构造方法改成false
super(capacity, 0.75F, false);
// 使用示例
public static void main(String[] args) {
LRUDemo lruDemo = new LRUDemo(3);
lruDemo.put(1, "a");
lruDemo.put(2, "b");
lruDemo.put(3, "c");
System.out.println(lruDemo.keySet());
lruDemo.put(1, "y");
// 构造方法order=true,输出:[2,3,1],
// 构造方法order=false,输出:[1,2,3],
System.out.println(lruDemo.keySet());
}
removeEldestEntry 方法:什么时候移除最年长的元素。
通过上面,相信大家对 LRU 算法有所理解了,接下来我们不依赖JDK的 LinkedHashMap ,通过我们自己的理解,动手实现一个 LRU 算法,让我们的 LRU 算法刻入我们的大脑。
手写LRU
上边的推导图中可以看出,我们用 HashMap 来做具体的数据储存,但是我们还需要构造一个 DoubleLinkedList 对象(结构体)来储存 HashMap 的具体 key 顺序关系。
第一步:构建DoubleLinkedList对象
所以我们现在 第一步 ,就是构建一个 DoubleLinkedList 对象:

DoubleLinkedList示意图
我们可以从 HashMap 源码中找一些灵感,他们都是使用一个 Node 静态内部类来储存节点的值。
第二步:构建节点
通过上边的示意图,我们可以得知 节点 应该要储存的内容:
- key
- value
- prev节点
- next节点
翻译成代码:
class Node<K, V> {
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev = this.next = null;
}
}
第三步:初始化DoubleLinkedList对象

DoubleLinkedList初始化示意图
还是通过上边的示意图,我们可以得知 DoubleLinkedList对象 应该要储存的内容:
- 头节点
- 尾节点
翻译成代码:
class DoubleLinkedList<K, V> {
Node<K, V> head;
Node<K, V> tail;
// 构造方法
public DoubleLinkedList(){
head = new Node<>();
tail = new Node<>();
head.next = tail;
tail.prev = head;
}
}
从头添加节点

从头添加节点
翻译成代码:
public void addHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
删除节点

删除节点
翻译成代码:
public void removeNode(Node<K, V> node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
获取最后一个节点
public Node getLast() {
return tail.prev;
}
第四步:LRU对象属性
cacheSize
private int cacheSize;
map
Map<Integer, Node<Integer, String>> map;
doubleLinkedList
DoubleLinkedList<Integer, String> doubleLinkedList;
第五步:LRU对象的方法
构造方法
public LRUDemo(int cacheSize) {
this.cacheSize = cacheSize;
map = new HashMap<>();
doubleLinkedList = new DoubleLinkedList<>();
}
refreshNode刷新节点
public void refreshNode(Node node) {
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
}
get节点
public String get(int key) {
if (!map.containsKey(key)) {
return "";
}
Node<Integer, String> node = map.get(key);
refreshNode(node);
return node.value;
}
put节点
public void put(int key, String value) {
if (map.containsKey(key)) {
Node<Integer, String> node = map.get(key);
node.value = value;
map.put(key, node);
refreshNode(node);
} else {
if (map.size() == cacheSize) {
Node lastNode = doubleLinkedList.getLast();
map.remove(lastNode.key);
doubleLinkedList.removeNode(lastNode);
}
Node<Integer, String> newNode = new Node<>(key, value);
map.put(key, newNode);
doubleLinkedList.addHead(newNode);
}
}
第六步:测试
public static void main(String[] args) {
LRUDemo lruDemo = new LRUDemo(3);
lruDemo.put(1, "美团");
lruDemo.put(2, "微信");
lruDemo.put(3, "抖音");
lruDemo.put(4, "微博");
System.out.println(lruDemo.map.keySet());
System.out.println(lruDemo.get(2));
}
总结
LRU 算法到这里就写完啦,完整的代码可以从阅读原文的链接地址获取。
到此这篇关于彻底弄懂Redis的LRU淘汰策略的文章就介绍到这了,更多相关Redis LRU淘汰策略内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Redis中LRU淘汰策略的深入分析
前言 Redis作为缓存使用时,一些场景下要考虑内存的空间消耗问题.Redis会删除过期键以释放空间,过期键的删除策略有两种: 惰性删除:每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键:如果没有过期,就返回该键. 定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键. 另外,Redis也可以开启LRU功能来自动淘汰一些键值对. LRU算法 当需要从缓存中淘汰数据时,我们希望能淘汰那些将来不可能再被使用的数据,保留那些将来还会频繁访问的数据,但最大的问题是
-

彻底弄懂Redis的LRU淘汰策略
目录 Redis的淘汰策略 LRU算法简介 实现思想推导 巧用LinkedHashMap 手写LRU 第一步:构建DoubleLinkedList对象 第二步:构建节点 第三步:初始化DoubleLinkedList对象 第四步:LRU对象属性 第五步:LRU对象的方法 第六步:测试 总结 今天我们这篇文章的目的是要 搞懂LRU淘汰策略 以及 实现一个LRU算法 . 文章会结合图解循序渐进的讲解,跟着我的思路慢慢来就能看懂,我们开始吧. 文章导读 Redis的淘汰策略 为什么要有淘汰策略呢? 因
-
Redis 的内存淘汰策略和过期删除策略的区别
目录 前言 过期删除策略 如何设置过期时间? 如何判定 key 已过期了? 过期删除策略有哪些? Redis 过期删除策略是什么? 内存淘汰策略 如何设置 Redis 最大运行内存? Redis 内存淘汰策略有哪些? LRU 算法和 LFU 算法有什么区别? 总结 前言 Redis 是可以对 key 设置过期时间的,因此需要有相应的机制将已过期的键值对删除,而做这个工作的就是过期键值删除策略. Redis 的「内存淘汰策略」和「过期删除策略」,很多小伙伴容易混淆,这两个机制虽然都是做删除的操作,
-
浅谈Redis中的内存淘汰策略和过期键删除策略
目录 8种淘汰策略 过期键的删除策略 总结 redis是我们现在最常用的一个工具,帮助我们建设系统的高可用,高性能. 而且我们都知道redis是一个完全基于内存的工具,这也是redis速度快的一个原因,当我们往redis中不断缓存数据的时候,其内存总有满的时候(而且内存是很贵的东西,尽量省着点用),所以尽可能把有用的数据,或者使用频繁的数据缓存在redis中,物尽其用. 那么如果正在使用的redis内存用完了,我们应该怎么取舍redis中已存在的数据和即将要存入的数据呢,我们要怎么处理呢? re
-
Redis过期删除策略与内存淘汰策略
目录 过期删除策略 设置Redis中key的过期时间 (单位:秒) 常见的三种过期删除策略 Redis使用用的过期删除策略 Redis的定期删除的流程 内存淘汰策略 设置Redis最大运行内存 Redis 内存淘汰策略有哪些? LRU 算法和 LFU 算法有什么区别? Redis 是如何实现 LRU 算法的? 什么是 LFU 算法? Redis 是如何实现 LFU 算法的? 过期删除策略 过期删除策略: redis可以对key设置过期时间,因此要有相应的机制将已过期的键值对删除. 设置Redis
-
关于redis Key淘汰策略的实现方法
1 配置文件中的最大内存删除策略 在redis的配置文件中,可以设置redis内存使用的最大值,当redis使用内存达到最大值时(如何知道已达到最大值?),redis会根据配置文件中的策略选取要删除的key,并删除这些key-value的值.若根据配置的策略,没有符合策略的key,也就是说内存已经容不下新的key-value了,但此时有不能删除key,那么这时候写的话,将会出现写错误. 1.1 最大内存参数设置 若maxmemory参数设置为0,则分两种情况: *在64位系统上,表示没有限制.
-
浅谈Redis缓存有哪些淘汰策略
目录 Redis过期策略 定时删除 惰性删除 定期删除 Redis的内存淘汰机制 LRU和LFU的区别 LRU LFU Redis重启如何恢复数据呢? 总结 Redis过期策略 我们首先来了解一下Redis的内存淘汰机制. 定时删除 概述 redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除.注意这里是随机抽取的.为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会
-
深入理解Redis内存淘汰策略
目录 一.内存回收 二.设置内存 三.内存淘汰策略 四.LRU 4.1 LRU算法 4.2 redis中的LRU算法 五.LFU 一.内存回收 长时间不使用的缓存 降低IO性能 物理内存不够 很多人了解了Redis的好处之后,于是把任何数据都往Redis中放,如果使用不合理很容易导致数据超过Redis的内存,这种情况会出现什么问题呢? Redis中有很多无效的缓存,这些缓存数据会降低数据IO的性能,因为不同的数据类型时间复杂度算法不同,数据越多可能会造成性能下降 随着系统的运行,redis的数据
-
Redis 缓存淘汰策略和事务实现乐观锁详情
目录 缓存淘汰策略 标题LRU原理 标题Redis缓存淘汰策略 设置最大缓存 淘汰策略 Redis事务 Redis事务介绍 MULTI EXEC DISCARD WATCH Redis 不支持事务回滚(为什么呢) Redis乐观锁 Redis乐观锁实现秒杀 缓存淘汰策略 标题LRU原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. 最常见的实现是使用一个链表保存缓存数据,
-
浅谈redis的maxmemory设置以及淘汰策略
redis的maxmemory参数用于控制redis可使用的最大内存容量.如果超过maxmemory的值,就会动用淘汰策略来处理expaire字典中的键. 关于redis的淘汰策略: Redis提供了下面几种淘汰策略供用户选择,其中默认的策略为noeviction策略: · noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错. · allkeys-lru:在主键空间中,优先移除最近未使用的key. · volatile-lru:在设置了过期时间的键空间中,优