Python实现数据地址实体抽取
目录
- 一、数据地址实体抽取的目的及问题
- 二、方法一:调用ahocorasick库
- ahocorasick安装:
- ahocorasick使用:
- 三、方法一:调用cpca库
- 1、安装cpca库
- 2、cpca库使用方法
- 3、执行结果
- 总结
一、数据地址实体抽取的目的及问题
对数据的地址进行实体识别,主要作用是确定我们的数据主体最终可以归到哪一行政单位,从而在各行政单位上对数据主体的归属问题进行判断。
因何原因使用实体抽取:
例如原始数据所提供的信息为**省**市(地级)**市(县级)**镇,数据处理上,要对数据的省、地级市、县级市等信息进行单独抽取。
上述为标准的提供数据,但有时会出现:**省**市(县级市),或者**市(县级),这时候就要对数据进行补齐工作,补充该县级市所属的地级市、省。
其次,还有写出**省**市(地级市)的情况,没有写明县级市,如果以县级市进行对其,非实体抽取方式可能会将地级市与省份信息后移一位。
二、方法一:调用ahocorasick库
ahocorasick是个python模块,Aho-Corasick算法是多模式匹配中的经典算法,目前在实际应用中较多。
ahocorasick安装:
1、确定安装VC++,安装后,在模块选择里勾选Visual Studio Build Tools里面的C++ Build Tools
2、执行pip安装命令
pip install pyahocorasick
(若该方法安装失败,可尝试CSDN中其他安装方法)
ahocorasick使用:
若直接使用,会出现如下问题:
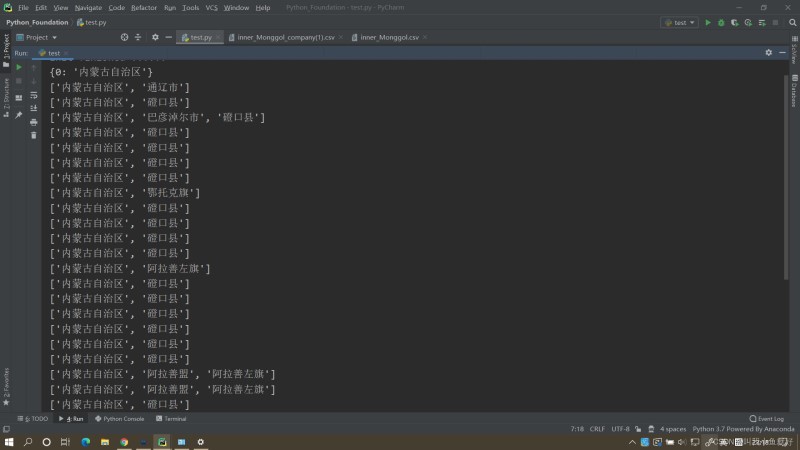
ahocorasick并没有对数据进行补全的功能,若原数据对子数据有确实,无法进行补齐,如内蒙古自治区——磴口县与内蒙古自治区——巴彦淖尔市——磴口县。后者数据符合要求,可分级进行存储,但前者地级市数据丢失。
解决方法:
1、仅将最后一级,如县级市作为关键字,对关键字进行查找,若关键词存在,通过关键词数据集向上补齐地级市与省份关键字,若不存在,则定为空。
2、若县级市关键词不存在,则将其县级市位置信息定为空,再将非空数据进行标记。
3、仅将地级市作为关键字,对具有标记的数据进行关键字查找,查找后再向上进行补齐。
4、以此类推,将其余省份信息进行补齐
该方法可参考,但不推荐,较为麻烦,且具有隐患。
三、方法一:调用cpca库
1、安装cpca库
pip指令执行:
pip install cpca
2、cpca库使用方法
import cpca information=['内蒙古自治区呼伦贝尔市牙克石市民生B区','赛罕区大学西路街道内蒙古大学','回民区北二环路内蒙古财经大学','北京海淀区','河北深州市' ] s=cpca.transform(information) print(s)
3、执行结果
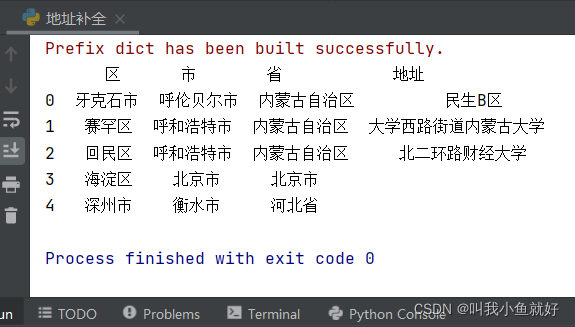
注:cpca第三方库只会精确到县级市,县级市后均为地址
总结
到此这篇关于Python实现数据地址实体抽取的文章就介绍到这了,更多相关Python地址实体抽取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫获取小区经纬度以及结构化地址
本文实例为大家分享了python爬虫获取小区经纬度.地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然后再利用经纬度Reverse到小区的结构化的地址.另外小区名称如果是'...号',可以在爬虫开始之前在'号'之后加一个'院',得到的精确度更高.这次写到程序更加便于二次利用,只需要给程序传递一个dataframe就可以坐等结果了.现在程序已经写好了,就
-
python获取linux和windows系统指定接口的IP地址的步骤及代码
实验目的: 用户输入网卡名称,通过函数返回对应的IPv4和IPv6地址. 实验代码: 步骤一: 由于window系统下网卡名称并不是真正的名字,而真正的ID在注册表SYSTEM\CurrentControlSet\Control\Network{4d36e972-e325-11ce-bfc1-08002be10318}目录下.所以需要通过如下代码,返回接口名称和唯一ID的对应关系. win_ifname.py: import netifaces as ni # import winreg as
-
Python实现数据地址实体抽取
目录 一.数据地址实体抽取的目的及问题 二.方法一:调用ahocorasick库 ahocorasick安装: ahocorasick使用: 三.方法一:调用cpca库 1.安装cpca库 2.cpca库使用方法 3.执行结果 总结 一.数据地址实体抽取的目的及问题 对数据的地址进行实体识别,主要作用是确定我们的数据主体最终可以归到哪一行政单位,从而在各行政单位上对数据主体的归属问题进行判断. 因何原因使用实体抽取: 例如原始数据所提供的信息为**省**市(地级)**市(县级)**镇,数据处理上
-
python list数据等间隔抽取并新建list存储的例子
原始数据如下: ['e3cd', 'e547', 'e63d', '0ffd', 'e39b', 'e539', 'e5be', '0dd2', 'e3d6', 'e52e', 'e5f8', '0000', 'e404', 'e52b', 'e63d', '0312', 'e38b'] 将其分割为4路数据,分别存储在fetal1.fetal2.mother1.ECG的列表中,各列表对齐,不能整除于4的数据舍去,操作如下: da = ['e3cd', 'e547', 'e63d', '0ffd'
-
python+mongodb数据抓取详细介绍
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: headers = { ..... } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式) for i
-
基于Python对数据shape的常见操作详解
这一阵在用python做DRL建模的时候,尤其是在配合使用tensorflow的时候,加上tensorflow是先搭框架再跑数据,所以调试起来很不方便,经常遇到输入数据或者中间数据shape的类型不统一,导致一些op老是报错.而且由于水平菜,所以一些常用的数据shape转换操作也经常百度了还是忘,所以想再整理一下. 一.数据的基本属性 求一组数据的长度 a = [1,2,3,4,5,6,7,8,9,10,11,12] print(len(a)) print(np.size(a)) 求一组数据的s
-
Python大数据之从网页上爬取数据的方法详解
本文实例讲述了Python大数据之从网页上爬取数据的方法.分享给大家供大家参考,具体如下: myspider.py : #!/usr/bin/python # -*- coding:utf-8 -*- from scrapy.spiders import Spider from lxml import etree from jredu.items import JreduItem class JreduSpider(Spider): name = 'tt' #爬虫的名字,必须的,唯一的 all
-
Python with语句和过程抽取思想
python中的with语句使用于对资源进行访问的场合,保证不管处理过程中是否发生错误或者异常都会执行规定的__exit__("清理")操作,释放被访问的资源,比如有文件读写后自动关闭.线程中锁的自动获取和释放等. 与python中with语句有关的概念有:上下文管理协议.上下文管理器.运行时上下文.上下文表达式.处理资源的代码段. with语句的应用场景 编程中有很多操作都是配套使用的,这种配套的流程可以称为计算过程,Python语言为这种计算过程专门设计了一种结构:with语句
-
Python爬虫数据的分类及json数据使用小结
数据的结构化分类 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为三部分,结构化的数据.半结构化的数据和非机构化数据. 1.结构化数据: 可以用统一的结构加以表示的数据.可以使用关系型数据库表示和存储,表现为二维形式的数据,一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行的数据的属性是相同的. 2.半结构化数据: 结构化数据的一种形式,并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用
-
详解Python小数据池和代码块缓存机制
前言 本文除"总结"外,其余均为认识过程:3.7.5:这部分官方文档不知道在哪里找,目前没有找到,有谁知道的可以麻烦留言吗? 谢谢了! 总结: 如果在同一代码块下,则采用同一代码块下的缓存机制: 如果是不同代码块,则采用小数据池的驻留机制: 需要注意的是,交互式输入时,每个命令都是一个代码块: 实现 Intern 保留机制的方式非常简单,就是通过维护一个字符串储蓄池,这个池子是一个字典结构,编译时,如果字符串已经存在于池子中就不再去创建新的字符串,直接返回之前创建好的字符串对象, 如果
-
python列表数据增加和删除的具体实例
1.使用 append 函数来为列表 list 添加数据,默认将数据追加在末尾. # !usr/bin/env python # -*- coding:utf-8 _*- """ @Author:猿说编程 @Blog(个人博客地址): www.codersrc.com @File:python列表list.py @Time:2021/3/22 00:37 @Motto:不积跬步无以至千里,不积小流无以成江海,程序人生的精彩需要坚持不懈地积累! ""&quo
-
利用python做数据拟合详情
目录 1.例子:拟合一种函数Func,此处为一个指数函数. 2. 例子:拟合一个Gaussian函数 3. 用一个lmfit的包来实现2中的Gaussian函数拟合 1.例子:拟合一种函数Func,此处为一个指数函数. 出处: SciPy v1.1.0 Reference Guide #Header import numpy as np import matplotlib.pyplot as plt from scipy.optimize import curve_fit #Define a f