Python pandas库中isnull函数使用方法
前言:
python的pandas库中有⼀个⼗分便利的isnull()函数,它可以⽤来判断缺失值,我们通过⼏个例⼦学习它的使⽤⽅法。
⾸先我们创建⼀个dataframe,其中有⼀些数据为缺失值。
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[7,3] = np.nan df.iloc[2:3,4] = np.nan
得到的结果如下所⽰:
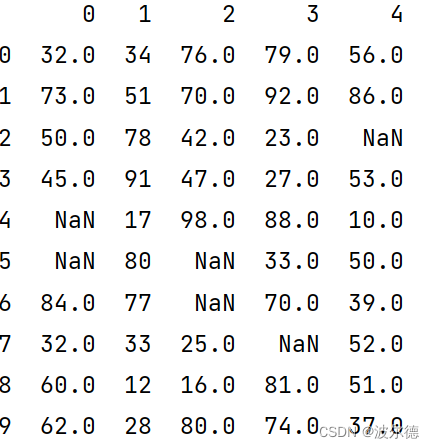
也可以通过pycharm的ScivView查看:
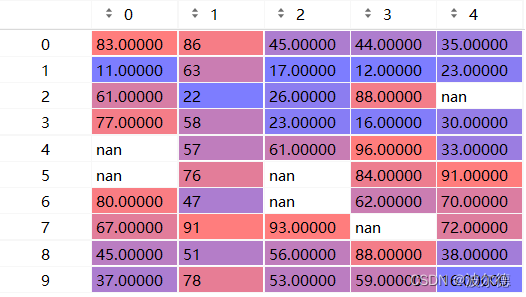
我们先来运⾏一下isnull()看会出现什么结果:
print(df.isnull())
运行结果如下所示:
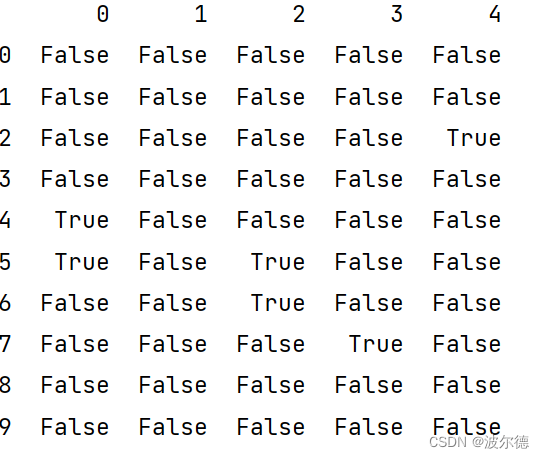
总结:isnull()返回了布尔值,若该处为缺失值,返回True,若该处不为缺失值,则返回False
直接使⽤isnull()并不能很直观的反应缺失值的信息。 我们再调⽤其他命令进⾏尝试。
df.isnull().any()
# 会判断哪些列包含缺失值,该列存在缺失值则返回True,反之False。 print(df.isnull().any())
运行结果如下所示:

总结:isnull().any()会判断哪些列包含缺失值,该列存在缺失值则返回True,反之False。
再来看一个例子:
使用isnull().sum()它直接告诉我们每列缺失值的个数。
# isnull().sum()就更加直观了,它直接告诉了我们每列缺失值的个数。 print(df.isnull().sum())
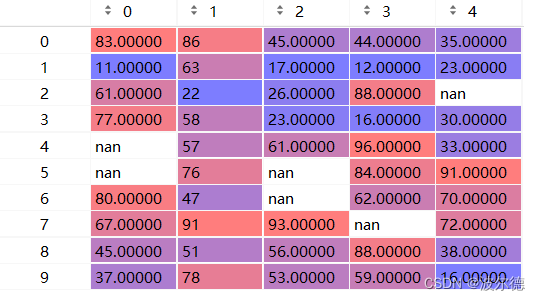
运行结果如下所示:

我来解释一下上面图片:
- 第0列有2个值为NAN(Not A Number)
- 第1列有1个值为NAN
- 第2列有2个值为NAN
- 第3列有1个值为NAN
- 第4列有1个值为NAN
我们再细心看看这个图。是不是和我们isnull().sum()的结果一模一样?
到此这篇关于Python pandas库中isnull函数使用方法的文章就介绍到这了,更多相关Python isnull内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python pandas库中的isnull()详解
问题描述 python的pandas库中有一个十分便利的isnull()函数,它可以用来判断缺失值,我们通过几个例子学习它的使用方法. 首先我们创建一个dataframe,其中有一些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[
-
Python Pandas删除替换并提取其中的缺失值NaN(dropna,fillna,isnull)
目录 前言 Pandas中缺少值NaN的介绍 将缺失值作为Pandas中的缺少值NaN 缺少值NaN的删除方法 删除所有值均缺失的行/列 删除至少包含一个缺失值的行/列 根据不缺少值的元素数量删除行/列 删除特定行/列中缺少值的列/行 pandas.Series 替换(填充)缺失值 用通用值统一替换 为每列替换不同的值 用每列的平均值,中位数,众数等替换 替换为上一个或下一个值 指定连续更换的最大数量 pandas.Series 提取缺失值 提取特定行/列中缺少值的列/行 提取至少包含一个缺失值
-

Python pandas库中isnull函数使用方法
前言: python的pandas库中有⼀个⼗分便利的isnull()函数,它可以⽤来判断缺失值,我们通过⼏个例⼦学习它的使⽤⽅法.⾸先我们创建⼀个dataframe,其中有⼀些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[7,
-
python pandas库中DataFrame对行和列的操作实例讲解
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
python numpy库中数组遍历的方法
1.对于一维数组,可以有: 2. 对于二维数组:考虑可将其看作为矩阵,故可以如下书写二重遍历 这里外层循环的是二维数组A的行,内层则是列 同时c的作用:不想用肉眼直接观察得到行列数,故用A.shape方法获得(2,6)的元组,然后改变数据类型为列表,然后直接使用. 3.对于三维数组,如: 有两个二维数组,二维数组中又有三个长度为4的数组.可以这样子循环: 又len(f) = 2, len(f[0]) = 3, len(f[0][0]) = 4;故可以再一次改进代码,这里就不写了. f[0]:三维
-
python中pandas库中DataFrame对行和列的操作使用方法示例
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
python pandas库读取excel/csv中指定行或列数据
目录 引言 1.根据index查询 2.已知数据在第几行找到想要的数据 3.根据条件查询找到指定行数据 4.找出指定列 5.找出指定的行和指定的列 6.在规定范围内找出符合条件的数据 总结 引言 关键!!!!使用loc函数来查找. 话不多说,直接演示: 有以下名为try.xlsx表: 1.根据index查询 条件:首先导入的数据必须的有index 或者自己添加吧,方法简单,读取excel文件时直接加index_col 代码示例: import pandas as pd #导入pandas库 ex
-
C#调用非托管动态库中的函数方法
C#如何调用一个非托管动态库中的函数呢,比如用VC6写的动态库,总之C#调用动态库的过程是比Java调用DLL动态库方便快捷多了,下面举例说明这个过程. 1.创建一个非托管动态库 代码如下: 复制代码 代码如下: //这一句是声明动态库输出一个可供外不调用的函数原型. extern "C" __declspec(dllexport) int add( int , int ); int add( int a, int b) { //实
-
python中lower函数实现方法及用法讲解
之前小编介绍过python中将字符串小写字符转为大写的upper函数的使用方法(upper函数).有将小写转为大写的需要,那也有将大写转为小写的情况.本文主要介绍在python中可以将字符串大写自摸转换为小写字母的lower函数. 1.lower() 转换字符串中所有大写字符为小写 2.语法 str.lower() -> str 3.返回值 返回将字符串中的所有大写字母转换为小写字母的字符串 4.使用实例 #!/usr/bin/python3 str = "ABCDEFG" pr
-
利用python在excel中画图的实现方法
一.前言 以前大学时候,学EXCEL看到N多大神利用excel画图,觉得很不可思议.今个学了一个来月python,膨胀了就想用excel画图.当然,其实用画图这个词不甚严谨,实际上是利用opencv遍历每一个像素的rgb值,再将其转化为16进制,最后调用openpyxl进行填充即可. 1.1.实现效果 效果如下图 1.2.需要用到的库的安装 需要用到库如下: import cv2 #导入OpenCV库 import xlsxwriter #利用这个调整行高列宽 import openpyxl #
-
python Pandas库read_excel()参数实例详解
目录 1.read_excel函数原型 2.参数使用举例 2.1. io和sheet_name参数 2.2. header参数 2.3. skipfooter参数 2.5. parse_dates参数 2.6. converters参数 2.7. na_values参数 2.8. usecols参数 总结 Pandas read_excel()参数使用详解 1.read_excel函数原型 def read_excel(io, sheet_name=0, header=0, names=None