详解R语言中的表达式、数学公式、特殊符号
在R语言的绘图函数中,如果文本参数是合法的R语言表达式,那么这个表达式就被用Tex类似的规则进行文本格式化。
y <- function(x) (exp(-(x^2)/2))/sqrt(2*pi) plot(y, -5, 5, main = expression(f(x) == frac(1,sqrt(2*pi))*e^(-frac(x^2,2))), lwd = 3, col = "blue")

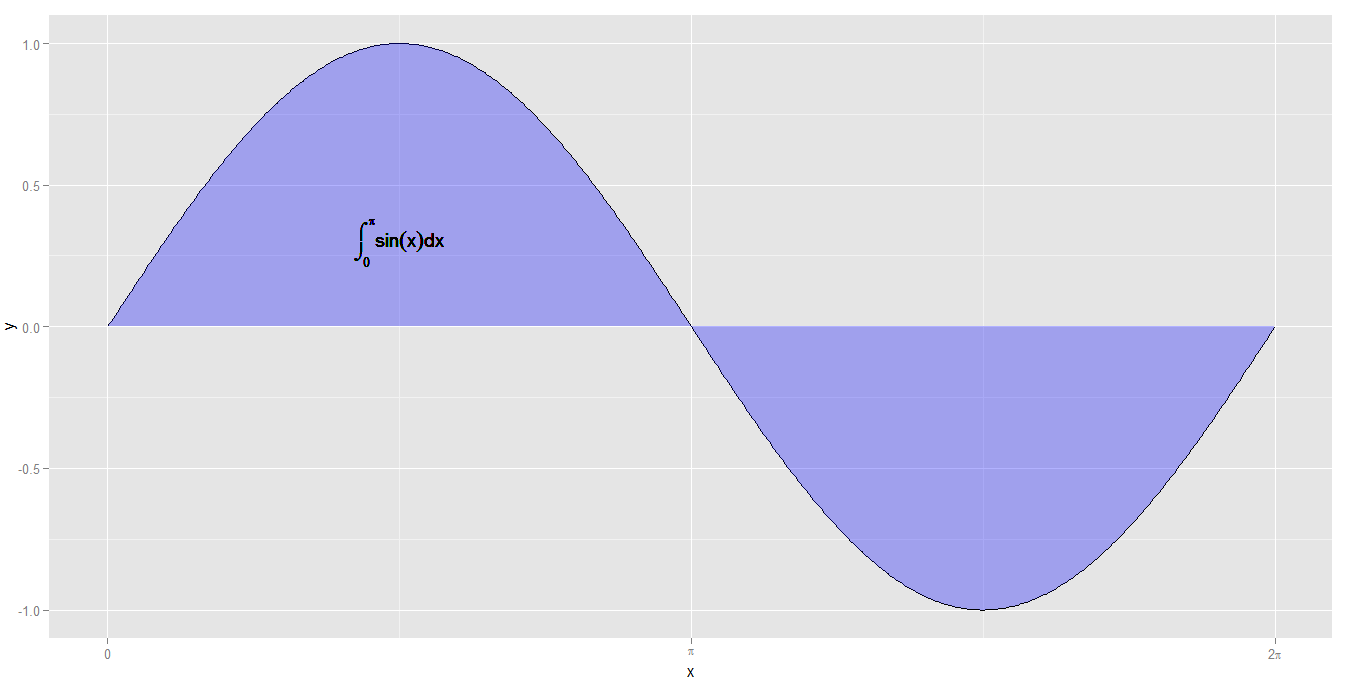
library(ggplot2)
x <- seq(0, 2*pi, by = 0.01)
y <- sin(x)
data <- data.frame(x, y)
p <- ggplot(data, aes(x, y)) + geom_line()
p + geom_area(fill = 'blue', alpha = 0.3) +
scale_x_continuous(breaks = c(0, pi, 2*pi), labels = c('0', expression(pi), expression(2*pi))) +
geom_text(parse = T, aes(x = pi/2,y = 0.3, label = 'integral(sin(x)*dx, 0, pi)'))
##一、R语言的“表达式”
在R语言中,“表达式”的概念有狭义和广义两种意义。狭义的表达式指表达式(expression)类对象,由expression函数产生;而广义的的表达式既包含expression类,也包含R“语言”类(language)。expression和language是R语言中两种特殊数据类:
getClass(“expression”)
# Class "expression" [package "methods"] # No Slots, prototype of class "expression" # Extends: "vector"
getClass(“language”)
# Virtual Class "language" [package "methods"]
# No Slots, prototype of class "name"
# Known Subclasses:
# Class "name", directly
# Class "call", directly
# Class "{", directly
# Class "if", directly
# Class "<-", directly
# Class "for", directly
# Class "while", directly
# Class "repeat", directly
# Class "(", directly
# Class ".name", by class "name", distance 2, with explicit coerce
可以看到expression类由向量派生得到,而language类是虚拟类,它包括我们熟悉的程序控制关键词/符号和name、call 子类。
##二、产生“表达式”的函数
虽然我们在R终端键入的任何有效语句都是表达式,但这些表达式在输入后即被求值(evaluate)了,获得未经求值的纯粹“表达式”就要使用函数。下面我们从函数参数和返回值两方面了解expression、quote、bquote和substitute这几个常用函数。
####1、expression 函数
expression函数可以有一个或多个参数,它把全部参数当成一个列表,每个参数都被转成一个表达式向量,所以它的返回值是表达式列表,每个元素都是表达式类型对象,返回值的长度等于参数的个数:
(ex <- expression(x = 1, 1 + sqrt(a))) ## expression(x = 1, 1 + sqrt(a)) length(ex) ## [1] 2 ex[1] ## expression(x = 1) mode(ex[1]) ## [1] "expression" typeof(ex[1]) ## [1] "expression" ex[2] ## expression(1 + sqrt(a)) mode(ex[2]) ## [1] "expression" typeof(ex[2]) ## [1] "expression"
因为expression函数把参数当成列表处理,所以等号‘='两边的表达式要符合R语言列表元素的书写规则,否则出错,比如:
expression(x+11=1)
####2、quote函数
quote函数只能有一个参数。quote函数的返回值一般情况下是call类型,表达式参数是单个变量的话返回值就是name类型,如果是常量那么返回值的存储模式就和相应常量的模式相同:
(cl <- quote(1 + sqrt(a) + b^c)) ## 1 + sqrt(a) + b^c mode(cl) ## [1] "call" typeof(cl) ## [1] "language" (cl <- quote(a)) ## a mode(cl) ## [1] "name" typeof(cl) ## [1] "symbol" (cl <- quote(1)) ## [1] 1 mode(cl) ## [1] "numeric" typeof(cl) ## [1] "double"
quote返回值如果是name或常量类型,它的长度就是1;如果是call类型,返回值长度就与函数/运算符的参数个数n对应,长度等于n+1,多出的长度1是函数/符号名。
length(quote(a)) #name或常量类型,返回值长度为1 ## [1] 1 length(quote(!a)) #单目运算符,返回值长度为2 ## [1] 2 length(quote(-b)) #单目运算符,返回值长度为2 ## [1] 2 length(quote(a + b)) #双目运算符,返回值长度为3 ## [1] 3 length(quote((a + b) * c)) #多个运算符只算优先级最低的一个 ## [1] 3
####3、bquote 和 substitute 函数
如果不使用环境变量或环境变量参数,bquote 和 substitute 函数得到的结果与quote函数相同。
bquote(1 + sqrt(a) + b^c) == quote(1 + sqrt(a) + b^c) ## [1] TRUE substitute(1 + sqrt(a) + b^c) == quote(1 + sqrt(a) + b^c) ## [1] TRUE
但是bquote 和 substitute 函数可以在表达式中使用变量,变量的值随运行进程而被替换。bquote 和 substitute 函数变量替换的方式不一样,bquote函数中需要替换的变量用 .( ) 引用,substitute函数中需要替换的变量用列表参数方式给出。除了这一点,bquote 和 substitute 函数没有差别:
a <- 3 b <- 2 (bq <- bquote(y == sqrt(.(a), .(b)))) ## y == sqrt(3, 2) (ss <- substitute(y == sqrt(a, b), list(a = 3, b = 2))) ## y == sqrt(3, 2) bq == ss ## [1] TRUE
搞出两个功能完全一样的函数不算很奇怪,R语言里面太多了,可能是照顾不同使用习惯的人们吧。bquote函数的帮助档说这个函数类似于LISP的backquote宏,对于像我这样的LISP盲,使用substitute函数好一些。 substitute函数的典型用途是替换表达式中的变量,如果我们希望在表达式中使用变量并且希望这些变量在运行过程中做出相应改变,就可以使用substitute函数。
par(mar = rep(0.1, 4), cex = 2) plot.new() plot.window(c(0, 10), c(0, 1)) for (i in 1:9) text(i, 0.5, substitute(sqrt(x, a), list(a = i + 1)))

####4、parse 函数
parse函数用于从文件读取文本作为表达式,返回的值是expression类型,这函数也很有用。后面有例子。
x <- 1 x + "x" ## Error: 二进列运算符中有非数值参数 expression(x + "x") ## expression(x + "x") quote(x + "x") ## x + "x"
但R要检查表达式中的运算符,不符合运算符使用规则的表达式将出错:
expression(x + +++y) ## expression(x + +++y) expression(x - ---y) ## expression(x - ---y) ## expression(x****y) (Not run) expression(xy) (Not run) ## expression(1<=x<=4) (Not run) quote(x + +++y) ## x + +++y quote(x - ---y) ## x - ---y ## quote(x****y) (Not run) quote(xy) (Not run) quote(1<=x<=4) (Not run)
+ - 运算连续使用不出错是因为它们还可以当成求正/负值运算的符号。 在表达式产生函数中使用paste函数可以解决这样的问题。在这种条件下,paste对参数的处理方式和表达式产生函数一样,检查运算符但不检查变量名。用NULL作为运算符的参数可以获得意外的效果:
ex <- expression(paste(x, "", y)) cl <- quote(paste(x, "****", y)) par(mar = rep(0.1, 4), cex = 2) plot.new() plot.window(c(0, 1.2), c(0, 1)) text(0.2, 0.5, ex) text(0.6, 0.5, cl) cl <- quote(paste(1 <= x, NULL <= 4)) text(1, 0.5, cl)

##三、R绘图函数对文本参数中的表达式的处理
quote, bquote 和 substitute 的返回值有三种类型call, name 和 常量,事实上expression 函数的结果最终也是这三种类型。因为expression函数的结果是expression列表,我们取列表元素的值检查看看:
(ex <- expression(1 + sqrt(x), x, 1)) ## expression(1 + sqrt(x), x, 1) ex[[1]] ## 1 + sqrt(x) mode(ex[[1]]) ## [1] "call" typeof(ex[[1]]) ## [1] "language" ex[[2]] ## x mode(ex[[2]]) ## [1] "name" typeof(ex[[2]]) ## [1] "symbol" ex[[3]] ## [1] 1 mode(ex[[3]]) ## [1] "numeric" typeof(ex[[3]]) ## [1] "double"
确实是这样。所以绘图函数对文本参数中的表达式处理就有三种情况。先看看处理结果:
par(mar = rep(0.1, 4), cex = 2) plot.new() plot.window(c(0, 1.2), c(0, 1)) text(0.2, 0.5, ex[1]) text(0.6, 0.5, ex[2]) text(1, 0.5, ex[3])

name 和常量类型都很简单,直接输出文本,而call类型就不好判断了。我们前面说过call类型返回值的长度与函数/运算符的参数个数有关。这是怎么体现的呢?由于文本参数最终得到的是文本,我们用as.character函数来看看:
as.character(quote(x - y)) ## [1] "-" "x" "y" as.character(quote(1 - x + y)) ## [1] "+" "1 - x" "y" as.character(quote((1 + x) * y)) ## [1] "*" "(1 + x)" "y" as.character(quote(!a)) ## [1] "!" "a" as.character(quote(sqrt(x))) ## [1] "sqrt" "x"
转换成字符串向量后排在第一位的是运算符或函数名称,后面是参数(如果参数中还有运算符或函数名,R还会对其进行解析)。运算符和函数是相同的处理方式。事实上,在R语言中,所有运算符(包括数学运算符和逻辑运算符)都是函数,你可以用函数的方式使用运算符:
2 + 4 ## [1] 6 2 - 4 ## [1] -2 2 <= 4 ## [1] TRUE 2 >= 4 ## [1] FALSE
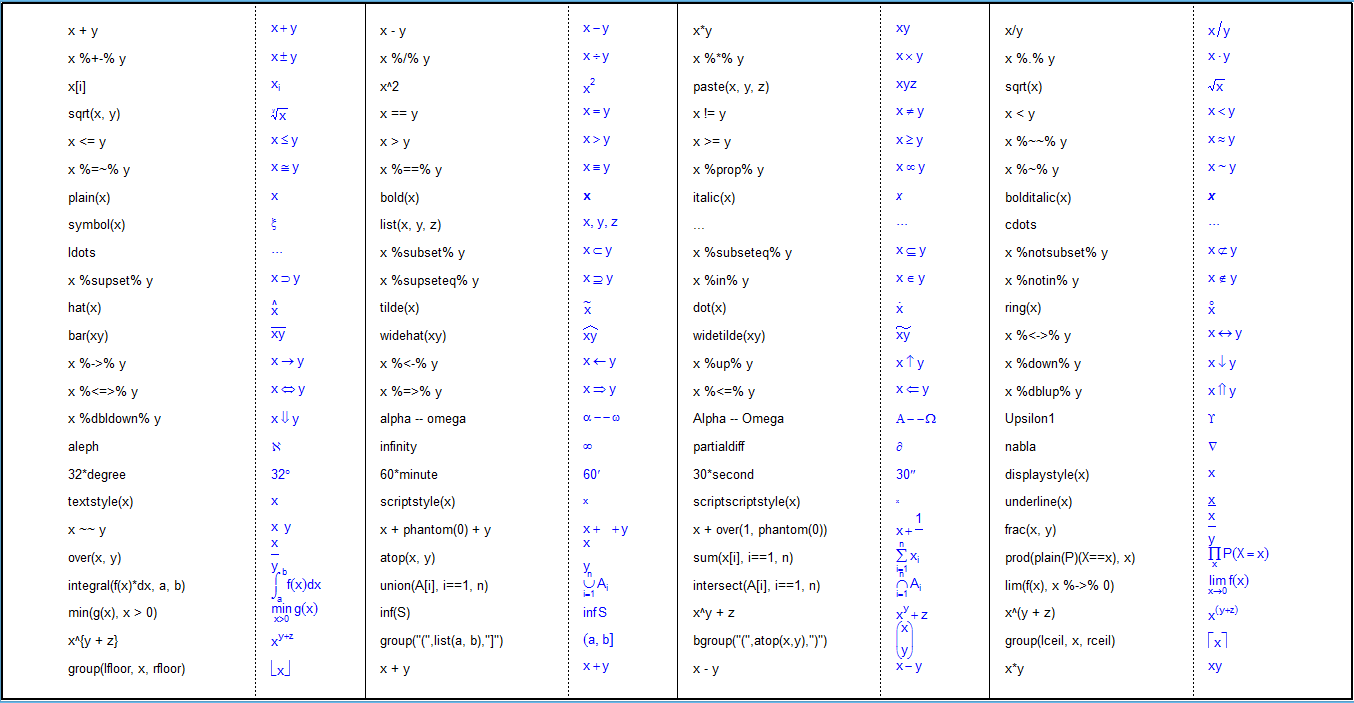
R绘图函数对表达式中包含的函数名和它们的参数首先应用Tex文本格式化规则进行处理,这种规则的具体情况可以使用 ?plotmath 进行查看,主要是一些数学公式和符号的表示方法。把这个说明文档中字符串拷贝到maths.txt文件中并保存到当前工作目录后可以用下面的代码做出后面的表格:
ex <- parse("maths.txt")
labs <- readLines("maths.txt")
n <- length(ex)
par(mar = rep(0.1, 4), cex = 0.8)
plot.new()
plot.window(c(0, 8), c(0, n/4))
y <- seq(n/4, by = -1, length = n/4)
x <- seq(0.1, by = 2, length = 4)
xy <- expand.grid(x, y)
text(xy, labs, adj = c(0, 0.5))
xy <- expand.grid(x + 1.3, y)
text(xy, ex, adj = c(0, 0.5), col = "blue")
box(lwd = 2)
abline(v = seq(1.3, by = 2, length = 4), lty = 3)
abline(v = seq(2, by = 2, length = 3), lwd = 1.5)
右键查看图片,浏览大图
表中奇数列是字符串(表达式),偶数列(蓝色)是Tex格式化的图形。除了上表列出的规则外还有一些拉丁文和希腊文符号,可以在表达式中用 symbol 函数或名称(如alpha)等表示,用到时自己去找吧。 如果函数名(包括运算符)有对应的Tex格式化规则,函数名和参数都按规则进行图形绘制;如果没有,就当成是R语言普通函数:
ex <- expression(sqrt(x), x + y, x^2, x %in% A, x <= y, mean(x, y, z), x | y, x & y)
n <- length(ex)
par(mar = rep(0.1, 4), cex = 1.5)
col <- c("red", "blue")
plot.new()
plot.window(c(0, n), c(0, 1))
for (i in 1:n) text(i - 0.5, 0.5, ex[i], col = col[i%%2 + 1])
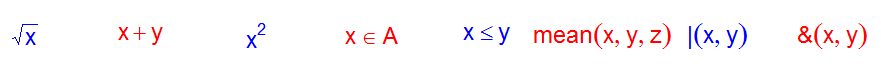
上面例子中前5种运算函数都是有对应数学符号的,所以它出的图(符号和顺序)与数学习惯一致,后三种运算函数没有对应数学符号,所以用普通函数方式(函数名在前,参数在括号内用逗号分隔)出图。其他还有一些琐碎的规则,自己找找吧。
到此这篇关于详解R语言中的表达式、数学公式、特殊符号的文章就介绍到这了,更多相关R语言表达式、数学公式、特殊符号内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
R语言中对数据框的列名重命名的实现
报错类型 Error: All arguments must be named plyr中的rename和dplyr中的rename用法是不同的. plyr::rename rename(data, c(old=new)) dplyr::rename rename(data, new = old) Example 比如, 默认的是plyr的rename, 运行下面命令, 会报错: d <- data.frame(old1=1:3, old2=4:6, old3=7:9) d library(ti
-

R语言基本运算的示例代码
1.基本运算 1.1 加.减.乘.除 + - * / 在赋值中可以使用=,也可以使用<-. 1.2余数.整除 %% %/% 1.3 取绝对值 abs() 判断正负号sign() 1.4幂指数 ^ 平方根sqart () 1.5 以二为底的对数:log2() 以十为底的对数:log10() 自定义底的对数:log(c,base=) 自然常数e的对数:log(a,base=exp(1)) 2.向量运算 向量是有相同基本类型的元素序列,一维数组,定义向量的最常用办法是使用函数c(),它把若干个数值或字
-
R语言实现操作MySQL数据库
用R语言做数据分析时,常常需要从多种数据源取数据,其中数据库是非常常见的数据源.用R操作MySQL数据库,可以说是数据分析师必备的技能了,本文介绍RMySQL包,可以在R语言中对数据库进行增删改查的操作. 软件版本 win10 64bit r3.6.1 rstudio 1.2 RMySQL 0.10.20 安装包 install.packages('RMySQL') 创建连接 用dbConnect函数创建连接,驱动类型设置为MySQL(),用户名user.密码password.主机host.端口
-
R语言gsub替换字符工具的具体使用
gsub()可以用于字段的删减.增补.替换和切割,可以处理一个字段也可以处理由字段组成的向量. 具体的使用方法为:gsub("目标字符", "替换字符", 对象) 在gsub函数中,任何字段处理都由将"替换字符"替换到"目标字符"这一流程中实现,令替换字符为''''可实现删除,令替换字符为"目标字符+增补内容"可实现增补,替换和切割也是使用类似的操作. > text <- "AbcdE
-
R语言运行环境安装配置详解
一.下载 这个是R 语言下载的镜像站点的列表 https://cran.r-project.org/mirrors.html 直接选择清华的站点来进行下载即可 https://mirrors.tuna.tsinghua.edu.cn/CRAN/ 选择版本进行下载 点击运行 进入安装界面 一路默认,安装完毕! 二.Pycharm内 好像根据环境变量,自动就配置好了,很方便 R语言下载及安装介绍到这里,你就可以用R语言写下你的第一行R语句了,打印个"Hello World!"试一下 >
-
详解R语言中的表达式、数学公式、特殊符号
在R语言的绘图函数中,如果文本参数是合法的R语言表达式,那么这个表达式就被用Tex类似的规则进行文本格式化. y <- function(x) (exp(-(x^2)/2))/sqrt(2*pi) plot(y, -5, 5, main = expression(f(x) == frac(1,sqrt(2*pi))*e^(-frac(x^2,2))), lwd = 3, col = "blue") library(ggplot2) x <- seq(0, 2*pi, b
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
详解R语言数据合并一行代码搞定
数据的合并 需要的函数 cbind(),rbind(),bind_rows(),merge() 准备数据 我们先构造一组数据,以便下面的演示 > data1<-data.frame( + namea=c("海波","立波","秀波"), + value=c("一波","接","一波") + ) > data1 namea value 1 海波 一波 2 立波 接 3 秀
-
详解C语言中不同类型的数据转换规则
不同类型数据间的混合运算与类型转换 1.自动类型转换 在C语言中,自动类型转换遵循以下规则: ①若参与运算量的类型不同,则先转换成同一类型,然后进行运算 ②转换按数据长度增加的方向进行,以保证精度不降低.如int型和long型运算时,先把int量转成long型后再进行运算 a.若两种类型的字节数不同,转换成字节数高的类型 b.若两种类型的字节数相同,且一种有符号,一种无符号,则转换成无符号类型 ③所有的浮点运算都是以双精度进行的,即使是两个float单精度量运算的表达式,也要先转换成double
-
详解R语言实现前向逐步回归(前向选择模型)
目录 前向逐步回归原理 数据导入并分组 导入数据 特征与标签分开存放 前向逐步回归构建输出特征集合 从空开始一次创建属性列表 模型效果评估 前向逐步回归原理 前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性.接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集.以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集.这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加. 数据导入并分组 导入数据,将数据集抽取70%作为训练集,剩
-
详解C语言中二分查找的运用技巧
目录 基础的二分查 查找左侧边界 查找右侧边界 二分查找问题分析 实例1: 爱吃香蕉的珂珂 实例2:运送包裹 前篇文章聊到了二分查找的基础以及细节的处理问题,主要介绍了 查找和目标值相等的元素.查找第一个和目标值相等的元素.查找最后一个和目标值相等的元素 三种情况. 这些情况都适用于有序数组中查找指定元素 这个基本的场景,但实际应用中可能不会这么直接,甚至看了题目之后,都不会想到可以用二分查找算法来解决 . 本文就来分析下二分查找在实际中的应用,通过分析几个应用二分查找的实例,总结下能使用二分查
-
详解Go语言中泛型的实现原理与使用
目录 前言 问题 解决方法 类型约束 重获类型安全 泛型使用场景 性能 虚拟方法表 单态化 Go 的实现 结论 前言 原文:A gentle introduction to generics in Go byDominik Braun 万俊峰Kevin:我看了觉得文章非常简单易懂,就征求了作者同意,翻译出来给大家分享一下. 本文是对泛型的基本思想及其在 Go 中的实现的一个比较容易理解的介绍,同时也是对围绕泛型的各种性能讨论的简单总结.首先,我们来看看泛型所解决的核心问题. 问题 假设我们想实现
-
一文详解C语言中文件相关函数的使用
目录 一.文件和流 1.程序文件 2.数据文件 3.流 二.文件组成 三.文件的打开和关闭 1.文件的打开fopen 2.文件关闭fclose 四.文件的顺序读写 1.使用fputc和fgetc写入/读取单个字符 2.使用fputs和fgets写入/读取一串字符 3.使用fprintf和fscanf按照指定的格式写入/读取 4.使用fwrite和fread按照二进制的方式写入/读取 5.使用sprintf和sscanf将格式化数据和字符串互相转换(文件无关) 五.文件的随机读写 1.fseek(
-
详解Go语言中切片的长度与容量的区别
目录 切片的声明 切片的长度和容量 切片追加元素后长度和容量的变化 append 函数 切片的源代码学习 切片的结构体 切片的扩容 总结 切片的声明 切片可以看成是数组的引用(实际上切片的底层数据结构确实是数组).在 Go 中,每个数组的大小是固定的,不能随意改变大小,切片可以为数组提供动态增长和缩小的需求,但其本身并不存储任何数据. // 数组的声明 var a [5]int //只指定长度,元素初始化为默认值0 var a [5]int{1,2,3,4,5} // 切片的声明 // 方法1: