python读取查看npz/npy文件数据以及数据完全显示方法实例
目录
- python读取npz/npy文件
- python查看npz/npy文件
- 附:python-读取和保存npy文件示例代码
- 总结
python读取npz/npy文件
npz和npy文件都可以直接使用numpy读写。
import numpy as np
ac = np.load('mydata.npz')
ac.files

python查看npz/npy文件
要查看其中某一项的数据:
M = ac['M'] M
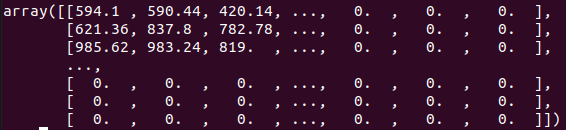
显示的值带省略号,要完全显示,执行:
np.set_printoptions(threshold=np.inf) M
输出有很多很多:

查看M的形状大小:
M.shape

将numpy输出样式修改回去(默认为6):
np.set_printoptions(threshold=6)
再输出M试试:
M

要查看M中某一项的值,可以执行:
M[0,0] # 查看第一个元素的值
上面说的是打开查看npz文件的方式,但是其实,打开npy文件的方式和上述是一模一样的,并且,npz文件其实就是一系列npy文件的压缩包而已,如下图所示:

因此,要打开npy文件,执行:
M = np.load("M.npy")
文件名依据自己的实际文件名进行更改,这里的M和上面的M是一样的,所以操作其实也是一样的了。
保存为文本文件的方法:
np.savetxt('M.txt', M, delimiter=" ") #保存为txt
np.savetxt('M.csv', M, delimiter=",") #保存为csv
最后,记录一个问题,来自python读取npy文件。如果在加载预训练模型时,执行如下命令:
pre_train = np.load("vgg16.npy", allow_pickle=True, encoding="latin1")
print(pre_train.shape)
# 输出为(),没有数据
解决方法:
data_dic = pre_train.item() print(data_dic.shape)
即可查看。
附:python-读取和保存npy文件示例代码
import numpy as np
# .npy文件是numpy专用的二进制文件
arr = np.array([[1, 2], [3, 4]])
# 保存.npy文件
np.save("../data/arr.npy", arr)
print("save .npy done")
# 读取.npy文件
np.load("../data/arr.npy")
print(arr)
print("load .npy done")
总结
到此这篇关于python读取查看npz/npy文件数据以及数据完全显示方法的文章就介绍到这了,更多相关python读取npz/npy文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python 存取npy格式数据实例
数据处理的时候主要通过两个函数 (1):np.save("test.npy",数据结构) ----存数据 (2):data =np.load('test.npy") ----取数据 给2个例子如下(存列表) 1. z = [[[1, 2, 3], ['w']], [[1, 2, 3], ['w']]] np.save('test.npy', z) x = np.load('test.npy') x: ->array([[list([1, 2, 3]), list(['w
-
python实现npy格式文件转换为txt文件操作
如下代码会将npy的格式数据读出,并且输出来到控制台: import numpy as np ##设置全部数据,不输出省略号 import sys np.set_printoptions(threshold=sys.maxsize) boxes=np.load('./input_output/boxes.npy') print(boxes) np.savetxt('./input_output/boxes.txt',boxes,fmt='%s',newline='\n') print('----
-
python多进程读图提取特征存npy
本文实例为大家分享了python多进程读图提取特征存npy的具体代码,供大家参考,具体内容如下 import multiprocessing import os, time, random import numpy as np import cv2 import os import sys from time import ctime import tensorflow as tf image_dir = r"D:/sxl/处理图片/汉字分类/train10/" #图像文件夹路径 da
-

python读取查看npz/npy文件数据以及数据完全显示方法实例
目录 python读取npz/npy文件 python查看npz/npy文件 附:python-读取和保存npy文件示例代码 总结 python读取npz/npy文件 npz和npy文件都可以直接使用numpy读写. import numpy as np ac = np.load('mydata.npz') ac.files python查看npz/npy文件 要查看其中某一项的数据: M = ac['M'] M 显示的值带省略号,要完全显示,执行: np.set_printoptions(th
-
python 读取目录下csv文件并绘制曲线v111的方法
实例如下: # -*- coding: utf-8 -*- """ Spyder Editor This temporary script file is located here: C:\Users\user\.spyder2\.temp.py """ """ Show how to modify the coordinate formatter to report the image "z"
-
python读取并写入mat文件的方法
先给大家介绍下python读取并写入mat文件的方法 用matlab生成一个示例mat文件: clear;clc matrix1 = magic(5); matrix2 = magic(6); save matData.mat 用python3读取并写入mat文件: import scipy.io data = scipy.io.loadmat('matData.mat') # 读取mat文件 # print(data.keys()) # 查看mat文件中的所有变量 print(data['ma
-
python读取和保存mat文件的方法
目录 一.mat文件 二.python中读取mat文件 1.读取文件 2.保存文件 首先我们谈谈MarkDown编辑器,我感觉些倒是挺方便的,因为用惯了LaTeX,对于MarkDown还是比较容易上手的,但是我发现,MarkDown中有这样几个问题一直没能找到具体的解决方法: 图片大小的问题.在LaTeX中我们可以调整图片的大小,以适应整个文本:字体,字号大小的设置.在MarkDown里面标题倒是挺大的,但是正文却显得太小,不是很喜欢里面的字体. 主要发现上面两个问题导致编辑出来的文本挺难看.
-
使用Python读取和修改Excel文件(基于xlrd、xlwt和openpyxl模块)
目录 1.使用xlrd模块对xls文件进行读操作 1.1 获取工作簿对象 1.2 获取工作表对象 1.3 获取工作表的基本信息 1.4 按行或列方式获得工作表的数据 2.使用xlwt模块对xls文件进行写操作 2.1 创建工作簿 2.2 创建工作表 2.3 按单元格的方式向工作表中添加数据 2.4 按行或列方式向工作表中添加数据 2.5 保存创建的文件 3.使用openpyxl模块对xlsx文件进行读操作 3.1 获取工作簿对象 3.2 获取所有工作表名 3.3 获取工作表对象 3.5 获取工作
-
使用python对多个txt文件中的数据进行筛选的方法
一.问题描述 筛选出多个txt文件中需要的数据 二.数据准备 这是我自己建立的要处理的文件,里面是随意写的一些数字和字母 三.程序编写 import os def eachFile(filepath): pathDir =os.listdir(filepath) #遍历文件夹中的text return pathDir def readfile(name): fopen=open(name,'r') for lines in fopen.readlines(): #按行读取text中的内容 lin
-
Python 读取 YUV(NV12) 视频文件实例
一.YUV 简介 YUV:是一种颜色编码方法,常使用在各个视频处理组件中 Y'UV, YCbCr, YPbPr等专有名词都可以称为 YUV,彼此有重叠 Y表示明亮度(单取此通道即可得灰度图),U和V则是色度.浓度 主流的采样方式有三种,YUV4:4:4,YUV4:2:2,YUV4:2:0 可以根据其采样格式来从码流中还原每个像素点的 YUV 值,进而通过 YUV 与 RGB 的转换公式提取出每个像素点的 RGB 值,然后显示出来 YUV4:2:0 数据在内存中的长度是 3 / 2 * heigt
-
Python读取和存储yaml文件的方法
YAML 是 "YAML Ain't a Markup Language"(YAML 不是一种标记语言)的递归缩写.在开发的这种语言时,YAML 的意思其实是:"Yet Another Markup Language"(仍是一种标记语言). YAML 的语法和其他高级语言类似,并且可以简单表达清单.散列表,标量等数据形态.它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构.各种配置文件.倾印调试内容.文件大纲(例如:许多电子邮件标题格式和YAML
-
一文搞懂Python读取text,CSV,JSON文件的方法
目录 前言 打开文件 Python 中的文件读取模式 读取文本文件 读取 CSV 文件 读取 JSON 文件 总结 前言 文件是无处不在的,无论我们使用哪种编程语言,处理文件对于每个程序员都是必不可少的 文件处理是一种用于创建文件.写入数据和从中读取数据的过程,Python 拥有丰富的用于处理不同文件类型的包,从而使得我们可以更加轻松方便的完成文件处理的工作 本文大纲: 使用上下文管理器打开文件 Python 中的文件读取模式 读取 text 文件 读取 CSV 文件 读取 JSON 文件 打开
-
对python 读取线的shp文件实例详解
如下所示: import shapefile sf = shapefile.Reader("E:\\1.2\\cs\\DX_CSL.shp") shapes = sf.shapes() print shapes[1].parts print len(shapes) #79条记录 #print len(list(sf.iterShapes())) #79条记录 #for name in dir(shapes[3]): #不带参数时,返回当前范围内的变量.方法和定义的类型列表:带参数时,返