TensorFlow基本的常量、变量和运算操作详解
简介
深度学习需要熟悉使用一个框架,本人选择了TensorFlow,一边学习一边做项目,下面简要介绍TensorFlow中的基本常量、变量和运算操作,参考斯坦福大学的cs20si和TensorFlow官网API。
常量
tf.constant()
tf.constant(value, dtype=None, shape=None, name='Const', verify_shape=False),value为值,dtype类型,shape为张量形状,name名称、verify_shape默认False,这些项可选。作用创建一个常量。
a = tf.constant(2, name="a") # print(a) = 2 b = tf.constant(2.0, dtype=tf.float32, shape=[2,2], name="b") # 2x2矩阵,值为2 c = tf.constant([[1, 2], [3, 4]], name="c") # 2x2矩阵,值1,2,3,4
tf.zeros()和tf.zeros_like()
tf.zeros(shape, dtype=tf.float32, name=None), shape为张量形状,dtype类型,name名称。创建一个值为0的常量。
a = tf.zeros(shape=[2, 3], dtype=tf.int32, name='a') # 2x3矩阵,值为0, a = [[0, 0, 0], [0, 0, 0]]
tf.zeros_like(input_tensor, dtype=None, name=None, optimize=True),input_tensor为张量,dtype类型,name名称,optimize优化。根据输入张量创建一个值为0的张量,形状和输入张量相同。
input_tensor = tf.constant([[1,2], [3,4], [5,6]) a = tf.zeros_like(input_tensor) # a = [[0, 0], [0, 0], [0, 0]]
tf.ones()和tf.ones_like()
tf.ones(shape, dtype=tf.float32, name=None),与tf.zeros()类似。
tf.ones_like(input_tensor, dtype=None, name=None, optimize=True),与tf.zeros_like()类似。
tf.fill()
tf.fill(dims, value, name=None), dims为张量形状,同上述shape,vlaue值,name名称。作用是产生一个张量,用一个具体值充满张量。
a = tf.fill([2,3], 8) # 2x3矩阵,值为8
tf.linspace()
tf.linspace(start, stop, num, name=None),start初始值,stop结束值,num数量,name名称。作用是产生一个等差数列一维向量,个数是num,初始值start、结束值stop。
a = tf.linspace(10.0, 13.0, 4) # a = [10.0 11.0 12.0 13.0]
tf.range()
tf.range(start=0, limit=None, delta=1, dtype=None, name='range'),start初始值,limit限制,delta增量,dtype类型,name名称。作用是产生一个等差数列的一维向量,初始值start,公差delta,结束值小于limit。
a = tf.range(start, limit, delta) # a = [3, 6, 9, 12, 15] b = tf.range(5) # b = [0, 1, 2, 3, 4]
tf.random_normal()
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None), shape张量形状,mean均值,stddev标准差,dtype类型,seed随机种子,name名称。作用是产生一个正太分布分布,均值为mean,标准差为stddev。
tf.truncated_normal()
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None,name=None),shape张量形状,mean均值,stddev标准差,dtype类型,seed随机种子,name名称。作用是产生一个截断的正太分布,形状为shape,均值为mean,标准差为stddev。
tf.random_uniform()
tf.random_uniform(shape, minval=0, maxval=None, dtype=tf.float32, seed=None,name=None),shape张量形状,minval最小值,maxval最大值,dtype类型,seed随机种子,name名称。作用是产生一个均匀分布,形状为shape,最小值为minval,最大值为maxval。
tf.random_shuffle()
tf.random_shuffle(value, seed=None, name=None),value张量,seed随机种子,name名称。作用是将张量value里面的值随机打乱。
a = tf.constant([[1,2],[3,4]],name='a') b = tf.random_shuffle(a, name='b') # b = [[2,3], [1,4]]
tf.random_crop()
tf.random_crop(value, size, seed=None, name=None),value张量,size大小,seed随机种子,name名称。作用是将张量value随机裁剪成size形状大小的张量,value形状大小>=size。
tf.multinomial()
tf.multinomial(logits, num_samples, seed=None, name=None), logits张量,num_samples采样输出,seed随机种子,name名称。作用是根据概率分布的大小,随机返回对应维度的下标序号。
a = tf.constant([[1, 2, 3, 4, 1], [3, 2, 3, 4, 3]], name='a') b = tf.multinomial(a, 1, name='b') # b = [0, 0]或者[0, 2]或者[4, 4]
tf.random_gamma()
tf.random_gamma(shape, alpha, beta=None, dtype=tf.float32, seed=None, name=None)。作用是产生一个Gamma分布。
变量
tf.Variable()
tf.Variable(<initial-value>, name=<optional-name>),变量可以根据直接赋值,如a、b、c,也可以根据构造函数赋值,如W、Z。
a = tf.Variable(2, name="scalar") b = tf.Variable([2, 3], name="vector") c = tf.Variable([[0, 1], [2, 3]], name="matrix") W = tf.Variable(tf.zeros([784,10]), name="weights") Z = tf.Variable(tf.random_normal([784, 10], mean=0, stddev=0.01), name="Z"
tf.Variable().initializer
1.全局变量初始化
init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init)
2.指定变量初始化
W = tf.Variable(tf.truncated_normal([700, 10]))
with tf.Session() as sess:
sess.run(W.initializer)
print(W) # Tensor("Variable/read:0", shape=(700, 10), dtype=float32)
tf.Variable().eval()
返回变量值。
W = tf.Variable(tf.truncated_normal([700, 10])) with tf.Session() as sess: sess.run(W.initializer) print(W.eval()) >> [[-0.76781619 -0.67020458 1.15333688 ..., -0.98434633 -1.25692499 -0.90904623] [-0.36763489 -0.65037876 -1.52936983 ..., 0.19320194 -0.38379928 0.44387451] [ 0.12510735 -0.82649058 0.4321366 ..., -0.3816964 0.70466036 1.33211911] ..., [ 0.9203397 -0.99590844 0.76853162 ..., -0.74290705 0.37568584 0.64072722] [-0.12753558 0.52571583 1.03265858 ..., 0.59978199 -0.91293705 -0.02646019] [ 0.19076447 -0.62968266 -1.97970271 ..., -1.48389161 0.68170643
tf.Variable.assign()
直接调用assign()并不起作用,它是一个操作,需要sess.run()操作才能起效果。
W = tf.Variable(10) W.assign(100) with tf.Session() as sess: sess.run(W.initializer) print(W.eval()) # >> 10
W = tf.Variable(10) assign_op = W.assign(100) with tf.Session() as sess: # sess.run(W.initializer) # 当变量有值的话,可以省略,不需要初始化 sess.run(assign_op) print W.eval() # >> 100
运算操作
运算操作图
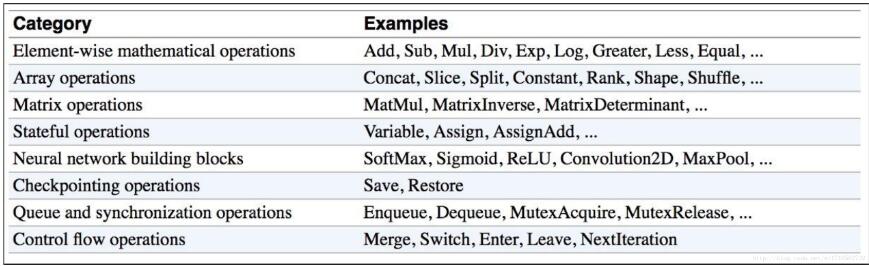
tf.multiply()和tf.matmul()
tf.multiply(x, y, name)作用是x, y逐项相乘。
tf.matmul(x, y, name)作用是x,y矩阵相乘。
a = tf.constant([3, 6]) b = tf.constant([2, 2]) c1 = tf.matmul(a, b) # 报错 c2 = tf.matmul(tf.reshape(a, [1, 2]), tf.reshape(b, [2, 1]))# c2 = [[18]] c3 = tf.multiply(a, b) # c3 = [6, 12]
加减就不细说了。
结束语
总结了一些常用的常量、变量和操作运算,供大家参考,尤其是对于tensorflow和python不太熟悉的选手有帮助,后续会补充更新,希望大家多多支持我们。
相关推荐
-
Tensorflow实现部分参数梯度更新操作
在深度学习中,迁移学习经常被使用,在大数据集上预训练的模型迁移到特定的任务,往往需要保持模型参数不变,而微调与任务相关的模型层. 本文主要介绍,使用tensorflow部分更新模型参数的方法. 1. 根据Variable scope剔除需要固定参数的变量 def get_variable_via_scope(scope_lst): vars = [] for sc in scope_lst: sc_variable = tf.get_collection(tf.GraphKeys.TRAINAB
-
从训练好的tensorflow模型中打印训练变量实例
从tensorflow 训练后保存的模型中打印训变量:使用tf.train.NewCheckpointReader() import tensorflow as tf reader = tf.train.NewCheckpointReader('path/alexnet/model-330000') dic = reader.get_variable_to_shape_map() print dic 打印变量 w = reader.get_tensor("fc1/W") print t
-
Tensorflow轻松实现XOR运算的方式
对于"XOR"大家应该都不陌生,我们在各种课程中都会遇到,它是一个数学逻辑运算符号,在计算机中表示为"XOR",在数学中表示为"",学名为"异或",其来源细节就不详细表明了,说白了就是两个a.b两个值做异或运算,若a=b则结果为0,反之为1,即"相同为0,不同为1". 在计算机早期发展中,逻辑运算广泛应用于电子管中,这一点如果大家学习过微机原理应该会比较熟悉,那么在神经网络中如何实现它呢,早先我们使用的是感
-
Tensorflow设置显存自适应,显存比例的操作
Tensorfow框架下,在模型运行时,设置对显存的占用. 1. 按比例 config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.4 # 根据自己的需求确定 session = tf.Session(config=config, ...) 2. 自适应 config = tf.ConfigProto() config.gpu_options.allow_growth = True sessi
-
TensorFlow基本的常量、变量和运算操作详解
简介 深度学习需要熟悉使用一个框架,本人选择了TensorFlow,一边学习一边做项目,下面简要介绍TensorFlow中的基本常量.变量和运算操作,参考斯坦福大学的cs20si和TensorFlow官网API. 常量 tf.constant() tf.constant(value, dtype=None, shape=None, name='Const', verify_shape=False),value为值,dtype类型,shape为张量形状,name名称.verify_shape默认F
-
对tensorflow中cifar-10文档的Read操作详解
前言 在tensorflow的官方文档中得卷积神经网络一章,有一个使用cifar-10图片数据集的实验,搭建卷积神经网络倒不难,但是那个cifar10_input文件着实让我费了一番心思.配合着官方文档也算看的七七八八,但是中间还是有一些不太明白,不明白的mark一下,这次记下一些已经明白的. 研究 cifar10_input.py文件的read操作,主要的就是下面的代码: if not eval_data: filenames = [os.path.join(data_dir, 'data_b
-
Java多线程Atomic包操作原子变量与原子类详解
在阅读这篇文章之前,大家可以先看下<Java多线程atomic包介绍及使用方法>,了解atomic包的相关内容. 一.何谓Atomic? Atomic一词跟原子有点关系,后者曾被人认为是最小物质的单位.计算机中的Atomic是指不能分割成若干部分的意思.如果一段代码被认为是Atomic,则表示这段代码在执行过程中,是不能被中断的.通常来说,原子指令由硬件提供,供软件来实现原子方法(某个线程进入该方法后,就不会被中断,直到其执行完成) 在x86平台上,CPU提供了在指令执行期间对总线加锁的手段.
-
对tf.reduce_sum tensorflow维度上的操作详解
tensorflow中有很多在维度上的操作,本例以常用的tf.reduce_sum进行说明.官方给的api reduce_sum( input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None ) input_tensor:表示输入 axis:表示在那个维度进行sum操作. keep_dims:表示是否保留原始数据的维度,False相当于执行完后原始数据就会少一个维度. reduction_indices:
-
浅谈tensorflow中Dataset图片的批量读取及维度的操作详解
三维的读取图片(w, h, c): import tensorflow as tf import glob import os def _parse_function(filename): # print(filename) image_string = tf.read_file(filename) image_decoded = tf.image.decode_image(image_string) # (375, 500, 3) image_resized = tf.image.resize
-
在Tensorflow中实现leakyRelu操作详解(高效)
从github上转来,实在是厉害的想法,什么时候自己也能写出这种精妙的代码就好了 原地址:简易高效的LeakyReLu实现 代码如下: 我做了些改进,因为实在tensorflow中使用,就将原来的abs()函数替换成了tf.abs() import tensorflow as tf def LeakyRelu(x, leak=0.2, name="LeakyRelu"): with tf.variable_scope(name): f1 = 0.5 * (1 + leak) f2 =
-
重学Go语言之变量与常量的声明与使用详解
目录 变量 变量名 声明 变量作用域 常量 iota 常量生成器 小结 变量 什么是变量?变量是一块可以随时存放数据的内存区域.在我们申请这块内存区域(声明变量)时,需要指定变量名以及变量的数据类型,数据类型用于说明变量可以存放什么值. Go是强类型语言,因此Go的变量需要先声明再使用,且声明后不可以改变其数据类型. 变量名 变量名必须以字母或下划线开头. 变量名区分大小写,比如Version和version是两个不同的变量. 不能用关键字(25个)和保留字(37个)给变量命名. 声明 Go语言
-

Python对象类型及其运算方法(详解)
基本要点: 程序中储存的所有数据都是对象(可变对象:值可以修改 不可变对象:值不可修改) 每个对象都有一个身份.一个类型.一个值 例: >>> a1 = 'abc' >>> type(a1) str 创建一个字符串对象,其身份是指向它在内存中所处的指针(在内存中的位置) a1就是引用这个具体位置的名称 使用type()函数查看其类型 其值就是'abc' 自定义类型使用class 对象的类型用于描述对象的内部表示及其支持的方法和操作 创建特定类型的对象,也将该对象称为该类
-
对Tensorflow中Device实例的生成和管理详解
1. 关键术语描述 kernel 在神经网络模型中,每个node都定义了自己需要完成的操作,比如要做卷积.矩阵相乘等. 可以将kernel看做是一段能够跑在具体硬件设备上的算法程序,所以即使同样的2D卷积算法,我们有基于gpu的Convolution 2D kernel实例.基于cpu的Convolution 2D kernel实例. device 负责运行kernel的具体硬件设备抽象.每个device实例,对应系统中一个具体的处理器硬件,比如gpu:0 device, gpu:1 devic
-
java安全编码指南之:Number操作详解
简介 java中可以被称为Number的有byte,short,int,long,float,double和char,我们在使用这些Nubmer的过程中,需要注意些什么内容呢?一起来看看吧. Number的范围 每种Number类型都有它的范围,我们看下java中Number类型的范围: 考虑到我们最常用的int操作,虽然int的范围够大,但是如果我们在做一些int操作的时候还是可能超出int的范围. 超出了int范围会发送什么事情呢?看下面的例子: public void testIntege