用Python实现数据筛选与匹配实例
目录
- 案例一:数据筛选
- 案例二:数据匹配
下面我们将学习两个项目案例代码,分别解决Excel常见场景中的数据筛选问题和数据匹配问题。
数据筛选要求我们在表中筛选出符合条件的数据。
数据匹配需要我们在多个表之间匹配相关的数据。
与之前一样,完成项目问题的代码,需要我们先分析数据筛选和数据匹配的需求,再找到对应知识点,确定代码的执行顺序,从而实现项目代码。
案例一:数据筛选
这个案例需要我们筛选出迟到人员的信息,来具体看看。
在【10月考勤统计.xlsx】工作簿中,保存了公司一百名员工的迟到信息,这些信息包含了迟到时间和迟到次数。
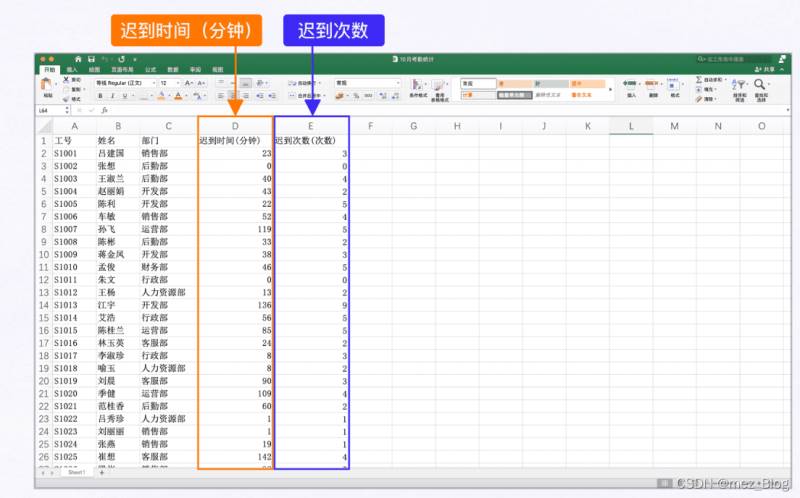
公司规定,迟到时间超过45分钟且迟到过3次以上的员工记为考勤不合格,需要扣除300的考勤保证金。
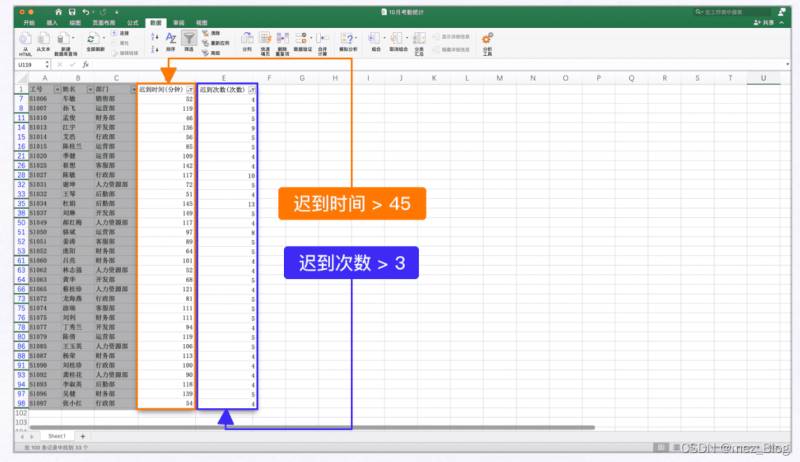
之前的同事需要把筛选后的结果保存为【10月迟到人员信息.xlsx】,并将整理后的信息上报给领导。
那么如何用代码实现这个场景呢?
在编写代码之前,我们要先明确任务需求。
根据公司的规定,筛选出【10月考勤统计.xlsx】中迟到时间大于45分钟并且迟到次数超过3次以上的员工信息,将迟到人员信息打印出来后再存入新工作簿【10月迟到人员信息.xlsx】中。
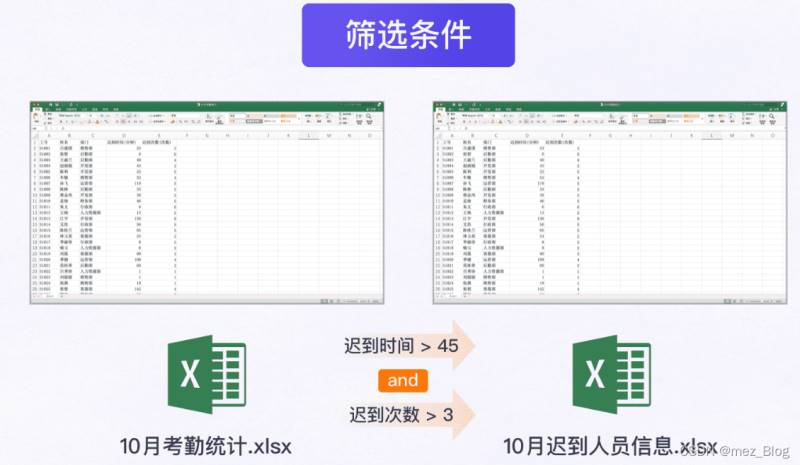
代码实现:
from openpyxl import load_workbook, Workbook
# 打开【10月考勤统计.xlsx】工作簿
wb = load_workbook('./material/10月考勤统计.xlsx')
# 获取活动工作表
ws = wb.active
print(ws)
print(ws[1])
print('----------------')
# 获取表头
late_header = []
for cell in ws[1]:
late_header.append(cell.value)
print(cell.value)
# 新建工作簿
new_wb = Workbook()
# 获取新工作簿中的工作表
new_ws = new_wb.active
# 将表头写入新工作簿的工作表中
new_ws.append(late_header)
# 从第二行开始遍历表格
for row in ws.iter_rows(min_row=2, values_only=True):
# 取出姓名,迟到时间和迟到次数
name = row[1]
time = row[3]
number = row[-1]
# 判断是否迟到
if time > 45 and number > 3:
print('{}迟到了{}分钟,迟到了{}次'.format(name, time, number))
# 将迟到人员信息写入新工作簿的工作表中
new_ws.append(row)
# 将新工作簿保存为【10月迟到人员信息.xlsx】
new_wb.save('./material/10月迟到人员信息.xlsx')
运行结果:




根据任务需求,我们需要获取两部分数据:表头数据和表头以外的所有数据。
你可能会比较疑惑,为什么要单独获取表头数据呢?

由于任务需要我们生成新的工作簿【10月迟到人员信息.xlsx】,新工作簿中的表头与【10月考勤统计.xlsx】相同,所以我们需要获取到表头的数据以便后续使用。
使用数据
我们需要在这一步实现数据筛选功能,通过分析任务需求可以总结出三个筛选条件:
1)迟到时间大于45分钟。
2)迟到次数大于3次。
3)同时满足上面两个条件。
明确了筛选条件后,就可以借助条件判断语句,比较运算符,成员运算符和逻辑运算符等Python基础知识,实现对于数据的筛选,即将上面得到的筛选条件用Python语言实现出来。
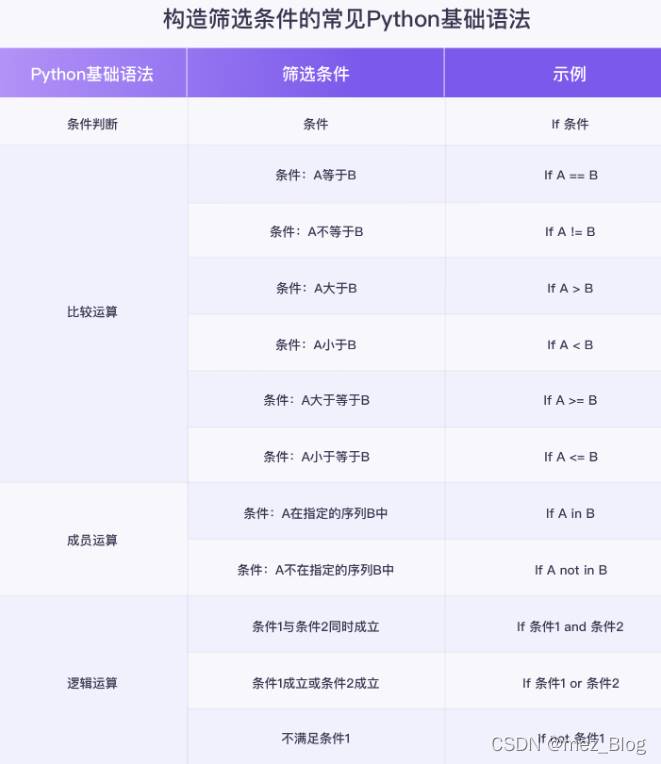
假设我们用time来代表迟到时间,用number代表迟到次数,那么筛选条件就可以写为:if time > 45 and number > 3:
数据输出
完成筛选后,我们需要根据实际需求将筛选结果输出到终端,或将筛选结果保存起来。
本次任务要求我们将筛选后的员工信息打印出来,并且存储到【10月迟到人员信息.xlsx】中。
如果需要获取工作簿中满足某些条件的数据,这种场景就可以被归类为数据筛选场景。
处理该场景时,可以按照获取数据,使用数据和数据输出这三个步骤来处理。
首先是获取数据,使用上节课学习过的表格读写的相关知识,根据任务需求,确定要获取的是零散的单元格,是单行/单列,还是多行/多列的数据。
数据筛选的关键落在了筛选二字上,我们可以在使用数据这一步中实现筛选功能。
在这一步,要仔细理解任务需求,明确筛选条件,然后根据实际情况,选择Python基础语法的相关知识(条件判断语句,比较运算符,成员运算符和逻辑运算符),构造筛选条件。

最后是数据输出部分,根据实际需要输出筛选结果,或将筛选结果保存起来。总结起来可以分为三类:
1)将筛选的结果存入学过的数据结构里,比如:列表,元组或字典。
2)将筛选的结果存入文件中。
3)将筛选的结果打印出来。
案例二:数据匹配
这个案例需要我们匹配两张表格中指定的迟到次数,先来看看案例场景。
现有两张表格,【10月考勤统计.xlsx】中记录了员工十月份的迟到次数数据,这份表格是公司行政手动记录的。
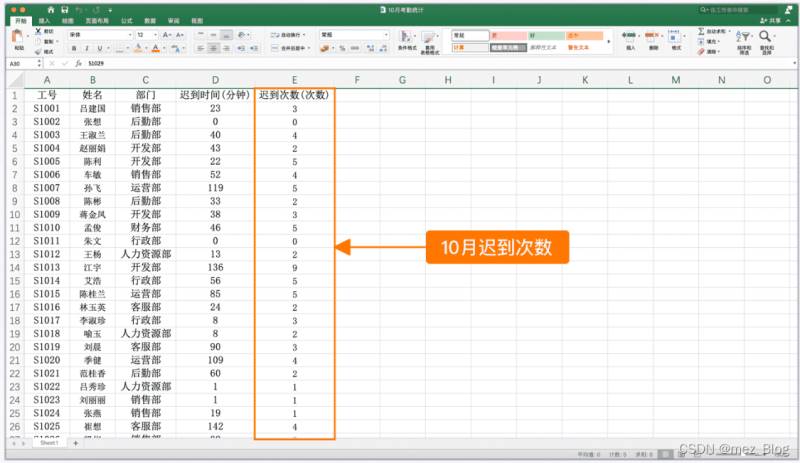
【迟到次数月度统计(10月更新).xlsx】中按月记录了员工每月的迟到次数数据,这份表格是由公司的考勤系统自动生成的。
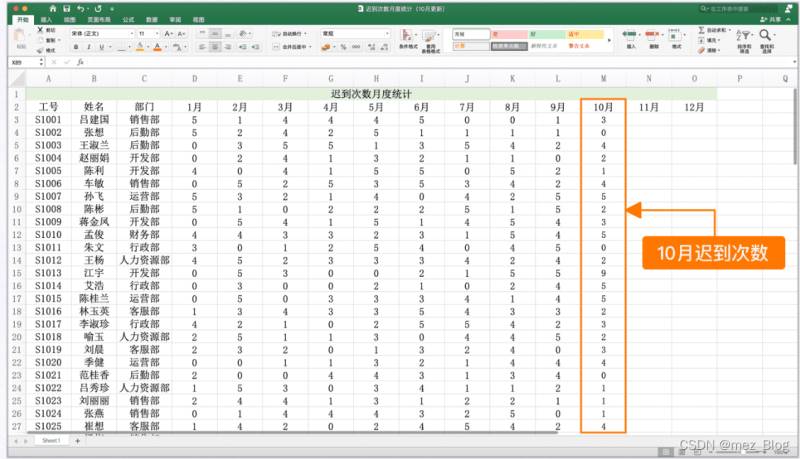
两份表格中的数据可以通过工号一一对应。
现需要核对两张表格中10月迟到次数是否匹配(即两表中相同工号在十月份的迟到次数是否一致),并在终端提醒相关人员去核查不匹配的情况。

代码实现:
from openpyxl import load_workbook
# 打开工作簿【10月考勤统计.xlsx】,获取活动工作表
wb = load_workbook('./material/10月考勤统计.xlsx')
ws = wb.active
# 创建迟到人员字典
info_dict = {}
# 循环读取除表头外的表格数据
for row in ws.iter_rows(min_row=2, values_only=True):
# 取出员工工号
staff_id = row[0]
# 取出迟到次数
staff_late = row[-1]
# 将信息添加入字典,字典格式为{'员工工号': '迟到次数'}
info_dict[staff_id] = staff_late
# 打开工作簿【迟到次数月度统计(10月更新).xlsx】,获取活动工作表
monthly_wb = load_workbook('./material/迟到次数月度统计(10月更新).xlsx')
monthly_ws = monthly_wb.active
# 循环读取出表头外的表格数据
for monthly_row in monthly_ws.iter_rows(min_row=3, max_col=13, values_only=True):
# 取出员工工号
member_id = monthly_row[0]
# 取出十一月份的迟到次数
member_late = monthly_row[-1]
# 匹配迟到次数是否相等
if member_late != info_dict[member_id]:
print('工号{}迟到情况不匹配,请核查后更新'.format(member_id))
运行结果:
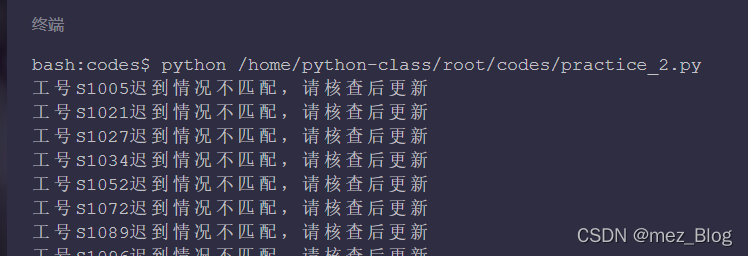
为什么会选择存储到字典中呢?
因为字典可以很好地体现出工号与迟到次数的对应关系,即{'工号': '迟到次数'}。
然后把【迟到次数月度统计(10月更新).xlsx】中的迟到次数,与字典中存储的迟到次数进行匹配,再判断相同工号对应的迟到次数是否相同。
到此这篇关于用Python实现数据筛选与匹配实例的文章就介绍到这了,更多相关Python数据筛选与匹配内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python 列表筛选数据详解
目录 总结 在做数据处理中,常会遇到列表筛选,比如有以下两个列表: 根据上列表中的KEY1 , 筛选下列表的数据,也就是标黄的数据.数量不大的情况,一般就是遍历比较,逻辑简单,几行代码搞掂. 但如果列表达到万,或者百万.千万,那遍历效率就低了. 先构造测试的列表. # 构造筛选目标列表,确保KEY不重复 n1 = 30000 n1_set = set([random.randint(1,n1) for n in range(n1)]) n1 = len(n1_set) list1 = [['11
-
使用python对多个txt文件中的数据进行筛选的方法
一.问题描述 筛选出多个txt文件中需要的数据 二.数据准备 这是我自己建立的要处理的文件,里面是随意写的一些数字和字母 三.程序编写 import os def eachFile(filepath): pathDir =os.listdir(filepath) #遍历文件夹中的text return pathDir def readfile(name): fopen=open(name,'r') for lines in fopen.readlines(): #按行读取text中的内容 lin
-
用Python实现数据筛选与匹配实例
目录 案例一:数据筛选 案例二:数据匹配 下面我们将学习两个项目案例代码,分别解决Excel常见场景中的数据筛选问题和数据匹配问题. 数据筛选要求我们在表中筛选出符合条件的数据.数据匹配需要我们在多个表之间匹配相关的数据. 与之前一样,完成项目问题的代码,需要我们先分析数据筛选和数据匹配的需求,再找到对应知识点,确定代码的执行顺序,从而实现项目代码. 案例一:数据筛选 这个案例需要我们筛选出迟到人员的信息,来具体看看. 在[10月考勤统计.xlsx]工作簿中,保存了公司一百名员工的迟到信息,这些
-
python技能之数据导出excel的实例代码
本文介绍了python技能之导出excel的实例代码,正好能用到,写出来分享给大家 作为一个数据分析师,下面的需求是经常会遇到的. 从数据库或者现有的文本文件中提取符合要求的数据,做一个二次处理,处理完成后的数据最终存储到excel表格中供其他部门的人继续二次分析. 在这里Excel作为一个必不可少桥梁,合适的工具和方法可以避免我们将处理完的数据耗费时间一行行复制黏贴过去. python编程也是一个数据分析师的必备技能,你永远无法预料你的数据会来自哪里,需要经过怎样复杂的过滤,筛选,排序,组合处
-
python 用正则表达式筛选文本信息的实例
本文主要介绍如何对多个文本进行读取,并采用正则表达式对其中的信息进行筛选,将筛选出来的信息存写到一个新文本. 文本基础操作 打开文件:open('文件名','打开方式')>>>file=open(r'C:\Users\yuanlei\Desktop\mytxt.txt','w+').为避免报错,在文件名的引号前加个r. 文件打开方式:只读--r或rt,rb为二进制文件:打开文件前清空文件内容--w或wt:在文末写入--a+: 清空内容然后在文末写入--w+:写到文件任意位置--r+; 关
-
Python 处理数据的实例详解
Python 处理数据的实例详解 最近用python(3.2的版本)写了根据特定规则,处理数据的一个小程序,用到了一些python常用的基础知识,在此总结一下: 1,python读文件 2,python写文件 3,python的流程控制 4,python的for循环 5,python的集合,或字符串里判断是否存在某个元素 6,python的逻辑或,逻辑与 7,python的正则过滤 8,python的字符串忽略空格,和以某个字符串开头和按某个字符拆分成list python的打开文件的模式: 关
-
python 把数据 json格式输出的实例代码
有个要求需要在python的标准输出时候显示json格式数据,如果缩进显示查看数据效果会很好,这里使用json的包会有很多操作 import json date = {u'versions': [{u'status': u'CURRENT', u'id': u'v2.3', u'links': [{u'href': u'http://controller:9292/v2/', u'rel': u'self'}]}, {u'status': u'SUPPORTED', u'id': u'v2.2'
-
python 数据的清理行为实例详解
python 数据的清理行为实例详解 数据清洗主要是指填充缺失数据,消除噪声数据等操作,主要还是通过分析"脏数据"产生的原因和存在形式,利用现有的数据挖掘手段去清洗"脏数据",然后转化为满足数据质量要求或者是应用要求的数据. 1.try 语句还有另外一个可选的子句,它定义了无论在任何情况下都会执行的清理行为. 例如: >>>try: raiseKeyboardInterrupt finally: print('Goodbye, world!') G
-
python导出hive数据表的schema实例代码
本文研究的主要问题是python语言导出hive数据表的schema,分享了实现代码,具体如下. 为了避免运营提出无穷无尽的查询需求,我们决定将有查询价值的数据从mysql导入hive中,让他们使用HUE这个开源工具进行查询.想必他们对表结构不甚了解,还需要为之提供一个表结构说明,于是编写了一个脚本,从hive数据库中将每张表的字段即类型查询出来,代码如下: #coding=utf-8 import pyhs2 from xlwt import * hiveconn = pyhs2.connec
-
pandas系列之DataFrame 行列数据筛选实例
一.对DataFrame的认知 DataFrame的本质是行(index)列(column)索引+多列数据. 为了简化理解,我们不妨换个思路- 现实中,为了简化对一件事物的描述,我们会选择几个特征. 例如,从(性别.身高.学历.职业.爱好..)等角度去刻画一个人,这些"角度"即为"特征". 其中,不同的行表示不同的记录:列代表特征,不同记录因各个特征之间的差异而不同. DataFrame默认索引是序号(0,1,2-),可以理解成位置索引.一般我们用id标识不同记录,
-
python之从文件读取数据到list的实例讲解
背景: 文件内容每一行是由N个单一数字组成的,每个数字之间由制表符区分,比如: 0 4 3 1 2 2 1 0 3 1 2 0 -- 现在需要将每一行数据存为一个list,然后所有行组成一个大的list 工具: 1.strip():用于移除字符串头尾指定的字符,默认为空格,返回是字符串 2.split():通过指定分隔符对字符串进行切片,返回是字符串组成的list 实例: #!/usr/bin/python #coding=utf-8 def readfile(filename): with o
-
python 将数据保存为excel的xls格式(实例讲解)
python提供一个库 xlwt ,可以将一些数据 写入excel表格中,十分的方便.贴使用事例如下. #引入xlwt模块(提前pip下载好) import xlwt #使用workbook方法,创建一个新的工作簿 book = xlwt.Workbook(encoding='utf-8',style_compression=0) #添加一个sheet,名字为mysheet,参数overwrite就是说可不可以重复写入值,就是当单元格已经非空,你还要写入 sheet = book.add_she