Docker容器搭建Kafka集群的详细过程
目录
- 一、Kafka集群的搭建
- 1.拉取相关镜像
- 2.运行zookeeper
- 3.运行kafka
- 4.设置topic
- 5.进行生产者和消费者测试
一、Kafka集群的搭建
1.拉取相关镜像
docker pull wurstmeister/kafka docker pull zookeeper

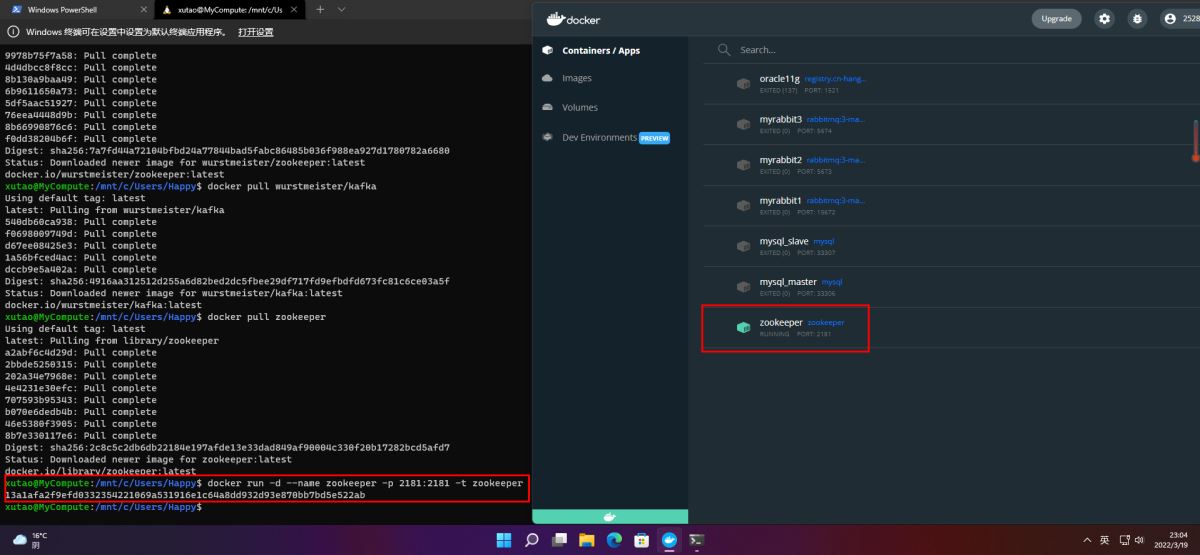
2.运行zookeeper
docker run -d --name zookeeper -p 2181:2181 -t zookeeper
3.运行kafka
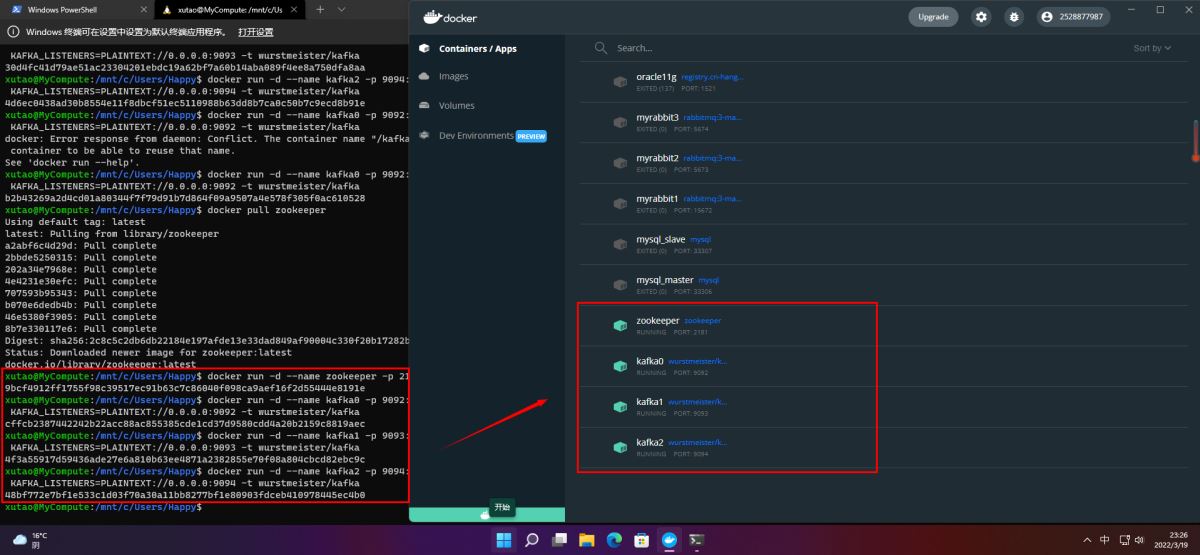
Kafka0:
docker run -d --name kafka0 -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.16.129:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.16.129:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
Kafka1:
docker run -d --name kafka1 -p 9093:9093 -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=192.168.16.129:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.16.129:9093 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 -t wurstmeister/kafka
Kafka2:
docker run -d --name kafka2 -p 9094:9094 -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=192.168.16.129:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.16.129:9094 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9094 -t wurstmeister/kafka
参数说明:
-e KAFKA_BROKER_ID=0在kafka集群中,每个kafka都有一个BROKER_ID来区分自己-e KAFKA_ZOOKEEPER_CONNECT=10.20.8.50:2181/kafka配置zookeeper管理kafka的路径10.20.8.50:2181/kafka-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://10.20.8.50:9092把kafka的地址端口注册给zookeeper,如果是远程访问要改成外网IP。-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092配置kafka的监听端口:这个不能改-v /etc/localtime:/etc/localtime容器时间同步虚拟机的时间
启动3个Kafka节点
4.设置topic
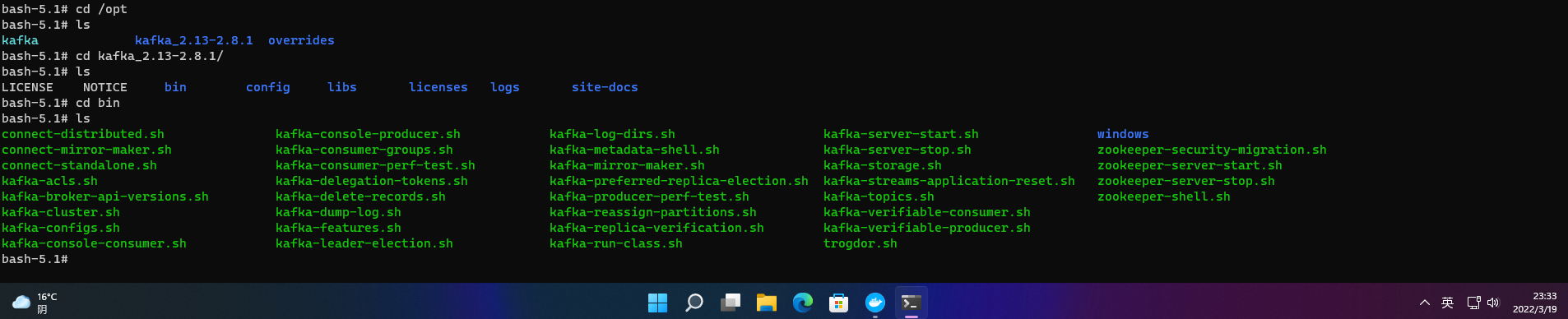
进入kafka0
docker exec -it kafka0 /bin/bash
进入bin目录
cd /opt/kafka_2.13-2.8.1/bin
创建topic
kafka-topics.sh --create --zookeeper 192.168.16.129:2181 --replication-factor 3 --partitions 5 --topic TestTopic
查看topic
kafka-topics.sh --describe --zookeeper 192.168.16.129:2181 --topic TestTopic
Kafka的topic所有分区会分散在不同Broker上,所以该topic的5个分区会被分散到3个Broker上,其中有两个Broker得到两个分区,另一个Broker只有1个分区,如图所示:

集群节点说明:
Topic: TestTopic PartitionCount: 5 ReplicationFactor:3代表TestTopic有5个分区,3个副本节点;Topic: 代表主题名称Leader代表主题节点号,Replicas代表他的副本节点有Broker.id = 2、0、1(包括Leader Replica和Follower Replica,且不管是否存活),Isr表示存活并且同步Leader节点的副本有Broker.id = 2、0、1
5.进行生产者和消费者测试
分别在Broker0上运行一个生产者,Broker1、2上分别运行一个消费者:
kafka-console-producer.sh --broker-list 192.168.16.129:9092 --topic TestTopic kafka-console-consumer.sh --bootstrap-server 192.168.16.129:9093 --topic TestTopic --from-beginning kafka-console-consumer.sh --bootstrap-server 192.168.16.129:9094 --topic TestTopic --from-beginning

到此这篇关于Docker容器 Kafka集群的搭建的文章就介绍到这了,更多相关Docker搭建Kafka集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
docker-compose部署zk+kafka+storm集群的实现
集群部署总览 172.22.12.20 172.22.12.21 172.22.12.22 172.22.12.23 172.22.12.24 zoo1:2181 zoo2:2182 zoo3:2183 zkui:9090 (admin/manager) kafka1:9092 kafka2:9092 kafka3:9092 kafdrop:9000 influxdb:8086 grafana:3000 (admin/chanhu) storm-nimbus1 storm-nimbus2 sto
-
Docker搭建Zookeeper&Kafka集群的实现
最近在学习Kafka,准备测试集群状态的时候感觉无论是开三台虚拟机或者在一台虚拟机开辟三个不同的端口号都太麻烦了(嗯..主要是懒). 环境准备 一台可以上网且有CentOS7虚拟机的电脑 为什么使用虚拟机?因为使用的笔记本,所以每次连接网络IP都会改变,还要总是修改配置文件的,过于繁琐,不方便测试.(通过Docker虚拟网络的方式可以避免此问题,当时实验的时候没有了解到) Docker 安装 如果已经安装Docker请忽略此步骤 Docker支持以下的CentOS版本: CentOS 7 (64
-

Docker容器搭建Kafka集群的详细过程
目录 一.Kafka集群的搭建 1.拉取相关镜像 2.运行zookeeper 3.运行kafka 4.设置topic 5.进行生产者和消费者测试 一.Kafka集群的搭建 1.拉取相关镜像 docker pull wurstmeister/kafka docker pull zookeeper 2.运行zookeeper docker run -d --name zookeeper -p 2181:2181 -t zookeeper 3.运行kafka Kafka0: docker run -d
-
docker搭建kafka集群的方法实现
目录 一.原生Docker命令 二.镜像选择 三.集群规划 四.Zookeeper集群安装 五.Kafka集群安装 一.原生Docker命令 1. 删除所有dangling数据卷(即无用的Volume,僵尸文件) docker volume rm $(docker volume ls -qf dangling=true) 2. 删除所有dangling镜像(即无tag的镜像) docker rmi $(docker images | grep "^<none>" | awk
-
Docker快速搭建Redis集群的方法示例
什么是Redis集群 Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能. 节点 一个Redis集群通常由多个节点(node)组成,在刚开始的时候,每个节点都是相互独立的,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,我们必须将各个独立的节点连接起来,构成一个包含多个节点的集群. 集群配置 配置文件 下载配置文件:https://raw.githubusercontent.com/antirez/redis
-
使用docker compose搭建consul集群环境的例子
consul基本概念 server模式和client模式 server模式和client模式是consul节点的类型:client不是指的用户客户端. server模式提供数据持久化功能. client模式不提供持久化功能,并且实际上他也不工作,只是把用户客户端的请求转发到server模式的节点.所以可以把client模式的节点想象成LB(load balance),只负责请求转发. 通常server模式的节点需要配置成多个例如3个,5个.而client模式节点个数没有限制. server模式启
-
使用docker快速搭建Spark集群的方法教程
前言 Spark 是 Berkeley 开发的分布式计算的框架,相对于 Hadoop 来说,Spark 可以缓存中间结果到内存而提高某些需要迭代的计算场景的效率,目前收到广泛关注.下面来一起看看使用docker快速搭建Spark集群的方法教程. 适用人群 正在使用spark的开发者 正在学习docker或者spark的开发者 准备工作 安装docker (可选)下载java和spark with hadoop Spark集群 Spark运行时架构图 如上图: Spark集群由以下两个部分组成 集
-
docker环境搭建mgr集群的问题及原理
目录 MGR概念 为何选用MGR MGR原理 单主模式 多主模式 环境准备 docker搭建MRG步骤 1.拉取mysql8镜像 2.创建docker专用网络 3.创建存储数据相关目录 4.启动3个mysql容器 4.查看已启动的容器 5.修改配置参数 6.重启3个容器 7.分别登录到各个docker容器,查看下容器的信息 安装MGR插件(3个容器内均执行) 设置数据复制账号(3个容器内均执行) 开启MGR单主模式 1.启动MGR,在主库(172.72.0.15)上执行 2.其他两个节点加入MG
-
使用sealos快速搭建K8s集群环境的过程
目录 一.前言 二.sealos 三.准备环境 sealos 安装 虚拟机设置 网络 windows网络 虚拟机的网络 网卡配置 其他配置 RPM 源 四.安装开始 五.可能遇见的问题 sealos run的时候镜像下载缓慢 六.安装测试 安装Kubernetes Dashboard 一.前言 最近在做谷粒商城项目,搞到k8s了,但是跟这老师的方法一步一步做还是搭建不起来. 我不断的试错啊,各种bug都遇见了一个也没解决我真是啊哭死! 二.sealos 直到遇见一个大佬同学,告诉我sealos几
-
利用MySQL Shell安装部署MGR集群的详细过程
目录 1. 安装准备 2. 利用MySQL Shell构建MGR集群 3. MySQL Shell接管现存的MGR集群 4. 小结 参考资料.文档 免责声明 本文介绍如何利用MySQL Shell + GreatSQL 8.0.25构建一个三节点的MGR集群. MySQL Shell是一个客户端工具,可用于方便管理和操作MySQL,支持SQL.JavaScript.Python等多种语言,也包括完善的API.MySQL Shell支持文档型和关系型数据库模式,通过X DevAPI可以管理文档型数
-
详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验.虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的. 连接服务器 使用 ssh 命令连接远程服务器. ssh root@[Your IP Address] 更新软件列表 apt-get update 更新完成. 安装 Docker sudo apt-get install docker.io 当遇到输入是否继续时,输入「Y/y」继
-
在AWS-EC2中安装Minikube集群的详细过程
目录 一.启动EC2实例(Ubantu) 1.选择实例镜像 2.选择实例类型 3.添加存储(最低10GiB) 4.添加标签(可选) 5.添加安全组(按需求开放端口) 6.核验并启动实例 7.查看实例 二.登录到实例 1.打开SecureCRT 2.导入密钥 3.连接实例 三.安装kubectl(Ubuntu用户非root) 四.安装Docker(ubuntu用户) 五.安装并查看MiniKube 1.安装conntrack(root 用户) 2.安装minikube 六.启动miniKube并检