Python网络爬虫实例讲解
聊一聊Python与网络爬虫。
1、爬虫的定义
爬虫:自动抓取互联网数据的程序。
2、爬虫的主要框架
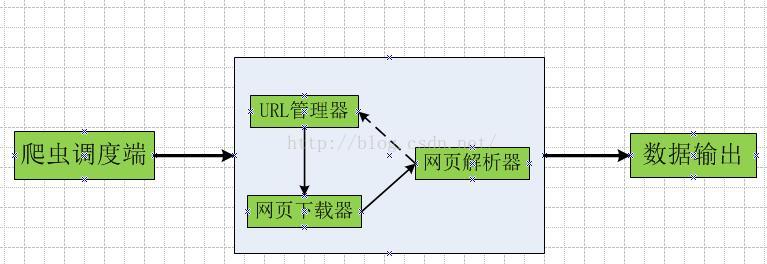
爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出。
3、爬虫的时序图
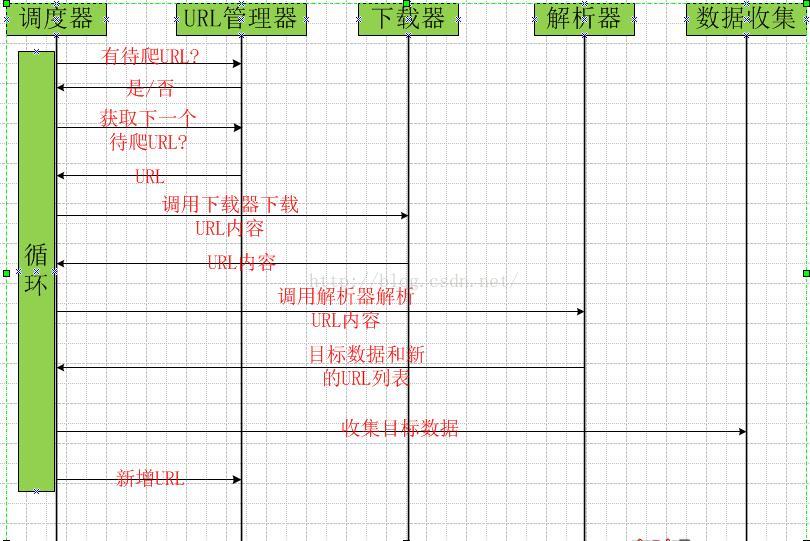
4、URL管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取。URL管理器的主要职能如下图所示:
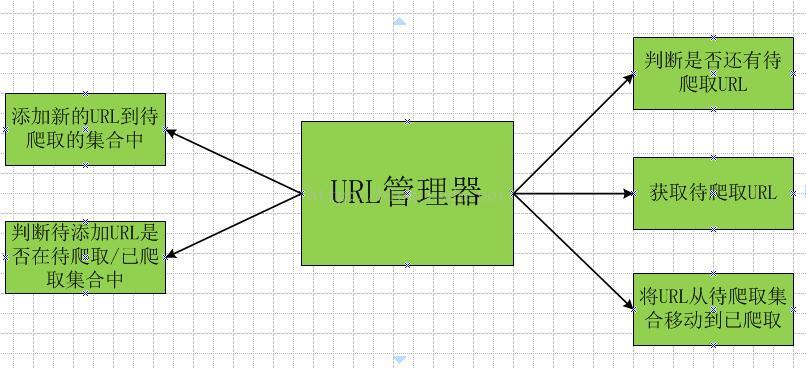
URL管理器在实现方式上,Python中主要采用内存(set)、和关系数据库(MySQL)。对于小型程序,一般在内存中实现,Python内置的set()类型能够自动判断元素是否重复。对于大一点的程序,一般使用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用urllib库,这是python自带的模块。对于2.x版本中的urllib2库,在python3.x中集成到urllib中,在其request等子模块中。urllib中的urlopen函数用于打开url,并获取url数据。urlopen函数的参数可以是url链接,也可以使request对象,对于简单的网页,直接使用url字符串做参数就已足够,但对于复杂的网页,设有防爬虫机制的网页,再使用urlopen函数时,需要添加http header。对于带有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载到的url数据中提取有价值的数据和新的url。对于数据的提取,可以使用正则表达式和BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对于特点比较鲜明的目标数据具有较好的作用,但通用性不高。BeautifulSoup是第三方模块,用于结构化解析url内容。将下载到的网页内容解析为DOM树,下图为使用BeautifulSoup打印抓取到的百度百科中某网页的输出的一部分。

关于BeautifulSoup的具体使用,在以后的文章中再写。下面的代码使用python抓取百度百科中英雄联盟词条中的其他与英雄联盟相关的词条,并将这些词条保存在新建的excel中。上代码:
from bs4 import BeautifulSoup
import re
import xlrd
<span style="font-size:18px;">import xlwt
from urllib.request import urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('league of legend')
## 百度百科:英雄联盟##
html=urlopen("http://baike.baidu.com/subview/3049782/11262116.htm")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
row=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$"))
for link in links:
if 'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
row=row+1
excelFile.save('E:\Project\Python\lol.xls')</span>
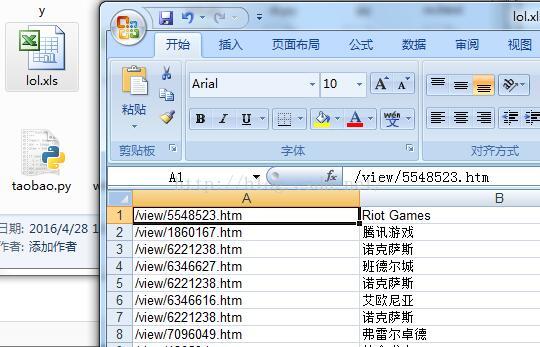
输出的部分截图如下:

excel部分的截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
相关推荐
-

Java实现爬虫给App提供数据(Jsoup 网络爬虫)
一.需求 最近基于 Material Design 重构了自己的新闻 App,数据来源是个问题. 有前人分析了知乎日报.凤凰新闻等 API,根据相应的 URL 可以获取新闻的 JSON 数据.为了锻炼写代码能力,笔者打算爬虫新闻页面,自己获取数据构建 API. 二.效果图 下图是原网站的页面 爬虫获取了数据,展示到 APP 手机端 三.爬虫思路 关于App 的实现过程可以参看这几篇文章,本文主要讲解一下如何爬虫数据. Android下录制App操作生成Gif动态图的全过程 :http://www
-
python3使用urllib模块制作网络爬虫
urllib urllib模块是python3的URL处理包 其中: 1.urllib.request主要是打开和阅读urls 个人平时主要用的1: 打开对应的URL:urllib.request.open(url) 用urllib.request.build_opener([handler, ...]),来伪装成对应的浏览器 import urllib #要伪装成的浏览器(我这个是用的chrome) headers = ('User-Agent','Mozilla/5.0 (Windows N
-
使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎,所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题. Python一直是我主要使用的脚本语言,没有之一.Python的语言简洁灵活,标准库功能强大,平常可以用作计算器,文本编码转换,图片处理,批量下载,批量处理文本等.总之我很喜欢,也越用越上手,这么好用的一个工具,一般人我不告诉他... 因为其强大的字符串处理能力,以及urllib2,cookielib,re,threading这些
-
使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
复制代码 代码如下: #!/usr/bin/env python# -*- coding: utf-8 -*- from scrapy.contrib.spiders import CrawlSpider, Rulefrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom scrapy.selector import Selector from cnbeta.items import CnbetaItemclass
-
教你如何编写简单的网络爬虫
一.网络爬虫的基本知识 网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念.爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的连接看做是有向边.图的遍历方式分为宽度遍历和深度遍历,但是深度遍历可能会在深度上过深的遍历或者陷入黑洞.所以,大多数爬虫不采用这种形式.另一方面,爬虫在按照宽度优先遍历的方式时候,会给待遍历的网页赋予一定优先级,这种叫做带偏好的遍历. 实际的爬虫是从一系列的种子链接开始.种子链接是起始节点,种子页面的超链接指向的页面是
-
python使用rabbitmq实现网络爬虫示例
编写tasks.py 复制代码 代码如下: from celery import Celeryfrom tornado.httpclient import HTTPClientapp = Celery('tasks')app.config_from_object('celeryconfig')@app.taskdef get_html(url): http_client = HTTPClient() try: response = http_client.fetch(u
-
基于Java HttpClient和Htmlparser实现网络爬虫代码
开发环境的搭建,在工程的 Build Path 中导入下载的Commons-httpClient3.1.Jar,htmllexer.jar 以及 htmlparser.jar 文件. 图 1. 开发环境搭建 HttpClient 基本类库使用 HttpClinet 提供了几个类来支持 HTTP 访问.下面我们通过一些示例代码来熟悉和说明这些类的功能和使用. HttpClient 提供的 HTTP 的访问主要是通过 GetMethod 类和 PostMethod 类来实现的,他们分别对应了 HTT
-
网络爬虫案例解析
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常被称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域.搜索引擎使用网络爬虫抓取Web网页.文档甚至图片.音频.视频等资源,通过相应的索引技术组织这些信息,提供给搜索用户进行查询.网络爬虫也为中小站点的推广提供了有效的途径,网站针对搜索引擎爬虫的优化曾风靡一时. 网络爬虫的基本工作流程如下: 1.首先选取一部分精心挑选的种子URL: 2.将这些URL放入待抓取URL队列: 3.从待抓
-
以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
在这篇文章中,我们将分析一个网络爬虫. 网络爬虫是一个扫描网络内容并记录其有用信息的工具.它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,然后对其他网页进行同样的操作. 如果爬虫正在分析的网页中有一些链接,那么爬虫将会根据这些链接分析更多的页面. 搜索引擎就是基于这样的原理实现的. 这篇文章中,我特别选了一个稳定的."年轻"的开源项目pyspider,它是由 binux 编码实现的. 注:据认为pyspider持续监控网络,它假定网页在一
-
Android编写简单的网络爬虫
一.网络爬虫的基本知识 网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念.爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的连接看做是有向边.图的遍历方式分为宽度遍历和深度遍历,但是深度遍历可能会在深度上过深的遍历或者陷入黑洞.所以,大多数爬虫不采用这种形式.另一方面,爬虫在按照宽度优先遍历的方式时候,会给待遍历的网页赋予一定优先级,这种叫做带偏好的遍历. 实际的爬虫是从一系列的种子链接开始.种子链接是起始节点,种子页面的超链接指向的页面是