通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求、异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据。
至于读取静态网页内容的方式,有兴趣的可以查看本文内容。
这里我们以爬取淘宝评论为例子讲解一下如何去做到的。
这里主要分为了四步:
一 获取淘宝评论时,ajax请求链接(url)
二 获取该ajax请求返回的json数据
三 使用python解析json数据
四 保存解析的结果
步骤一:
获取淘宝评论时,ajax请求链接(url)这里我使用的是Chrome浏览器来完成的。打开淘宝链接,在搜索框中搜索一个商品,比如“鞋子”,这里我们选择第一项商品。

然后跳转到了一个新的网页中。在这里由于我们需要爬取用户的评论,所以我们点击累计评价。

然后我们就可以看到用户对该商品的评价了,这时我们在网页中右击选择审查元素(或者直接使用F12打开)并且选中Network选项,如图所示:
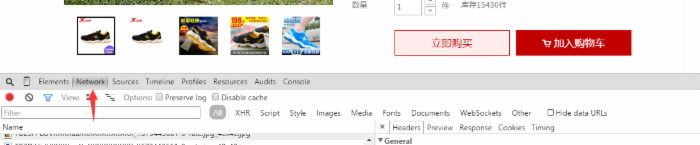
我们在用户评论中,翻到底部 点击下一页或者第二页,我们在Network中看到动态添加了几项,我们选择开头为list_detail_rate.htm?itemId=35648967399的一项。
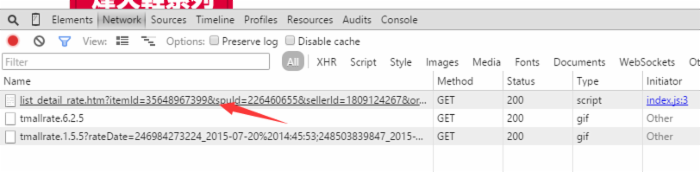
然后点击该选项,我们可以在右边选项框中看到有关该链接的信息,我们要复制Request URL中的链接内容。

我们在浏览器的地址栏中输入刚才我们获得url链接,打开后我们会发现页面返回的是我们所需要的数据,不过显得很乱,因为这是json数据。

二 获取该ajax请求返回的json数据
下一步,我们就要获取url中的json数据了。我所使用的python编辑器是pycharm,下面看一下python代码:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143' #这里的url比较长
content=requests.get(url).content
print content #打印出来的内容就是我们之前在网页中获取到的json数据。包括用户的评论。
这里的content就是我们所需要的json数据,下一步就需要我们解析这些个json数据了。
三 使用python解析json数据
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
import json
import re
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143'
cont=requests.get(url).content
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}')
content=rex.findall(cont)[0]
con=json.loads(content,"gbk")
count=len(con['rateDetail']['rateList'])
for i in xrange(count):
print con['rateDetail']['rateList'][i]['appendComment']['content']

解析:
这里需要导入所要的包,re为正则表达式需要的包,解析json数据需要import json
cont=requests.get(url).content #获取网页中json数据
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}') #正则表达式去除cont数据中多余的部分,是数据成为真正的json格式的数据{“a”:”b”,”c”:”d”}
con=json.loads(content,”gbk”) 使用json的loads函数 将content内容转化为json库函数可以处理的数据格式,”gbk”为数据的编码方式,由于win系统默认为gbk
count=len(con[‘rateDetail'][‘rateList']) #获取用户评论的个数(这里只是当前页的)
for i in xrange(count):
print con[‘rateDetail'][‘rateList'][i][‘appendComment']
#循环遍历用户的评论 并输出(也可以根据需求保存数据,可以查看第四部分)
这里的难点是在杂乱的json数据中查找用户评论的路径
四 保存解析的结果
这里用户可以将用户的评论信息保存到本地,如保存为csv格式。
以上就是本文的全部所述,希望大家喜欢。
相关推荐
-
python实现爬取千万淘宝商品的方法
本文实例讲述了python实现爬取千万淘宝商品的方法.分享给大家供大家参考.具体实现方法如下: import time import leveldb from urllib.parse import quote_plus import re import json import itertools import sys import requests from queue import Queue from threading import Thread URL_BASE = 'http://s
-

python动态网页批量爬取
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页.我使用的是学信网,好了,网站截图如下: 网站的代码如下: <form method="get" name="form1" id="form1" action="/cet/query"> <table border=&qu
-
利用Python爬取微博数据生成词云图片实例代码
前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,七夕送什么才有心意,程序猿可以试试用一种特别的方式来表达你对女神的心意.有一个创意是把她过往发的微博整理后用词云展示出来.本文教你怎么用Python快速创建出有心意词云,即使是Python小白也能分分钟做出来.下面话不多说了,来一起看看详细的介绍吧. 准备工作
-
python 爬取微信文章
本人想搞个采集微信文章的网站,无奈实在从微信本生无法找到入口链接,网上翻看了大量的资料,发现大家的做法总体来说大同小异,都是以搜狗为入口.下文是笔者整理的一份python爬取微信文章的代码,有兴趣的欢迎阅读 #coding:utf-8 author = 'haoning' **#!/usr/bin/env python import time import datetime import requests** import json import sys reload(sys) sys.setd
-
Python实现爬取知乎神回复简单爬虫代码分享
看知乎的时候发现了一个 "如何正确地吐槽" 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了. 工具 1.Python 2.7 2.BeautifulSoup 分析网页 我们先来看看知乎上该网页的情况 网址:,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了. 再来看一下我们要爬取的内容: 我们要爬取两个内容:问题和回答,回答仅限于显示
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
浅谈Python爬取网页的编码处理
背景 中秋的时候,一个朋友给我发了一封邮件,说他在爬链家的时候,发现网页返回的代码都是乱码,让我帮他参谋参谋(中秋加班,真是敬业= =!),其实这个问题我很早就遇到过,之前在爬小说的时候稍微看了一下,不过没当回事,其实这个问题就是对编码的理解不到位导致的. 问题 很普通的一个爬虫代码,代码是这样的: # ecoding=utf-8 import re import requests import sys reload(sys) sys.setdefaultencoding('utf8') url
-
通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求.异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据. 至于读取静态网页内容的方式,有兴趣的可以查看本文内容. 这里我们以爬取淘宝评论为例子讲解一下如何去做到的. 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析json数据
-
实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.firefoxchina.cn/?from=worldindex') True 实例:使用脚本打开一个网页. 所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序.(我没带这行试了试,也可以,可能这是一种规范吧) 1.从sys.argv读取命令行参数:打开一个新的文
-
python爬取各类文档方法归类汇总
HTML文档是互联网上的主要文档类型,但还存在如TXT.WORD.Excel.PDF.csv等多种类型的文档.网络爬虫不仅需要能够抓取HTML中的敏感信息,也需要有抓取其他类型文档的能力.下面简要记录一些个人已知的基于python3的抓取方法,以备查阅. 1.抓取TXT文档 在python3下,常用方法是使用urllib.request.urlopen方法直接获取.之后利用正则表达式等方式进行敏感词检索. ### Reading TXT doc ### from urllib.request i
-
Scrapy基于selenium结合爬取淘宝的实例讲解
在对于淘宝,京东这类网站爬取数据时,通常直接使用发送请求拿回response数据,在解析获取想要的数据时比较难的,因为数据只有在浏览网页的时候才会动态加载,所以要想爬取淘宝京东上的数据,可以使用selenium来进行模拟操作 对于scrapy框架,下载器来说已经没多大用,因为获取的response源码里面没有想要的数据,因为没有加载出来,所以要在请求发给下载中间件的时候直接使用selenium对请求解析,获得完整response直接返回,不经过下载器下载,上代码 from selenium im
-
基于Python爬取京东双十一商品价格曲线
一年一度的双十一就快到了,各种砍价.盖楼.挖现金的口令将在未来一个月内充斥朋友圈.微信群中.玩过多次双十一活动的小编表示一顿操作猛如虎,一看结果2毛5.浪费时间不说而且未必得到真正的优惠,双十一电商的"明降暗升"已经是默认的潜规则了.打破这种规则很简单,可以用 Python 写一个定时监控商品价格的小工具. 思路第一步抓取商品的价格存入 Python 自带的 SQLite 数据库每天定时抓取商品价格使用 pyecharts 模块绘制价格折线图,让低价一目了然 抓取京东价格 从商品详情的
-
python 爬取哔哩哔哩up主信息和投稿视频
项目地址: https://github.com/cgDeepLearn/BilibiliCrawler 项目特点 采取了一定的反反爬策略. Bilibili更改了用户页面的api, 用户抓取解析程序需要重构. 快速开始 拉取项目, git clone https://github.com/cgDeepLearn/BilibiliCrawler.git 进入项目主目录,安装虚拟环境crawlenv(请参考使用说明里的虚拟环境安装). 激活环境并在主目录运行crawl,爬取结果将保存在data目录
-
python爬取气象台每日天气图代码
目录 前言 1.安装Selenium 2. 安装chromedriver 3.代码 前言 中央气象台网站更新后,以前的爬虫方式就不太能用了,我研究了一下发现主要是因为网站上天气图的翻页模式从点击变成了滑动,页面上的图片src也只显示当前页面的,因此,按照网络通俗的方法去爬取就只能爬出一张图片.看了一些大佬的教程后自己改出来一个代码. 1.安装Selenium Selenium是一个Web的自动化(测试)工具,它可以根据我们的指令,让浏览器执行自动加载页面,获取需要的数据等操作. pip inst
-
PHP抓取淘宝商品的用户晒单评论+图片+搜索商品列表实例
说起来做这个功能还真是一时好奇.前段时间在做一个淘客网站的时候,想到是否能抓取到淘宝商品的买家秀呢?经过一番折腾发现,淘宝商品用户评价信息是通过Ajax来调取的,通过嗅探网址发现,评论数据的请求接口是: https://rate.tmall.com/list_detail_rate.htm?itemId=524394294771&spuId=341564036&sellerId=100414600&order=3¤tPage=1&append=0&
-
php curl抓取网页的介绍和推广及使用CURL抓取淘宝页面集成方法
php的curl可以用来实现抓取网页,分析网页数据用, 简洁易用, 这里介绍其函数等就不详细描述, 放上代码看看: 只保留了其中几个主要的函数. 实现模拟登陆, 其中可能涉及到session捕获, 然后前后页面涉及参数提供形式. libcurl主要功能就是用不同的协议连接和沟通不同的服务器~也就是相当封装了的sock PHP 支持libcurl(允许你用不同的协议连接和沟通不同的服务器)., libcurl当前支持http, https, ftp, gopher, telnet, dict, f
-
Python抓取淘宝下拉框关键词的方法
本文实例讲述了Python抓取淘宝下拉框关键词的方法.分享给大家供大家参考.具体如下: import urllib2,re for key in open('key.txt'): do = "http://suggest.taobao.com/sug?code=utf-8&q=%s" % key.rstrip() _re = re.findall('\[\"(.*?)\",\".*?\"\]',urllib2.urlopen(do).re