python获取酷狗音乐top500的下载地址 MP3格式
下面先给大家介绍下python获取酷狗音乐top500的下载地址 MP3格式,具体代码如下所示:
# -*- coding: utf-8 -*-
# @Time : 2018/4/16
# @File : kugou_top500.py
# @Software: PyCharm
# @pyVer : python 2.7
import requests,json
headers={
'UserAgent' : 'Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3',
'Referer' : 'http://m.kugou.com/rank/info/8888',
'Cookie' : 'UM_distinctid=161d629254c6fd-0b48b34076df63-6b1b1279-1fa400-161d629255b64c; kg_mid=cb9402e79b3c2b7d4fc13cbc85423190; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1523818922; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1523819865; Hm_lvt_c0eb0e71efad9184bda4158ff5385e91=1523819798; Hm_lpvt_c0eb0e71efad9184bda4158ff5385e91=1523820047; musicwo17=kugou'
}
def get_songs(url):
res=requests.get(url,headers=headers)
return res.text
def get_song_download_url(url):
res=requests.get(url,headers=headers)
res_tmp_list = json.loads(res.text)
return res_tmp_list['data']['play_url']
def get_song_page_data(url):
Song_Json = json.loads(get_songs(URL))
Song_List_Json = Song_Json['data']['info']
total = []
for i in range(len(Song_List_Json)):
song_download_url = "http://www.kugou.com/yy/index.php?r=play/getdata&hash=%s&album_id=%s&_=1523819864065" % (Song_List_Json[i]['hash'], Song_List_Json[i]['album_id'])
song_data_dict = {'downloadUrl':get_song_download_url(song_download_url),'fileName':Song_List_Json[i]['filename']}
total.append(song_data_dict)
return total
for i in range(1,18):
URL='http://mobilecdngz.kugou.com/api/v3/rank/song?rankid=8888&ranktype=2&page=%s&pagesize=30&volid=&plat=2&version=8955&area_code=1' % i
page_list_data = get_song_page_data(URL)
for j in range(len(page_list_data)):
print "%s %s" % (page_list_data[j]['fileName'],page_list_data[j]['downloadUrl'])
效果

下面看下python--爬取酷狗TOP500的数据
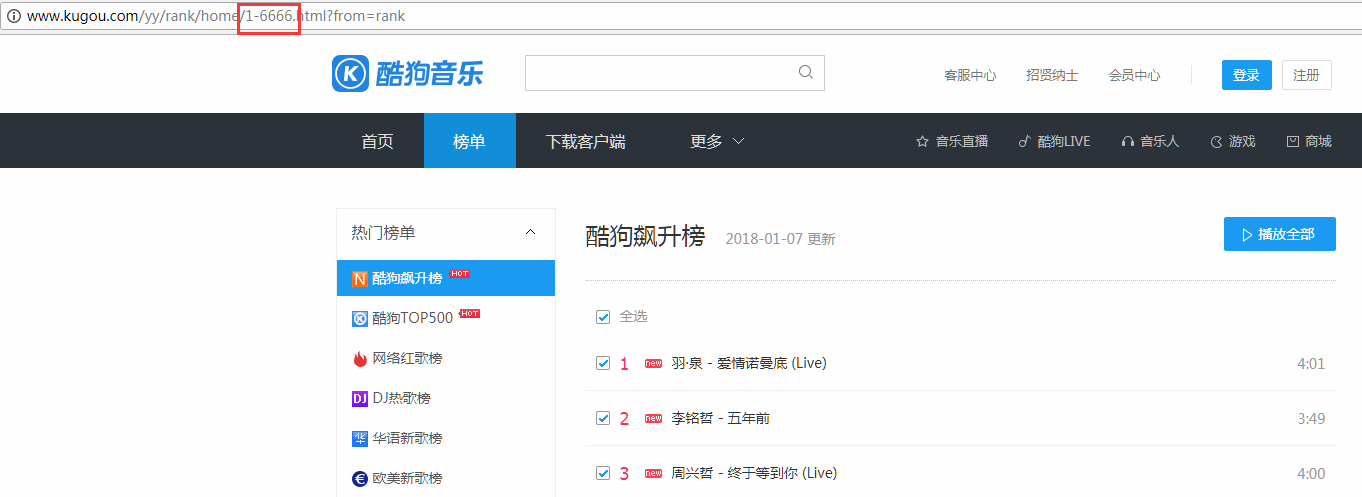
你是不是也遇到不能完整爬取TOP500的数据,因为规律只在前几页有用,后面有小改动,所以中间跳转了,不是完整的TOP500。我换了个方向,爬取飙升榜100首(上面代码)。
希望酷狗给大家个机会哈,毕竟才100首影响不了多大。
from bs4 import BeautifulSoup
import requests
import time
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36'
}
def get_info(url):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data= {
'rank':rank.get_text().strip(),
'siger':title.get_text().split('-')[0],
'song':title.get_text().split('-')[1],
'time':time.get_text().strip()
}
print(data)
#酷狗飙升榜100首
if __name__ == '__main__':
urls = ['http://www.kugou.com/yy/rank/home/{}-6666.html?from=rank/'.format(str(i)) for i in
range(1,6)]
for url in urls:
get_info(url)
time.sleep(2)
总结
以上所述是小编给大家介绍的python获取酷狗音乐top500的下载地址 MP3格,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- 利用Python爬取微博数据生成词云图片实例代码
- python Selenium爬取内容并存储至MySQL数据库的实现代码
- 通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
- python爬取网站数据保存使用的方法
相关推荐
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-

python Selenium爬取内容并存储至MySQL数据库的实现代码
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息.通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的.这篇文章主要讲述通过Selenium爬取我的个人博客信息,然后存储在数据库MySQL中,以便对数据进行分析,比如分析哪个时间段发表的博客多.结合WordCloud分析文章的主题.文章阅读量排名等. 这是一篇基础性的文章,希望对您有所帮助,如果文章中出现错误或不足之处,还请海涵.下一篇文章会简单讲解数据分析的过程. 一. 爬取的结果 爬
-
通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求.异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据. 至于读取静态网页内容的方式,有兴趣的可以查看本文内容. 这里我们以爬取淘宝评论为例子讲解一下如何去做到的. 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析json数据
-
利用Python爬取微博数据生成词云图片实例代码
前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,七夕送什么才有心意,程序猿可以试试用一种特别的方式来表达你对女神的心意.有一个创意是把她过往发的微博整理后用词云展示出来.本文教你怎么用Python快速创建出有心意词云,即使是Python小白也能分分钟做出来.下面话不多说了,来一起看看详细的介绍吧. 准备工作
-
python获取酷狗音乐top500的下载地址 MP3格式
下面先给大家介绍下python获取酷狗音乐top500的下载地址 MP3格式,具体代码如下所示: # -*- coding: utf-8 -*- # @Time : 2018/4/16 # @File : kugou_top500.py # @Software: PyCharm # @pyVer : python 2.7 import requests,json headers={ 'UserAgent' : 'Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 lik
-
python爬取酷狗音乐Top500榜单
目录 网页情况 python 代码 运行效果 总结 网页情况 爬取数据包含 歌曲排名.歌手.歌曲名.歌曲时长 python 代码 import requests #请求网页获取网页数据 from bs4 import BeautifulSoup #解析网页数据 import time #时间库 #user-Agent,伪装成浏览器,便于爬虫的稳定性 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64;
-
Python反爬实战掌握酷狗音乐排行榜加密规则
目录 效果展示 爬取目标 工具使用 项目思路解析 简易源码分享 效果展示 爬取目标 网址:酷我音乐 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,re 项目思路解析 找到需要解析的榜单数据 随意点击一个歌曲获取到音乐的详情数据 通过抓包的方式获取到音乐播放数据 找到MP3的数据提交地址 mp3数据来自于这个url地址 提交数据的网址: https://wwwapi.kugou.com/yy/index.php?r=play/
-
python使用beautifulsoup4爬取酷狗音乐代码实例
这篇文章主要介绍了python使用beautifulsoup4爬取酷狗音乐代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, 安装方法:pip install beautifulsoup4 完整代码如下:双击就能直接运行 from bs4 import BeautifulSoup
-
Python爬虫实战项目掌握酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. 我们在搜索栏上输入我们想听的音乐,小编输入:刺客 是不是看到了一系列音乐,怎样得到这些音乐的一些信息呢?(这里指的音乐信息是指音乐的hash值和音乐的album_id值[这两个参数在获取音乐的下载链接那里会用到],当然还包括音乐的名称[不然怎么区别呢?]). 由于这一系列音乐是动态加载出来的,也就是
-
python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下 #coding=utf-8 from pymongo import MongoClient import time import requests from lxml import etree client = MongoClient() #连接mongo hello = client.hello #连接数据库 user = hello.song #连接表 headers = { 'User-Agent': 'M
-
Java swing仿酷狗音乐播放器
今天给大家介绍下用Java swing开发一款音乐播放器,高仿酷狗音乐播放器,完整源码地址在最下方,本文只列出部分源码,因为源码很多,全部贴不下,下面还是老规矩.来看看运行结果: 下面我们来看看代码: 首先看一下主窗口的实现代码: package com.baiting; import java.awt.Dimension; import java.awt.Toolkit; import com.baiting.menu.CloseWindow; /** * 窗口 * @author lmq *
-
JS模拟酷狗音乐播放器收缩折叠关闭效果代码
本文实例讲述了JS模拟酷狗音乐播放器收缩折叠关闭效果代码.分享给大家供大家参考,具体如下: 这是一款模拟酷狗音乐播放器的关闭特效,采用JavaScript实现,关闭的时候播放界面缩成一条线,然后消失,就像有些电视机突然停电的效果,很有意思的网页动画特效. 运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/js-kugou-music-player-style-demo/ 具体代码如下: <!DOCTYPE html PUBLIC "-//W3
-
java实现酷狗音乐临时缓存文件转换为MP3文件的方法
本文实例讲述了java实现酷狗音乐临时缓存文件转换为MP3文件的方法.分享给大家供大家参考,具体如下: 酷狗临时缓存文件,其实已经是吧MP3文件下载好了,只是名字看上去好像是通过md5算法重命名的. 酷狗在缓存文件的时候会同时缓存歌词.这个程序就是根据md5管理对应的歌词文件和缓存文件,然后把缓存文件改成 歌曲名+.mp3格式. 原谅我取这么长也不知道对不对的类名. package com.zhou.run; import java.io.File; import java.util.HashM
-
Vue 全家桶实现移动端酷狗音乐功能
Vue 已经用了不少时间,最近抽空把以前的未完成的酷狗音乐做完了,过来分享下,也可以直接点这里预览,注意切换成手机模式. 技术栈: vue-router.eventBus.vuex.vue-awesome-swiper 整体功能 vs 酷狗官网: 总体模拟官网,原来的亮点保留,如: 图片懒加载 除此之外,增加了 加了全局的 Loading 组件,根据不同页面调整 Loading 尺寸 搜索页面做了优化,可以在刷新时保留之前的搜索结果 播放页面单独做了一个路由,可以在刷新时保留当前歌曲页面 播放器