python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下
1、概述
决策树(decision tree)——是一种被广泛使用的分类算法。
相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置
在实际应用中,对于探测式的知识发现,决策树更加适用。
2、算法思想
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。
实质:通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见
假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑

上图完整表达了这个女孩决定是否见一个约会对象的策略,其中:
◊绿色节点表示判断条件
◊橙色节点表示决策结果
◊箭头表示在一个判断条件在不同情况下的决策路径
图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
决策树分类算法的关键就是根据“先验数据”构造一棵最佳的决策树,用以预测未知数据的类别
决策树:是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
3、决策树构造
假如有以下判断苹果好坏的数据样本:
样本 红 大 好苹果
0 1 1 1
1 1 0 1
2 0 1 0
3 0 0 0
样本中有2个属性,A0表示是否红苹果。A1表示是否大苹果。假如要根据这个数据样本构建一棵自动判断苹果好坏的决策树。
由于本例中的数据只有2个属性,因此,我们可以穷举所有可能构造出来的决策树,就2棵,如下图所示:
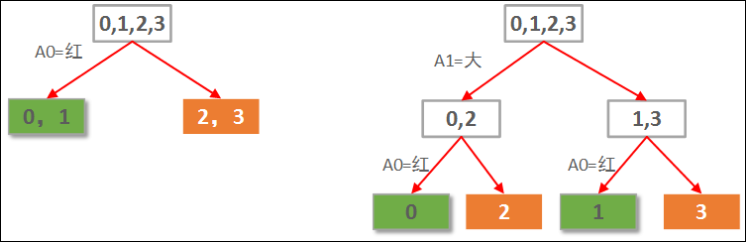
显然左边先使用A0(红色)做划分依据的决策树要优于右边用A1(大小)做划分依据的决策树。
当然这是直觉的认知。而直觉显然不适合转化成程序的实现,所以需要有一种定量的考察来评价这两棵树的性能好坏。
决策树的评价所用的定量考察方法为计算每种划分情况的信息熵增益:
如果经过某个选定的属性进行数据划分后的信息熵下降最多,则这个划分属性是最优选择
属性划分选择(即构造决策树)的依据:
简单来说,熵就是“无序,混乱”的程度。
通过计算来理解:
1、原始样本数据的熵:
样例总数:4
好苹果:2
坏苹果:2
熵: -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1
信息熵为1表示当前处于最混乱,最无序的状态。
2、两颗决策树的划分结果熵增益计算
树1先选A0作划分,各子节点信息熵计算如下:
0,1叶子节点有2个正例,0个负例。信息熵为:e1 = -(2/2 * log(2/2) + 0/2 * log(0/2)) = 0。
2,3叶子节点有0个正例,2个负例。信息熵为:e2 = -(0/2 * log(0/2) + 2/2 * log(2/2)) = 0。
因此选择A0划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 0。
选择A0做划分的信息熵增益G(S, A0)=S - E = 1 - 0 = 1.
事实上,决策树叶子节点表示已经都属于相同类别,因此信息熵一定为0。
树2先选A1作划分,各子节点信息熵计算如下:
0,2子节点有1个正例,1个负例。信息熵为:e1 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
1,3子节点有1个正例,1个负例。信息熵为:e2 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
因此选择A1划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 1。也就是说分了跟没分一样!
选择A1做划分的信息熵增益G(S, A1)=S - E = 1 - 1 = 0.
因此,每次划分之前,我们只需要计算出信息熵增益最大的那种划分即可。
先做A0划分时的信息熵增益为1>先做A1划分时的信息熵增益,所以先做A0划分是最优选择!!!
4、算法指导思想
经过决策属性的划分后,数据的无序度越来越低,也就是信息熵越来越小
5、算法实现
梳理出数据中的属性
比较按照某特定属性划分后的数据的信息熵增益,选择信息熵增益最大的那个属性作为第一划分依据,然后继续选择第二属性,以此类推
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python sklearn KFold 生成交叉验证数据集的方法
源起: 1.我要做交叉验证,需要每个训练集和测试集都保持相同的样本分布比例,直接用sklearn提供的KFold并不能满足这个需求. 2.将生成的交叉验证数据集保存成CSV文件,而不是直接用sklearn训练分类模型. 3.在编码过程中有一的误区需要注意: 这个sklearn官方给出的文档 >>> import numpy as np >>> from sklearn.model_selection import KFold >>> X = [&quo
-
Python KNN分类算法学习
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本"距离"最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类.简单的说就是让最相似的K个样本来投票决定. 这里所说的距
-
对python sklearn one-hot编码详解
one-hot编码的作用 使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点 将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间. sklearn的一个例子 from sklearn import preprocessing enc = preprocessing.One
-
Python使用sklearn实现的各种回归算法示例
本文实例讲述了Python使用sklearn实现的各种回归算法.分享给大家供大家参考,具体如下: 使用sklearn做各种回归 基本回归:线性.决策树.SVM.KNN 集成方法:随机森林.Adaboost.GradientBoosting.Bagging.ExtraTrees 1. 数据准备 为了实验用,我自己写了一个二元函数,y=0.5*np.sin(x1)+ 0.5*np.cos(x2)+0.1*x1+3.其中x1的取值范围是0~50,x2的取值范围是-10~10,x1和x2的训练集一共有5
-

python利用sklearn包编写决策树源代码
本文实例为大家分享了python编写决策树源代码,供大家参考,具体内容如下 因为最近实习的需要,所以用python里的sklearn包重新写了一次决策树. 工具:sklearn,将dot文件转化为pdf格式(是为了将形成的决策树可视化)graphviz-2.38,下载解压之后将其中的bin文件的目录添加进环境变量 源代码如下: from sklearn.feature_extraction import DictVectorizer import csv from sklearn import
-
Python基于sklearn库的分类算法简单应用示例
本文实例讲述了Python基于sklearn库的分类算法简单应用.分享给大家供大家参考,具体如下: scikit-learn已经包含在Anaconda中.也可以在官方下载源码包进行安装.本文代码里封装了如下机器学习算法,我们修改数据加载函数,即可一键测试: # coding=gbk ''' Created on 2016年6月4日 @author: bryan ''' import time from sklearn import metrics import pickle as pickle
-
python sklearn库实现简单逻辑回归的实例代码
Sklearn简介 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression).降维(Dimensionality Reduction).分类(Classfication).聚类(Clustering)等方法.当我们面临机器学习问题时,便可根据下图来选择相应的方法. Sklearn具有以下特点: 简单高效的数据挖掘和数据分析工具 让每个人能够在复杂环境中重复使用 建立NumPy.Scipy.MatPlotLib之上 代
-
Python使用sklearn库实现的各种分类算法简单应用小结
本文实例讲述了Python使用sklearn库实现的各种分类算法简单应用.分享给大家供大家参考,具体如下: KNN from sklearn.neighbors import KNeighborsClassifier import numpy as np def KNN(X,y,XX):#X,y 分别为训练数据集的数据和标签,XX为测试数据 model = KNeighborsClassifier(n_neighbors=10)#默认为5 model.fit(X,y) predicted = m
-
Python3.5 + sklearn利用SVM自动识别字母验证码方法示例
前言 最近正在研究人工智能,为了加深对算法的理解,决定写个自动设别验证码的程序.看了看网上的demo,大部分都是python2的写法,而且验证码的识别都是用的数字做例子,那我就写个基于python3字母识别的程序,不过一路写下来碰到不少坑,大家感兴趣的话可以慢慢看. 图片识别有几个比较大的步骤是必须完成的: 1.有大量的验证码图片作为样本 2.图片要进行处理 流程是:灰度化==>二值化==>字符切割==>识别分类 3.图像识别要提取特征值,然后把图片二值化的数据当做样本做训练,最后基于
-
朴素贝叶斯分类算法原理与Python实现与使用方法案例
本文实例讲述了朴素贝叶斯分类算法原理与Python实现与使用方法.分享给大家供大家参考,具体如下: 朴素贝叶斯分类算法 1.朴素贝叶斯分类算法原理 1.1.概述 贝叶斯分类算法是一大类分类算法的总称 贝叶斯分类算法以样本可能属于某类的概率来作为分类依据 朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一种 注:朴素的意思是条件概率独立性 P(A|x1x2x3x4)=p(A|x1)*p(A|x2)p(A|x3)p(A|x4)则为条件概率独立 P(xy|z)=p(xyz)/p(z)=p(xz)/p(z)
-
Python决策树分类算法学习
从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树算法 决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归.不过对于一些特殊的逻辑分类会有困难.典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题. 决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题.因此如何构建一棵好的决策树是研究的重点. J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法.后续的C4.5,
-
对sklearn的使用之数据集的拆分与训练详解(python3.6)
研修课上讲了两个例子,融合一下. 主要演示大致的过程: 导入->拆分->训练->模型报告 以及几个重要问题: ①标签二值化 ②网格搜索法调参 ③k折交叉验证 ④增加噪声特征(之前涉及) from sklearn import datasets #从cross_validation导入会出现warning,说已弃用 from sklearn.model_selection import train-test_split from sklearn.grid_search import Gri