python深度优先搜索和广度优先搜索
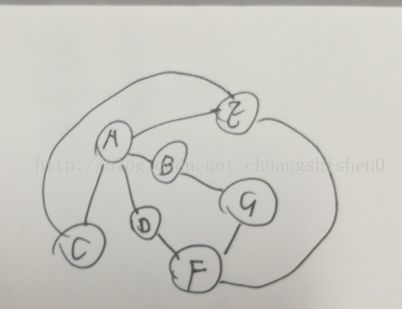
1. 深度优先搜索介绍
图的深度优先搜索(Depth First Search),和树的先序遍历比较类似。
它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
显然,深度优先搜索是一个递归的过程。
2. 广度优先搜索介绍
广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索",简称BFS。
它的思想是:从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远,依次访问和v有路径相通且路径长度为1,2...的顶点。
# -*- coding: utf-8 -*-
"""
Created on Wed Sep 27 00:41:25 2017
@author: my
"""
from collections import OrderedDict
class graph:
nodes=OrderedDict({})#有序字典
def toString(self):
for key in self.nodes:
print key+'邻接点为'+str(self.nodes[key].adj)
def add(self,data,adj,tag):
n=Node(data,adj)
self.nodes[tag]=n
for vTag in n.adj:
if self.nodes.has_key(vTag) and tag not in self.nodes[vTag].adj:
self.nodes[vTag].adj.append(tag)
visited=[]
def dfs(self,v):
if v not in self.visited:
self.visited.append(v)
print v
for adjTag in self.nodes[v].adj:
self.dfs(adjTag)
visited2=[]
def bfs(self,v):
queue=[]
queue.insert(0,v)
self.visited2.append(v)
while(len(queue)!=0):
top=queue[len(queue)-1]
for temp in self.nodes[top].adj:
if temp not in self.visited2:
self.visited2.append(temp)
queue.insert(0,temp)
print top
queue.pop()
class Node:
data=0
adj=[]
def __init__(self,data,adj):
self.data=data
self.adj=adj
g=graph()
g.add(0,['e','c'],'a')
g.add(0,['a','g'],'b')
g.add(0,['a','e'],'c')
g.add(0,['a','f'],'d')
g.add(0,['a','c','f'],'e')
g.add(0,['d','g','e'],'f')
g.add(0,['b','f'],'g')
g.toString()
print '深度优先遍历的结构为'
g.dfs('c')
print '广度优先遍历的结构为'
g.bfs('c')
相关推荐
-
Python深度优先算法生成迷宫
本文实例为大家分享了Python深度优先算法生成迷宫,供大家参考,具体内容如下 import random #warning: x and y confusing sx = 10 sy = 10 dfs = [[0 for col in range(sx)] for row in range(sy)] maze = [[' ' for col in range(2*sx+1)] for row in range(2*sy+1)] #1:up 2:down 3:left 4:right opera
-
python图的深度优先和广度优先算法实例分析
本文实例讲述了python图的深度优先和广度优先算法.分享给大家供大家参考,具体如下: 首先有一个概念:回溯 回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标.但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为"回溯点". 深度优先算法: (1)访问初始顶点v并标记顶点v已访问. (2)查找顶点v的第一个邻接顶点w. (3)若顶点v的邻接顶点w存在,则继续执行:否则回溯到v,
-
python实现广度优先搜索过程解析
广度优先搜索 适用范围: 无权重的图,与深度优先搜索相比,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快 复杂度: 时间复杂度为O(V+E),V为顶点数,E为边数 思路 广度优先搜索是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜索: 代码 from collections import deque #解决从你的人际关系网中找到芒果销售商的问题 #使用字典表示映射关系 graph = {} graph["you"] = ["alice&quo
-

python广度优先搜索得到两点间最短路径
前言 之前一直写不出来,这周周日花了一下午终于弄懂了, 顺便放博客里,方便以后忘记了再看看. 要实现的是输入一张 图,起点,终点,输出起点和终点之间的最短路径. 广度优先搜索 适用范围: 无权重的图,与深度优先搜索相比,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快 复杂度: 时间复杂度为O(V+E),V为顶点数,E为边数 思路 广度优先搜索是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜索: 比如下图: 从0结点开始搜索的话,一开始是0.将0加入队列中: 然后
-
Python数据结构与算法之图的广度优先与深度优先搜索算法示例
本文实例讲述了Python数据结构与算法之图的广度优先与深度优先搜索算法.分享给大家供大家参考,具体如下: 根据维基百科的伪代码实现: 广度优先BFS: 使用队列,集合 标记初始结点已被发现,放入队列 每次循环从队列弹出一个结点 将该节点的所有相连结点放入队列,并标记已被发现 通过队列,将迷宫路口所有的门打开,从一个门进去继续打开里面的门,然后返回前一个门处 """ procedure BFS(G,v) is let Q be a queue Q.enqueue(v) lab
-
python数据结构之图深度优先和广度优先实例详解
本文实例讲述了python数据结构之图深度优先和广度优先用法.分享给大家供大家参考.具体如下: 首先有一个概念:回溯 回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标.但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为"回溯点". 深度优先算法: (1)访问初始顶点v并标记顶点v已访问. (2)查找顶点v的第一个邻接顶点w. (3)若顶点v的邻接顶点w存在,则继续执行:否则回
-
10分钟教你用python动画演示深度优先算法搜寻逃出迷宫的路径
深度优先算法(DFS 算法)是什么? 寻找起始节点与目标节点之间路径的算法,常用于搜索逃出迷宫的路径.主要思想是,从入口开始,依次搜寻周围可能的节点坐标,但不会重复经过同一个节点,且不能通过障碍节点.如果走到某个节点发现无路可走,那么就会回退到上一个节点,重新选择其他路径.直到找到出口,或者退到起点再也无路可走,游戏结束.当然,深度优先算法,只要查找到一条行得通的路径,就会停止搜索:也就是说只要有路可走,深度优先算法就不会回退到上一步. 如果你依然在编程的世界里迷茫,可以加入我们的Python学
-
python实现树的深度优先遍历与广度优先遍历详解
本文实例讲述了python实现树的深度优先遍历与广度优先遍历.分享给大家供大家参考,具体如下: 广度优先(层次遍历) 从树的root开始,从上到下从左到右遍历整个树的节点 数和二叉树的区别就是,二叉树只有左右两个节点 广度优先 顺序:A - B - C - D - E - F - G - H - I 代码实现 def breadth_travel(self, root): """利用队列实现树的层次遍历""" if root == None: r
-
python 递归深度优先搜索与广度优先搜索算法模拟实现
一.递归原理小案例分析 (1)# 概述 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! (2)# 写递归的过程 1.写出临界条件 2.找出这一次和上一次关系 3.假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果 (3)案例分析:求1+2+3+...+n的数和 # 概述 ''' 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! ''' # 写递归的过程 ''' 1.写出临界条件 2.找出这一次和上一次关系 3.假设
-
Java编程实现基于图的深度优先搜索和广度优先搜索完整代码
为了解15puzzle问题,了解了一下深度优先搜索和广度优先搜索.先来讨论一下深度优先搜索(DFS),深度优先的目的就是优先搜索距离起始顶点最远的那些路径,而广度优先搜索则是先搜索距离起始顶点最近的那些路径.我想着深度优先搜索和回溯有什么区别呢?百度一下,说回溯是深搜的一种,区别在于回溯不保留搜索树.那么广度优先搜索(BFS)呢?它有哪些应用呢?答:最短路径,分酒问题,八数码问题等.言归正传,这里笔者用java简单实现了一下广搜和深搜.其中深搜是用图+栈实现的,广搜使用图+队列实现的,代码如下:
-
python深度优先搜索和广度优先搜索
1. 深度优先搜索介绍 图的深度优先搜索(Depth First Search),和树的先序遍历比较类似. 它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到. 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止. 显然,深度优先搜索是一个递归的过程. 2. 广度优先搜索介绍 广度优先搜索算法(Breadt
-
C++实现广度优先搜索实例
本文主要叙述了图的遍历算法中的广度优先搜索(Breadth-First-Search)算法,是非常经典的算法,可供C++程序员参考借鉴之用.具体如下: 首先,图的遍历是指从图中的某一个顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点访问一次且仅访问一次.注意到树是一种特殊的图,所以树的遍历实际上也可以看作是一种特殊的图的遍历.图的遍历主要有两种算法:广度优先搜索(Breadth-First-Search)和深度优先搜索(Depth-First-Search). 一.广度优先搜索(BFS)的
-
Python学习之MRO方法搜索顺序
目录 为什么会讲 MRO? 什么是 MRO 注意 MRO 算法 什么是旧式类,新式类 想深入了解 C3 算法的可以看看官网 旧式类 MRO 算法 新式类 MRO 算法 新式 MRO 算法的问题 什么是单调性原则? C3 MRO 算法 简单了解下 C3 算法 merge 的运算方式 简单类 MRO 的计算栗子 单继承MRO 的计算栗子 多继承MRO 的计算栗子 多继承MRO 的计算栗子二 为什么会讲 MRO? 在讲多继承的时候,有讲到, 当继承的多个父类拥有同名属性.方法,子类对象调用该属性.方法
-
C++回溯算法广度优先搜索举例分析
目录 迷宫问题 N叉树的层序遍历 腐烂的橘子 单词接龙 打开转盘锁 迷宫问题 假设有一个迷宫,里面有障碍物,迷宫用二维矩阵表示,标记为0的地方表示可以通过,标记为1的地方表示障碍物,不能通过.现在给一个迷宫出口,让你判断是否可以从入口进来之后,走出迷宫,每次可以向任意方向走. 代码实现: namespace BFS { struct pair { int _x; int _y; pair(int x, int y) :_x(x) , _y(y) {} }; bool mapBFS(vector<
-
Python实现提取谷歌音乐搜索结果的方法
本文实例讲述了Python实现提取谷歌音乐搜索结果的方法.分享给大家供大家参考.具体如下: Python的简单脚本,用于提取谷歌音乐搜索页面中的歌曲信息,包括歌曲名,作者,专辑名,现在链接等,最多只提取10页结果. #! /usr/bin/env python #coding=utf-8 ''' Created on 2011-8-19 @author: yaoboyuan ''' from urllib import request,parse import re,sys def extrac
-
python仿evething的文件搜索器实例代码
今天看到everything搜索速度秒杀windows自带的文件管理器,所以特地模仿everything实现了文件搜索以及打开对应文件的功能,首先来一张搜索对比图. 这是evething搜索效果: 这是自己实现的效果: 主要功能就是python的os库的文件列表功能,sqllite创建表,插入数据以及模糊搜索,然后就是tkiner实现的界面功能.全部代码贴出来做一次记录,花费一天时间踩坑. # coding=utf-8 import tkinter as tk import tkinter.me